Все уже прекрасно понимают, что Amplicode — неотъемлемая часть тулинга для разработки в OpenIDE, IntelliJ IDEA Community Edition и GigaIDE на Spring Boot. Но стоит установить Amplicode в IntelliJ IDEA Ultimate и ваша, казалось бы, идеальная IDE станет ещё мощнее и удобнее.
Пользователи Ultimate выбирают лучшее из лучшего. Если вы работаете в Ultimate, значит, привыкли к топовым инструментам, которые экономят время и делают разработку приятнее. Amplicode органично дополняет этот набор: он добавляет в IDE то, чего всегда не хватало — быструю работу с данными, автоматизацию рутины и готовые решения для Spring-разработки.
Amplicode особенно любим у пользователей Ultimate именно потому, что продолжает эту философию: никаких компромиссов — только максимум возможностей и комфорта. Хотите оставаться среди тех, кто работает с самыми сильными инструментами? Amplicode — ваш must-have.
Статья получилась объёмной, но мы решили не дробить её на части. Потратив 30 минут на чтение, вы сэкономите часы в будущем.
Помните про принцип «малых шагов» — регулярные небольшие улучшения дают большой результат на дистанции. Экономьте по несколько минут каждый день — к концу недели это уже несколько часов.
Слева — оглавление для удобства. Возвращайтесь к статье и делитесь с коллегами, когда видите, что кто-то снова выполняет рутинную работу вручную, вместо того чтобы доверить её инструментам.
Создание Spring-приложения
Начнем с базы — создания Spring Boot-проекта. Кажется, как часто разработчики создают проекты с нуля? Но именно это первое, что мы ожидаем от IDE и идем проверять.
В IntelliJ IDEA Ultimate есть функциональность создания проекта, интегрированная со
start.spring.io
. Давайте воспользуемся ею и создадим проект с типовыми компонентами: Spring Data JPA, Spring Web, Spring Security.
Даже если что-то забыли, не проблема — добавим позже через функцию Add starters....
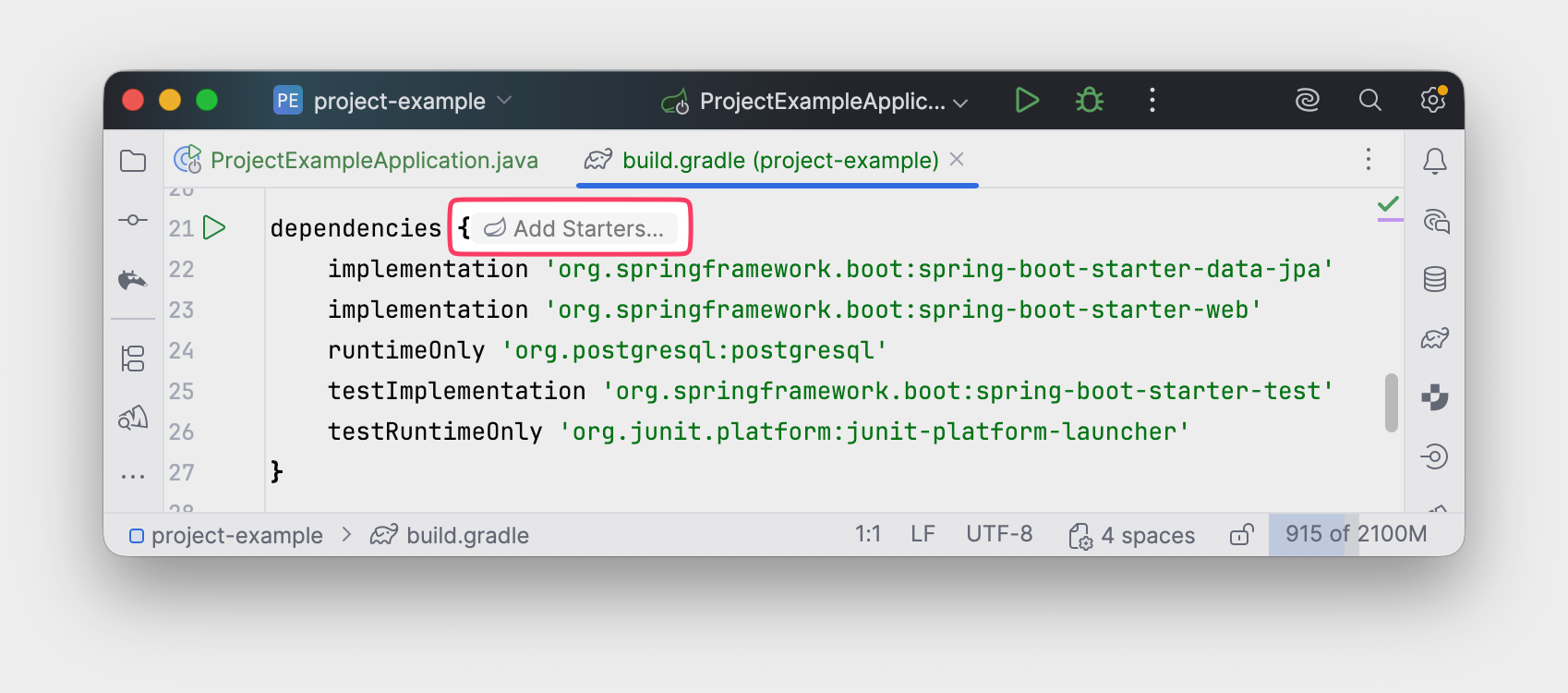
Что получаем на выходе? Рабочее приложение (нет). Конечно, это только стартовая точка. Впереди — бизнес-логика, работа с данными, REST API, Kafka-очереди или другие механизмы. Но уже сейчас можно нажать Run и увидеть, что приложение запускается. Ну почти...
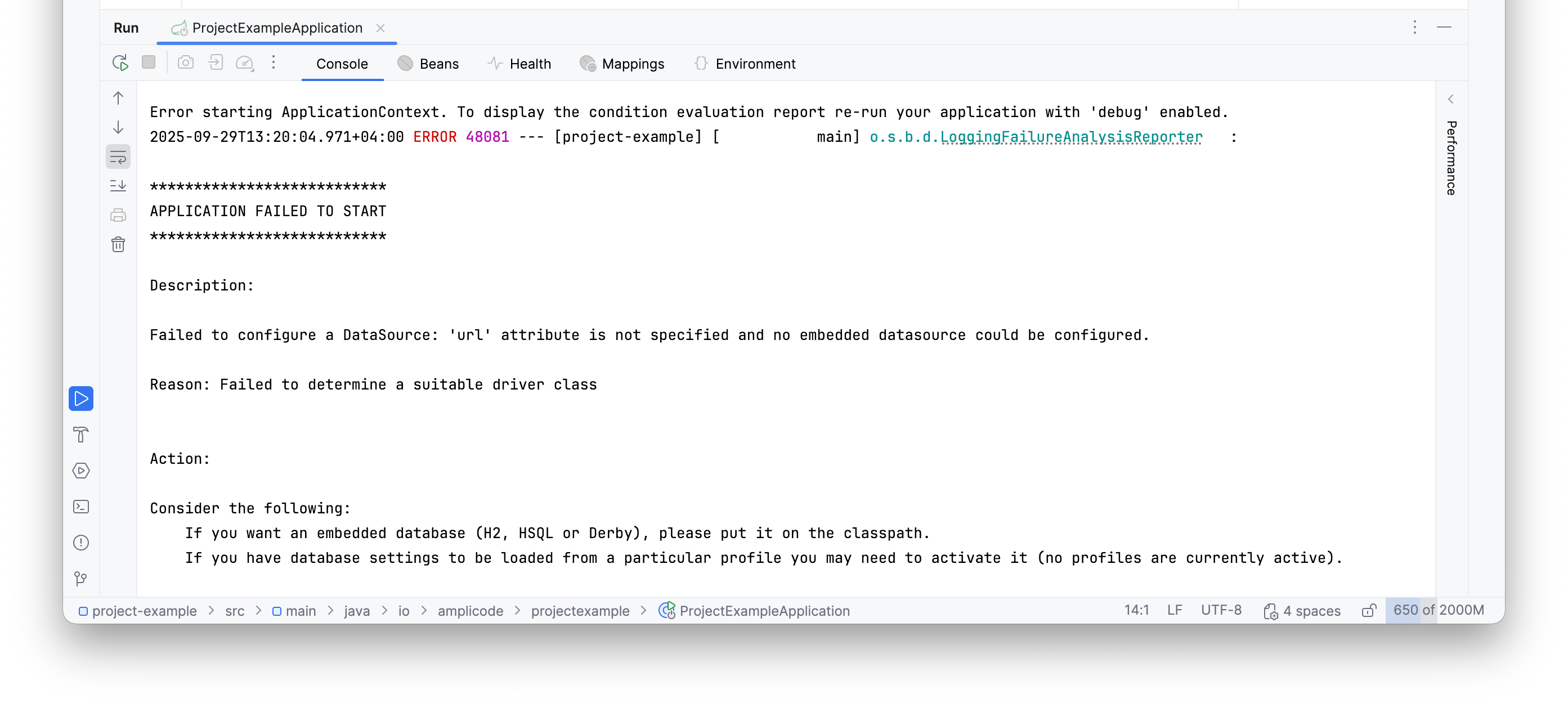
Появится ошибка: не сконфигурирован DataSource. Кажется странным, но вспомните в процессе создания приложения — нас никто не спрашивал о названии базы данных, хосте, логине и пароле. Не беда — давайте доконфигурируем.
Настройка DataSource
Открываем
application.properties
. Осталось совсем немного: вспомнить названия свойств для настройки DataSource и структуру
jdbcUrl
. Удобно, что IDE знакома с Spring Properties и подсказывает их, помогая избежать опечаток. Важно не забыть указать правильный драйвер для БД.
Кажется, ничего нового — так мы делали всегда. Но можно ли иначе?
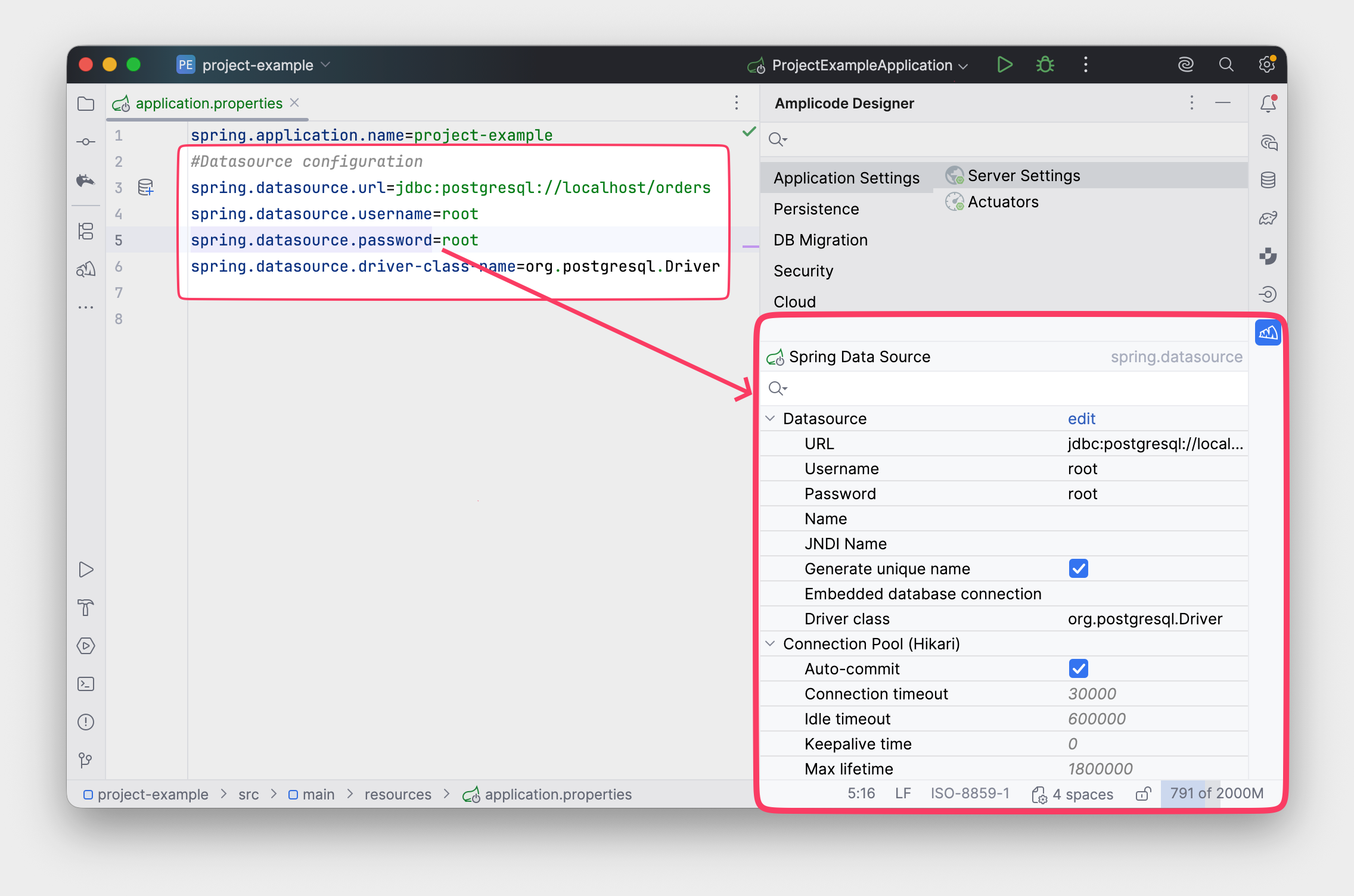
Amplicode предлагает удобную функциональность работы с DataSource. С его помощью можно сконфигурировать как основной, так и дополнительные DataSource.
В результате Amplicode не только добавил свойства для настройки DataSource, но и зависимость на драйвер PostgreSQL (или драйвер для другой СУБД):
spring.datasource.url=jdbc:postgresql://localhost/orders
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=org.postgresql.Driver
runtimeOnly 'org.postgresql:postgresql'
Если зависимость уже есть, Amplicode, конечно же, не будет её дублировать.
Что насчет остальных параметров DataSource? Размер пула подключений,
connection timeout
? Чтобы это узнать, обычно нужно найти имя свойства и перейти в соответствующий класс
Properties
прямо из IDE, а затем посмотреть, чему равны значения. Но можно проще.
В Amplicode есть Amplicode Inspector. Достаточно поставить курсор на DataSource и взглянуть на нижнюю часть панели, мы часто называем её Amplicode Inspector — и вы увидите все актуальные свойства, их значения, а также значения по умолчанию, если они не заданы.
Пробуем запустить приложение снова. На этот раз оно падает по вполне ожидаемой причине: мы настроили DataSource для подключения к локальному PostgreSQL, но окружение не подготовили. Исправляем это — для локального окружения используем Docker Compose.
Docker Compose для локального окружения
Начнем с создания файла. Docker Compose использует формат YAML, значит нам нужен файл с расширением
.yml
или
.yaml
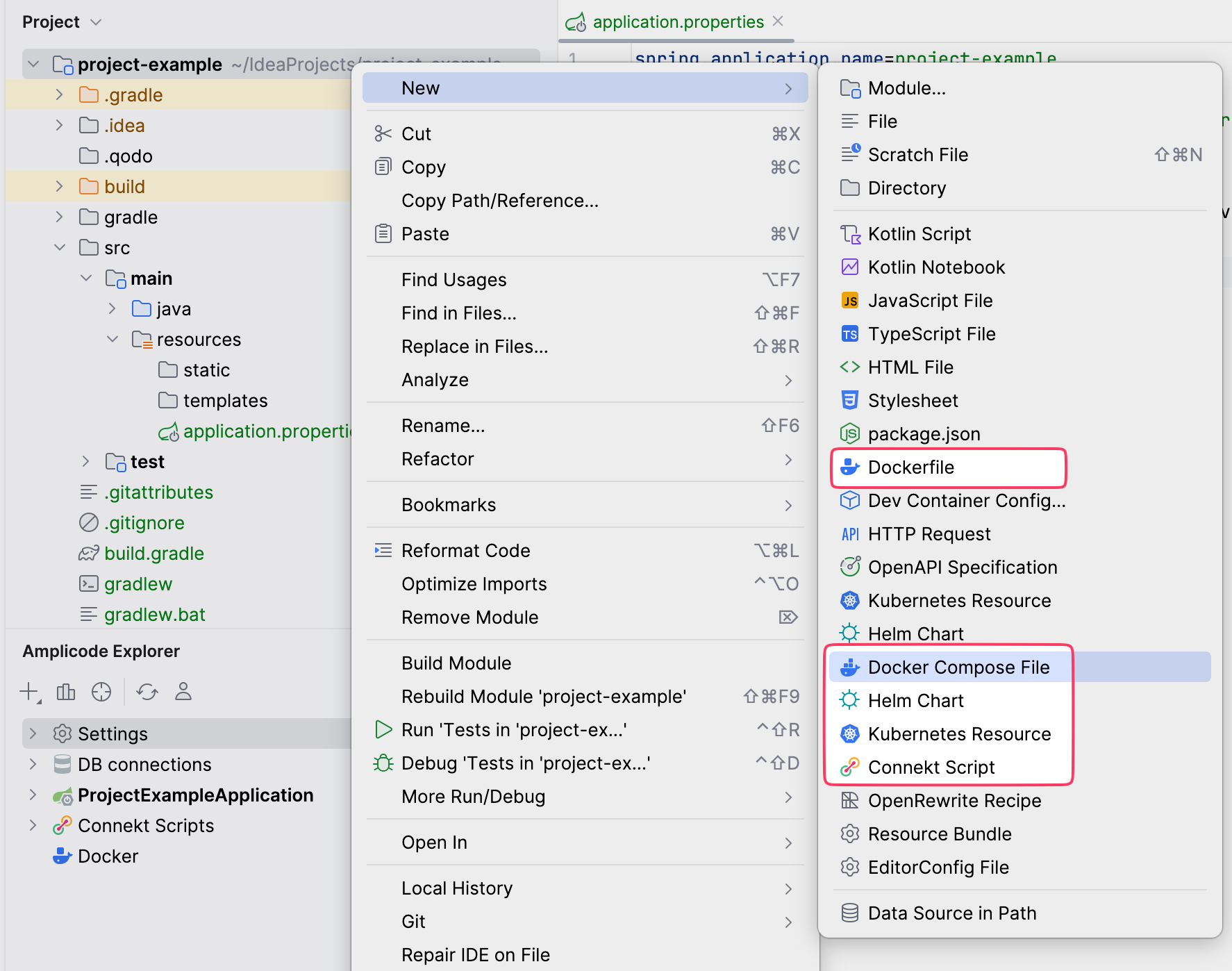
. Создать его можно через New...
Но давайте остановимся на секунду. Как часто мы создаем файлы в IDE?
На самом деле — не так часто. Чаще мы создаем классы, интерфейсы, репозитории, сервисы, контроллеры. Для нас это уже рутина. IntelliJ IDEA, как и любой продукт, вынуждена расставлять приоритеты: поддерживать одни технологии в ущерб другим. Amplicode помогает закрыть эти пробелы.
Например, в меню New... вы найдете пункт для создания Docker Compose-файла. Помимо этого, Amplicode позволяет создавать репозитории, сервисы, контроллеры, CRUD-контроллеры, event-листенеры, Helm-чарты и многое другое. Мелочь, а приятно.
Теперь нужно добавить для нашего DataSource сервис PostgreSQL. JetBrains тоже стараются помочь — IntelliJ IDEA предлагает комплишены для YAML, но поскольку общедоступного формата описания опций конфигурации docker-образов не существует (есть только Dockerfile), подсказки носят общий характер.
Этого недостаточно. Чтобы правильно сконфигурировать PostgreSQL, нужно знать:
- версию образа,
- имя базы данных, пользователя и пароль,
- где смонтировать volume,
- как настроить healthcheck.
Почти все это можно узнать только из документации. Поэтому в Amplicode мы добавили функциональность для работы с сервисами в Docker Compose.
Поддержка каждого нового сервиса требует экспертной работы, поэтому список ограничен самыми популярными, но постоянно пополняется. Список поддерживаемых сервисов можно посмотреть в Amplicode Designer.
Добавляем сервис — в нашем случае PostgreSQL. В открывшемся диалоге можно его доконфигурировать, например выбрать, для какого DataSource мы его создаем.
Если нужно изменить уже существующий сервис или уточнить параметры сгенерированной конфигурации, не обязательно генерировать его заново — достаточно открыть Amplicode Inspector и внести нужные изменения.
Теперь можно запустить сервис. Сначала запускаем Docker Compose через Run... в IDE (кстати, в IntelliJ IDEA отличный Docker-клиент), затем запускаем приложение тем же способом.
Обзор и навигация по проекту
Мы создали проект, настроили его, написали бизнес-логику. Наступили выходные — самое время отдохнуть. В понедельник открываем проект и пытаемся восстановить контекст. Начинаем вспоминать...
Смотрим структуру файлов, проверяем зависимости в
build.gradle
или
pom.xml
, вспоминаем сущности, REST-эндпоинты, подключенные Kafka-топики. После этого запускаем Docker Compose и приложение.
А теперь оглянемся: сколько файлов пришлось открыть, чтобы «вспомнить всё»? Не один десяток. И это не разовая история — каждый день, по нескольку раз, мы задаем себе вопросы:
- как связаны сущности?
- есть ли нужный эндпоинт?
- в каком он контроллере?
Каждый раз это поиск и переход в конкретный файл.
Зачем вообще нужны файлы в IntelliJ IDEA Ultimate, если список endpoints есть в панели Endpoints, а сущности — в панели Persistence?
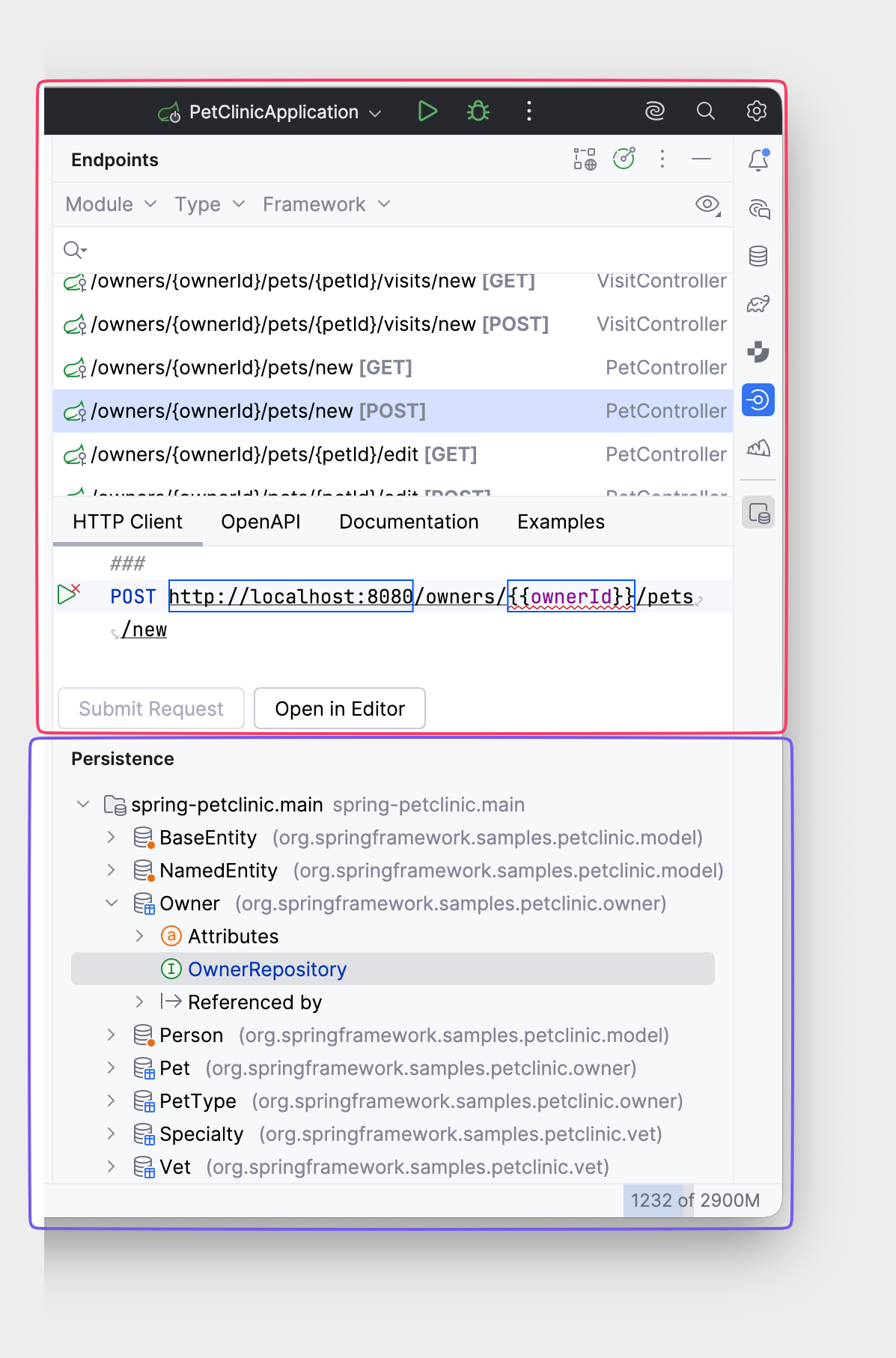
Все верно, но проблема в другом: Spring Boot-приложение — это система связанных компонентов. Их нужно воспринимать именно так, а не как набор отдельных файлов. Тем более, что приложение на Spring Data JPA + Spring MVC отличается от приложения на Spring Data JDBC или MyBatis.
Именно здесь помогает Amplicode Explorer. В любой момент вы можете открыть его и быстро восстановить недостающий контекст.
Работа с данными в приложении
Движемся дальше. Сложно представить приложение, которое не работает с данными. Есть мнение, что современный бэкенд-разработчик в основном «гоняет» данные между JSON/Protobuf/... и БД. Поэтому в IntelliJ IDEA есть отличные инструменты для работы с данными.
Начнем с хорошо знакомого DB-клиента. Этот инструмент невероятно мощный: он позволяет работать с очень большими таблицами, размер которых ограничен лишь объемом вашей ОЗУ. Он настолько хорош, что некоторые пользователи покупали Ultimate только ради него. Позже JetBrains вынесли его в отдельный продукт и продолжают активно развивать.
Большинство из нас хорошо с ним знакомо. Вот лишь малая часть возможностей:
- просмотр структуры БД (таблицы, колонки, индексы, внешние ключи),
- изменение структуры таблиц и связей,
- редактирование данных в реляционных, колоночных и NoSQL-базах,
- копирование, экспорт, выполнение запросов и многое другое.
За полным списком лучше обратиться к документации.
А что с самим приложением? Обычно оно работает с данными через Spring Data JPA/JDBC/MongoDB/Redis и т.д. Давайте разберемся по порядку.
Моделирование сущностей (JPA/JDBC/MongoDB)
Сущность — ключевой термин в Spring Data:
- в JPA это
@Entity, - в JDBC —
@Table, - в MongoDB —
@Document.
Каждый из фреймворков не только описывает сущности, но и дает средства связывать их между собой.
- В JPA для этого есть аннотации
@OneToMany,@ManyToOne,@ManyToMany. - В JDBC для описания агрегата используют
@MappedCollection, а для связи агрегатов —AggregateReference.
Для начала посмотрим, как создавать сущности.
Например, в JPA это Java/Kotlin-класс с аннотациями
@Entity
,
@Table
и обязательным полем с
@Id
. На многих проектах принято добавлять
@Table
, хотя по спецификации это не обязательно.
Создаем сущность через New.... Вроде все просто — IDE умеет создавать классы. Но можно лучше. Amplicode позволяет создавать ключевые объекты поддерживаемых фреймворков напрямую: New... → JPA Entity, указываем тип идентификатора — и на выходе готовая сущность.
Amplicode может не только создавать объекты «с нуля», но и использовать готовые. Например, если уже есть БД, можно сгенерировать JPA Entity на основе таблицы — достаточно настроить подключение в IDE.
Если вы используете Spec First-подход, можно создать сущность на основе DTO.
Осталось добавить атрибуты. Тут все по классике: указываем тип, имя поля, при необходимости добавляем
@Column
. Для простых типов, например String, этого достаточно. Но есть типы, для которых нужно указывать дополнительные параметры.
Например, у
BigDecimal
важно задать
precision
и
scale
, иначе на реальных данных можно получить неприятные баги.
Amplicode помогает с этим:
- позволяет быстро создавать атрибуты с базовыми типами (
String,Integer,Long,BigDecimal), - корректно генерирует связи между сущностями (
@OneToMany,@ManyToOne,@ManyToMany), - предупреждает об особенностях работы коллекций в JPA.
Следуя этим рекомендациям, можно избежать проблем с производительностью и дублированием элементов. Вопросу корректной реализации
equals()
и
hashCode()
для JPA-сущностей мы даже посвятили отдельную статью.
Методы Spring Data репозиториев и поддержка кастомных @Query
После создания сущностей нужно реализовать операции над ними: поиск по id, фильтрация по атрибутам, создание, изменение, удаление. В Spring Data это принято делать через репозитории.
Spring Data предоставляет несколько инструментов: derived method, query method, custom repository — обычно именно в таком порядке их и применяют.
Предположим, у нас есть сущность
Vet
с атрибутами: фамилия, имя, дата рождения и связью один-ко-многим с сущностью
Specialty
(если вы знакомы с типовым проектом Spring «PetClinic», то модель вам знакома).
Поиск по ID
Начнем с простого — поиска ветеринара по id. Для этого создаем репозиторий, унаследовав его от нужного родителя, например
JpaRepository
. Amplicode позволяет сделать это быстро — так же, как и с другими объектами. Созданный репозиторий «из коробки» содержит множество полезных методов, включая
findById
.
Derived-методы
Следующая задача — поиск ветеринара по части фамилии, без учета регистра.
Открываем интерфейс репозитория и начинаем набирать
findAllBy...
. IDE подсказывает возможные варианты. Нужно вспомнить:
- какое условие использовать для поля
фамилия— до или после имени поля, - как задать игнорирование регистра.
После пары попыток метод будет готов.
Но с Amplicode это можно сделать быстрее.
Вызываем контекстное меню Generate или открываем Amplicode Designer →
Repository derived method -> Find Collection
. В окне выбора указываем атрибут, выбираем условие Contains, ставим галочку IgnoreCase и жмем OK. Amplicode создаст метод в нужном виде. Создавать derived-методы становится действительно удобно, так как нет необходимости держать в голове всю модель данных.
@Query-методы
Так же легко можно создать метод с
@Query
. В контекстном меню или в Amplicode Designer выбираем
Repository Query method
, задаем атрибуты и условия, Amplicode сгенерирует метод с JPQL-запросом.
Если нужно, можно доработать запрос вручную — в IntelliJ IDEA Ultimate есть отличная поддержка JPQL.
Кроме того, Derived-метод можно конвертировать в Query-метод. Для этого вызываем действия IDE над методом и выбираем
Extract JPQL query
. Amplicode добавит аннотацию
@Query
с запросом и предложит переименовать метод.
Entity Graph
Еще один полезный инструмент — Entity Graph. Он нужен, если требуется загрузить дерево связанных сущностей одним запросом. Например, при поиске ветеринара по id нам нужны не только данные ветеринара, но и его специальности. Создадим метод:
Optional<Vet> findWithSpecialityById(Long id);
Теперь определим граф для загрузки специальностей. Снова встает вопрос: писать руками или воспользоваться инструментом? Amplicode упрощает задачу.
Ставим курсор на метод → вызываем быстрые действия → Define an entity graph.
Выбираем сущности, указываем тип графа (load/fetch), жмем OK. Amplicode добавит аннотацию:
@EntityGraph(attributePaths = {"specialities"})
Optional<Vet> findWithSpecialityById(Integer id);
Версионирование БД (Liquibase/Flyway)
После того как мы определили сущности и добавили методы репозиториев, перед запуском приложения нужно создать таблицы в базе данных.
Есть несколько способов:
- создать таблицы вручную через DB Client в IDE,
- воспользоваться стратегиями
create/create-only/create-dropиз Hibernate, - использовать инструменты версионирования БД — Liquibase или Flyway.
Первые два варианта подходят только на ранних этапах проекта. Позже разработчики неизбежно переходят к полноценному версионированию схемы БД.
Мы будем использовать Flyway. Конечно, можно просто отредактировать стартеры через IDE, но, как я уже писал в разделе про DataSource, это требует дополнительной настройки. А вот если добавить Flyway-конфигурацию через Amplicode, можно сразу приступить к написанию скриптов.
В Amplicode Explorer вызываем контекстное меню на элементе Configurations → Add Configuration → DB Migration Configuration. В открывшемся окне выбираем Flyway (Amplicode поддерживает и Liquibase), указываем место хранения скриптов и активируем опцию "Create init db scripts". Это удобно, так как на момент подключения механизма версионирования у нас обычно уже есть модель или готовые таблицы. В нашем случае это модель, поэтому выбираем ее и указываем тип БД — PostgreSQL. Жмем OK.
Amplicode добавит зависимости, настройки в
application.properties
и сгенерирует скрипты инициализации схемы для пустой БД. Остается только сделать ревью сгенерированных скриптов — вы удивитесь, насколько точно Amplicode интерпретирует описание JPA (или JDBC) модели. Теперь при запуске на пустой БД приложение выполнит эти скрипты и создаст все нужные объекты.
Разработка бизнес-логики
После настройки скриптов версионирования можно перейти к написанию бизнес-логики. Решим классическую задачу для ветеринарной клиники — поиск подходящего ветеринара для будущего визита.
Как обычно, начнем с создания сервиса, который будет содержать бизнес-логику.
Мы хотим разделять декларацию и реализацию, поэтому создаем два объекта: интерфейс сервиса и класс реализации. Конечно, можно сделать это вручную в IDE, но проще воспользоваться Amplicode.
В контекстном меню New... выбираем Service/Component. В открывшемся окне ставим галочку
Autowire by interface
и нажимаем
+
, чтобы добавить интерфейс с именем
VetScheduleService
(пусть именно этот сервис отвечает за поиск свободного ветеринара). Amplicode заполнит имя класса реализации автоматически. Если реализация должна работать только в определенном профиле, можно указать его сразу. Жмем OK — Amplicode создаст и интерфейс, и класс реализации.
В интерфейсе сервиса добавляем метод
findAppropriateVet
. В качестве контекста используем владельца, питомца и информацию о визите. Поскольку в дальнейшем мы хотим создавать визит для выбранного ветеринара и питомца, сразу определяем сущность визита, включающую дату, описание визита и ссылки на питомца и ветеринара (в обоих случаях связь многие-к-одному).
Однако использовать сущность визита в качестве параметра метода пока нельзя — визита еще не существует. Поэтому последним параметром определяем несуществующий класс
VisitAppropriateDto
. Ничего необычного — приступаем к реализации.
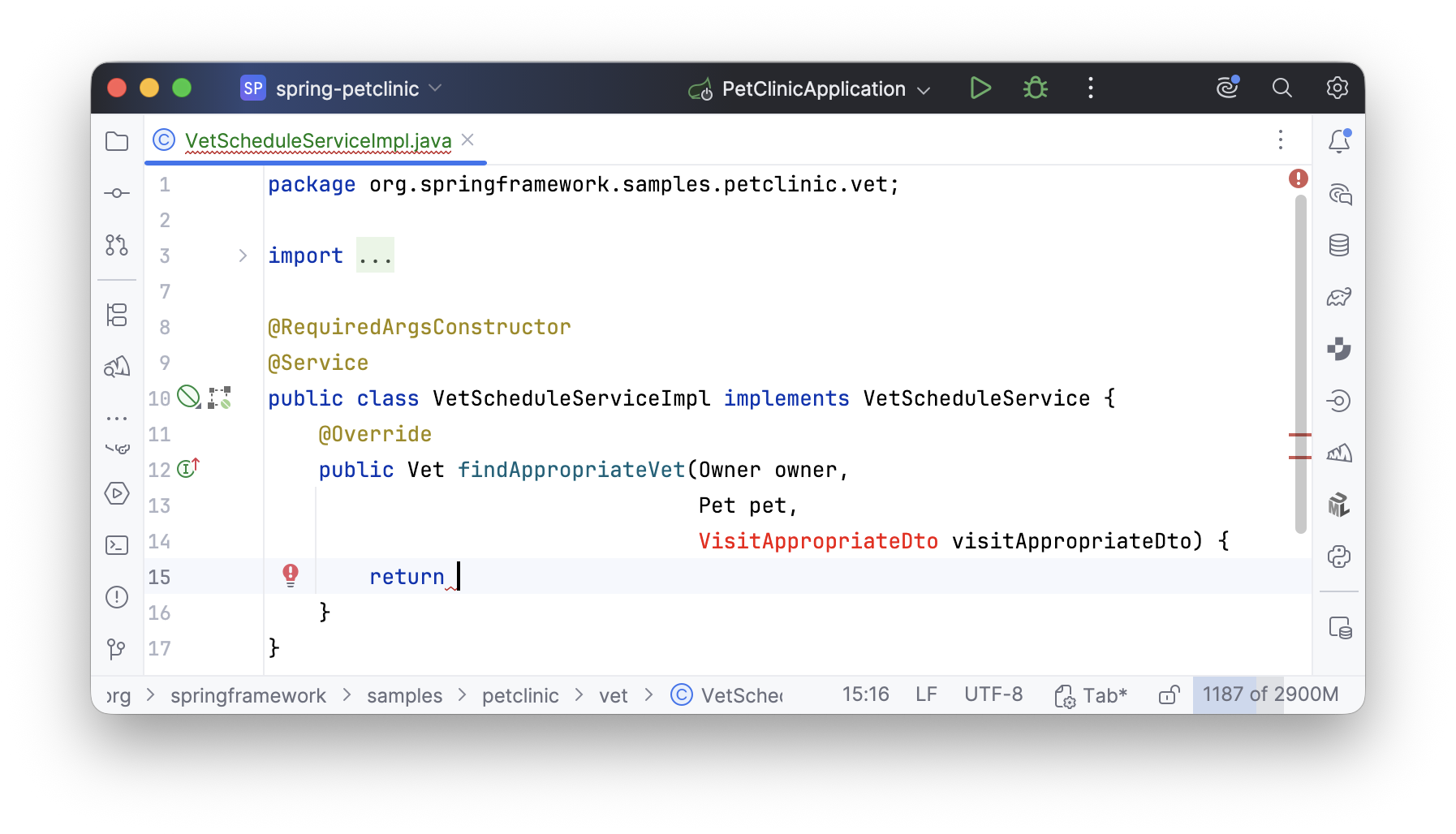
Создание DTO: генерация и маппинг
Чаще всего мы создаем DTO копированием уже существующего объекта. IDE отлично с этим справляется: удаляет лишнее, добавляет нужное. В качестве элемента от которого можно оттолкнуться обычно используются сущности или другие DTO.
Но у такого подхода есть неудобства:
- Много ручных действий — особенно если мы хотим превратить mutable-сущность в record.
- Сам процесс компоновки: приходится искать подходящую DTO с нужными полями и копировать их.
Работа с DTO кажется рутинной и утомительной. Казалось бы, AI должен решать такие задачи, но и ему приходится явно перечислять нужные поля, что порой сложнее, чем ручное копирование.
Что хотелось бы? Возможность быстро выбрать поля для DTO из базы — сущности или другой DTO. И со временем захочется указывать, как именно отображать ссылки и коллекции: flat, nested и т.д. Amplicode как раз это умеет.
Для создания DTO в Amplicode есть несколько вариантов. Можно воспользоваться контекстным меню New..., но мы пойдем другим путем.
В качестве третьего аргумента метода у нас уже указан несуществующий тип
VisitAppropriateDto
. Вызываем стандартное действие IDE для исправления некорректного кода и выбираем Create DTO... от Amplicode.
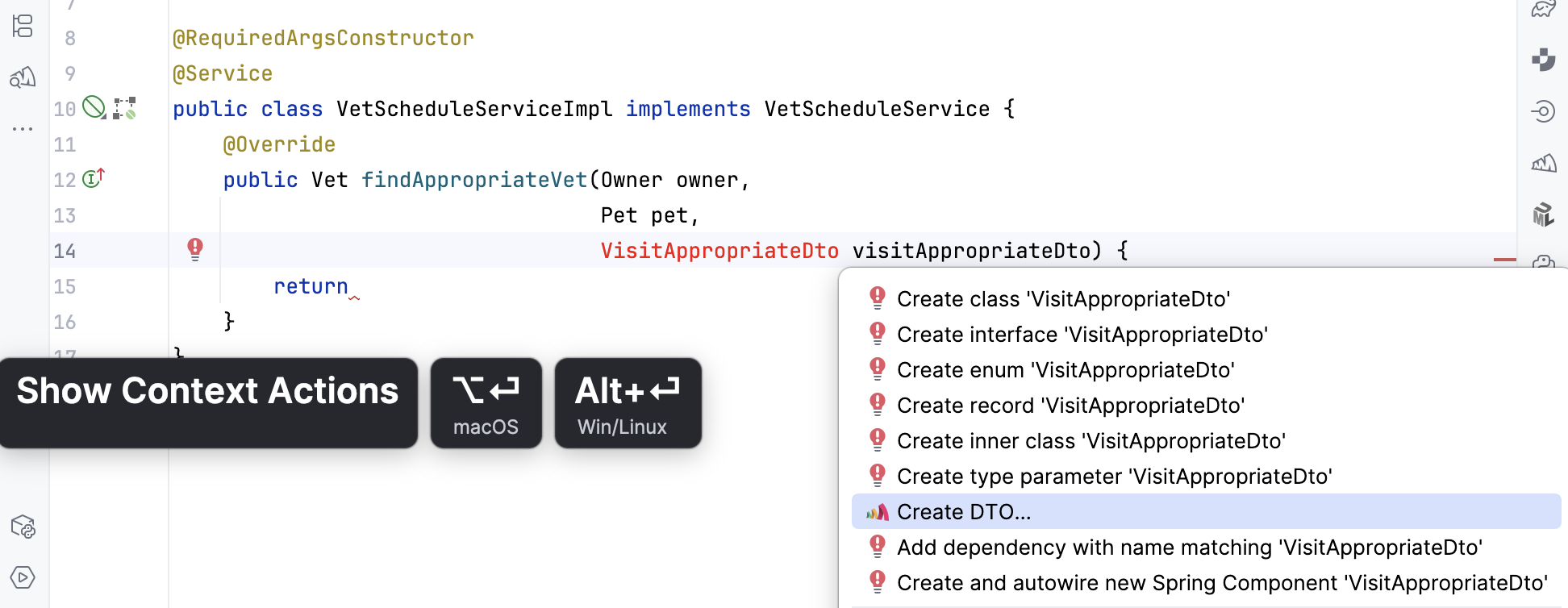
Откроется окно создания DTO. В качестве Domain entity указываем созданную ранее сущность визита, а тип результата выбираем Java Record. В нижней части окна появится дерево атрибутов. Это именно дерево: выбрав атрибут-ссылку на другую сущность/DTO/класс, можно выбрать поля и способ их отображения.
> Обратите внимание на поле Mapper. Amplicode умеет не только создавать DTO, но и генерировать функции маппинга для их дальнейшего использования — например, в контроллерах, чтобы преобразовать сущность в DTO или наоборот. Поддерживаются: MapStruct, ModelMapper, Custom Mappers.
Для нашей задачи нужны поля
date
и
description
. Отмечаем их и нажимаем OK. Amplicode создаст record с выбранными полями.
Если забыли что-то добавить, не проблема: открываем DTO, начинаем вводить название поля — Amplicode предложит недостающие атрибуты, так как знает связь между DTO и исходной сущностью.
Умная инжекция во время набора кода
После описания метода в интерфейсе осталось написать реализацию. В современных условиях в качестве реализации такого метода было бы интересно вызвать AI, передав ему информацию о ветеринарах, их расписаниях и описании визита, чтобы он подобрал подходящего кандидата. Конечно, при этом нужно было бы добавить формальные проверки: наличие нужной специальности, свободного времени и т.д. Но такой сценарий тянет на отдельную статью. Мы реализуем более простую логику: будем искать ветеринара с заранее известной специальностью, например «Хирургия».
Для этого нужно заавтовайрить репозиторий ветеринаров в сервис. Сделать это можно вручную: описать поле и добавить его в конструктор (или воспользоваться Lombok). Но с Amplicode есть ещё один более удобный способ – умная инжекция во время набора кода.
Это очень удобно:
- не нужно переходить в начало файла и прописывать поле вручную;
- если репозиторий еще не создан, IDE предложит его сгенерировать;
- при выборе подсказки IDE сразу выполнит автовайринг, учитывая, используется ли Lombok.
В теле метода начинаем вводить
vetRep...
IDE предложит создать
VetRepository
, а затем сразу добавить его в сервис.
Далее нужен метод поиска ветеринаров по специальности. Открывать репозиторий и писать его вручную необязательно можно создать метод прямо из того места, где нужно будет его вызвать.
Начнём набирать название метода для
VetRepository
и IDE покажет не только уже существующие, но и позволит создать новый метод налету. Тут же можно воспользоваться функцией Amplicode для создания derived-метода (описанной ранее, через удобный UI). Создаем метод поиска всех ветеринаров по списку специальностей.
Осталось определить
id
специальности, по которому выполняем поиск. Лучше вынести его в
application.properties
:
petclinic.appropriate.vet.speciality.id=2
В сервисе добавляем поле с аннотацией
@Value
. Обычно здесь возникают ошибки в SpEL, даже несмотря на поддержку в IDE. Amplicode решает эту проблему: автоподстановка для Spring Properties работает так же, как для бинов. Начинаем вводить
petcli...
, выбираем
petclinicAppropriateVetSpecialityId
из подсказок — Amplicode сделает все остальное.
На этом метод сервиса готов. Пора опубликовать его в REST.
Доступ к приложению через REST
Создание любого API начинается с определения правил, по которым оно будет строиться. В каждой организации, в зависимости от проекта, они могут отличаться. Но обычно внешнее API строят в формате REST over HTTP(S). Давайте реализуем его.
Начнем с ветеринаров. Создадим RestController: в контекстном меню выбираем New → Rest/MVC Controller, указываем название
VetRestController
и путь
/rest/vets
, нажимаем OK.
Осталось создать метод, который будет делегировать вызов сервису. На практике, помимо API для бизнес-функций, обычно нужен и CRUD API. Начнем с него.
CRUD REST API: пошаговая реализация
Определим список методов для CRUD API:
-
getOne(id)— получить ветеринара по идентификатору -
getList(filter)— получить список ветеринаров с фильтрацией -
create(prototype)— создать ветеринара -
update(id, new state)— обновить информацию о ветеринаре -
patch(id, diff)— частично обновить информацию о ветеринаре -
delete(id)— удалить ветеринара
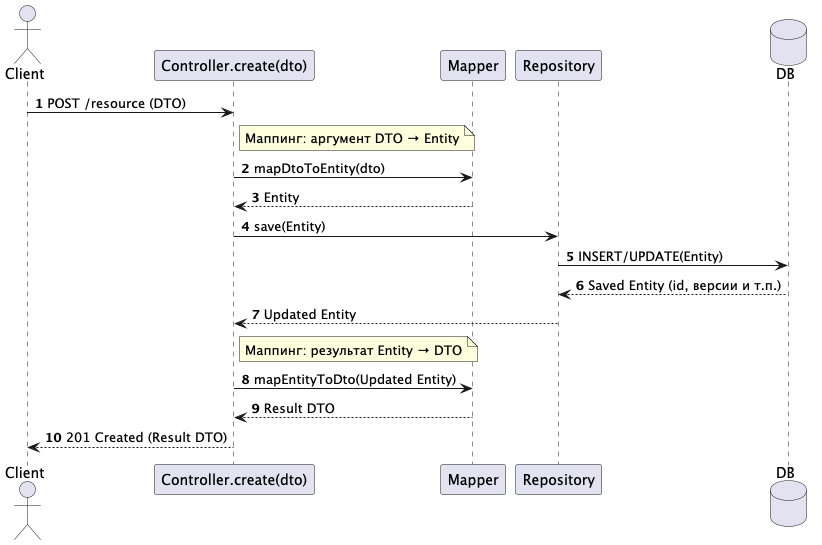
Эти операции соответствуют методам нашего JPA-репозитория и представляют собой делегацию вызова из контроллера в репозиторий (или сервис) с маппингом DTO ↔ сущность. Рассмотрим подробнее операцию
create
, так как она требует маппинга и аргумента, и результата.
Метод
create
в контроллере будет вызывать
save
в репозитории.
save
принимает сущность и возвращает обновленную сущность. В контроллере нужно смапить аргумент на сущность, а результат — обратно на DTO.
В главе про DTO мы упоминали, что Amplicode умеет генерировать методы маппинга — самое время их использовать. Нужно создать две DTO: одну для аргумента, другую — для результата. Через New → DTO выбираем
Vet
как Domain entity, отмечаем все поля, кроме
id
. В поле Mapper нажимаем
+
, выбираем MapStruct. Если нужной библиотеки нет в проекте, Amplicode добавит ее автоматически. После OK будут созданы DTO и интерфейс MapStruct. Аналогично создаем DTO для результата.
Метод контроллера создаем через live template
post
: начните печатать
post
или
@post
, выберите подсказку, IDE сгенерирует шаблон POST-запроса. В пути оставляем базовый, в качестве реквеста и респонса указываем созданные DTO. Не забудьте про
@RequestBody
для аргумента.
Далее нужен сервис, которому будет делегирована операция создания. В сервисе создаем метод, аналогичный методу контроллера. Маппинг выполняем на границе транзакции. Amplicode уже сгенерировал методы маппинга — остается вызвать репозиторий из сервиса, а сервис — из контроллера.
Спойлер: полезные приемы IDE и Amplicode:
- Напишите имя аргумента, поставьте точку, начните набирать
...mapTo, выберите.mapToEntity. Amplicode преобразует вызов вVetMapperи заинжектирует его. - Наберите
.var, выберите подсказку — IDE создаст переменную и выведет тип. - Вызовите
.saveна entity — Amplicode преобразует выражение в вызовsaveи заинжектирует репозиторий. - Сохраните результат в переменную и вызовите
.mapToVetCreatedDto. - Наберите
.return, чтобы автоматически добавитьreturn.
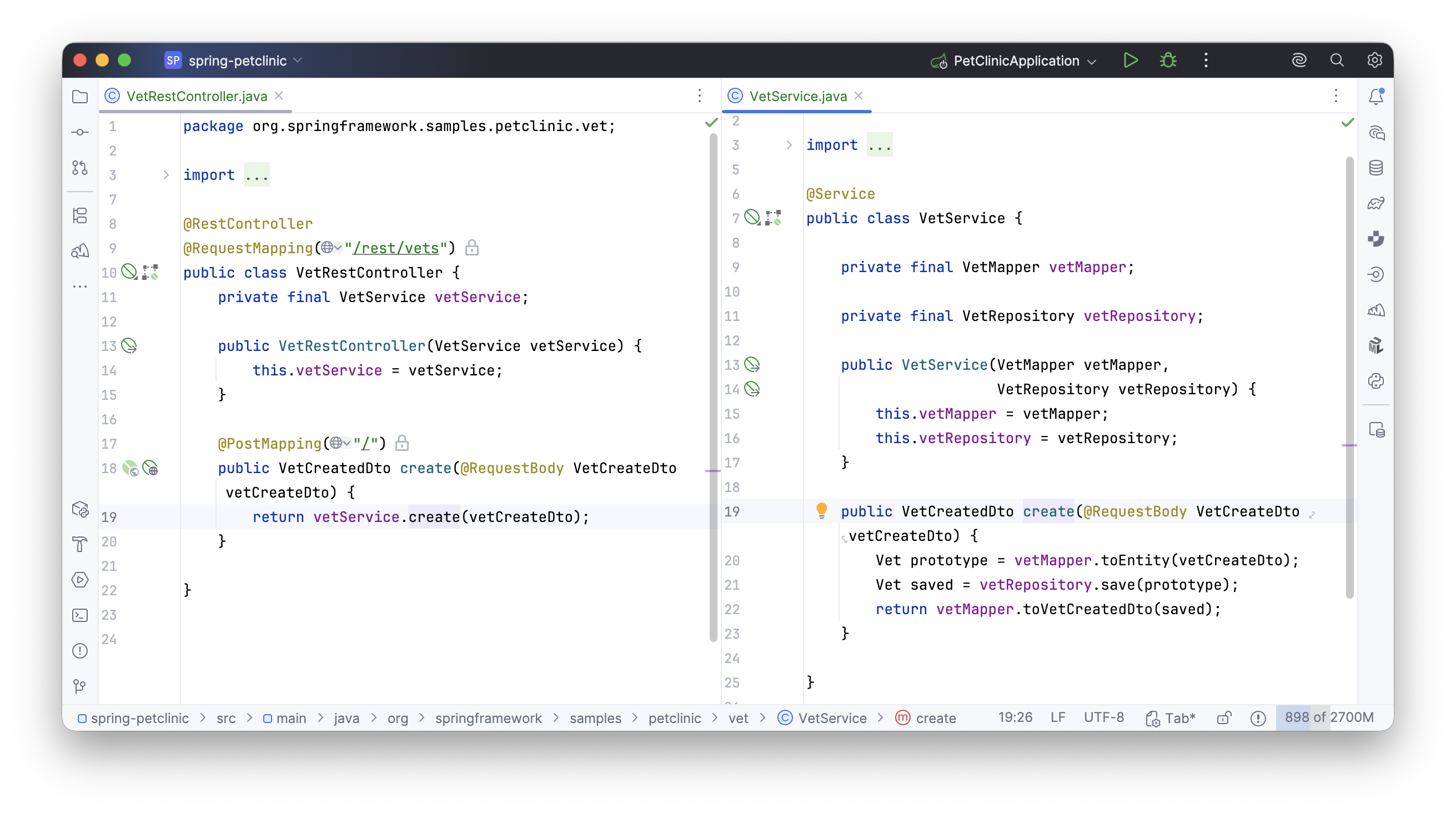
Даже не смотря на то, что мы оперировали высокоуровневыми объектами, сразу создавая не просто классы, а DTOшки, мапперы, контроллеры и т.д., мы потратили довольно много времени.
В Amplicode есть функциональность, которая позволяет сделать все это еще проще.
Кастомный API и делегация между бинами
Реализуем следующий метод из нашего списка —
getOne(id)
. На этот раз воспользуемся функциональностью делегирования в Amplicode. Делегирование доступно из любого Spring Bean в другой. Amplicode учитывает специфику бинов, предлагая дополнительные возможности при делегировании, например, из репозитория или в контроллер.
Нам нужно делегировать метод
VetRepository#findById
в
VetRestController
, используя в качестве промежуточного сервиса (будем называть его прокси-сервисом) VetService. Для этого открываем VetRestController, вызываем контекстное меню Generate и выбираем действие Delegate from. Если открыть сервис или компонент, будет доступно также Delegate to.
В открывшемся окне выбираем бин, методы которого хотим делегировать, — в нашем случае
VetRepository
. Ставим галочку Use proxy service, в качестве сервиса указываем
VetService
. Выбираем метод
findById()
, настраиваем делегацию: в Return type выбираем ранее созданное DTO (или создаем новое с маппингом) и отмечаем Unwrap Optional. Нажимаем OK. Amplicode сгенерирует весь необходимый код во всех компонентах в том же виде, как мы делали вручную в предыдущей главе.
Однако созданный метод не полностью решает задачу: он не возвращает 404, если объект с переданным id не найден. Это легко исправить, достаточно выбрасывать ResponseStatusException с кодом 404. Почему Amplicode не делает это по умолчанию? Потому что делегация — инструмент низкоуровневый, и
findById()
может использоваться для самых разных целей, не только для REST-контроллеров.
Если же нужны CRUD-методы контроллера, полностью соответствующие REST, в Amplicode есть отдельный инструмент для их генерации.
CRUD REST API: на автопилоте
Сгенерируем еще один метод
getOne()
, но на этот раз создадим DTO, содержащую информацию не только о ветеринаре, но и о его специальностях.
Открываем
VetRestController
. Вместо контекстного меню Generate воспользуемся Amplicode Designer — полезный инструмент для знакомства с возможностями Amplicode. Переходим в раздел Request Handling, выбираем метод Get One (by id). В открывшемся окне в качестве репозитория выбираем
VetRepository
. В поле DTO нажимаем + для создания новой, указываем
VetMapper
как маппер, а для поля
specialities
выбираем тип New Nested Class. Нажимаем OK. В поле Proxy service указываем
VetService
. Еще раз нажимаем OK.
Amplicode сгенерировал связывающий код, добавил методы репозитория, создал DTO и настроил методы маппинга. Учёл, что это именно CRUD REST API: для метода Get One возвращается 404, если объект по id не найден.
Теперь можно легко реализовать остальные CRUD-методы контроллера. Если вам нравится, как Amplicode генерирует код, можно воспользоваться действием по созданию полноценного CRUD Rest Controller (доступно в меню New...). В результате Amplicode создаст контроллер со всеми методами CRUD API, включая работу с коллекциями.
Приступим к проверке того, что накодили. Для этого есть несколько способов, рассмотрим два самых популярных:
- Вызов API любым клиентом (Postman/cURL/Connekt).
- Написание Spring Boot тестов.
HTTP-клиент в IDE – лучше, чем Postman
Для начала попробуем вызвать наш API с помощью внешнего HTTP-клиента. В IntelliJ IDEA есть встроенный HTTP-клиент. Его важная особенность — описание запроса максимально близко по структуре к протоколу. Это значит, что для большинства запросов, которые корректно отрабатывают в IDE, можно воспользоваться консольной утилитой
telnet
: скопировать запрос из IDE и получить результат. Это было преимуществом, когда клиент только добавили в IDE. Но время шло, аппетиты пользователей росли, и нужно было искать решение, как их удовлетворить. Чего хотели пользователи:
- поддержку переменных и разных окружений,
- возможность извлекать данные из результатов и использовать их в будущих запросах,
- возможность связывать запросы в цепочки и проходить сложные процессы авторизации,
- возможность описывать сценарии с циклическими запросами, доступом к тестовым данным и т. д.
Пользователям нужен был не просто клиент для отдельных запросов, а программируемый клиент. В результате в HTTP-клиенте появились возможности программирования на JS. В итоге мы получили мощный инструмент: зная JS и API, можно реализовать самые сложные сценарии. Однако смешение текстового протокола и программирования на JS стало частым источником сложностей.
### Request with Loop Support, variables from environment file
POST https://examples.http-client.intellij.net/post
Content-Type: application/json
{
"clientId": ,
"firstName": ""
}
> {%
let clientId = request.templateValue(0)
client.log(`Client id: ${clientId}`)
let firstName = request.templateValue(1)
client.log(`First name is: ${firstName}`)
client.test(`Client ${clientId} has initial firstName ${firstName}`, () => {
let currentFirstName = jsonPath(response.body, "$.json.firstName")
client.assert(firstName == currentFirstName)
})
%}
Казалось бы, проще было бы изначально описывать запросы DSL поверх известного языка программирования. Примут ли его? Какой язык выбрать — Groovy, JS? На первый вопрос ответит время, а на второй сейчас ответ очевиден: таким языком должен быть Kotlin. Но HTTP-клиента на Kotlin DSL, интегрированного в IDE до некоторых пор не было. Но не так давно именно такой клиент появился в Amplicode! Open-source клиент Connekt. Давайте воспользуемся им.
Начнем с генерации запроса от существующего эндпоинта — метода создания ветеринара. Найдя соответствующий метод в контроллере, кликните по gutter-иконке напротив него и в выпадающем списке выберите действие Generate request in Connekt. В результате Amplicode сгенерирует Connekt-описание, включая шаблон
body
, в scratch-файле, по аналогии со стандартным клиентом. Напротив каждого Connekt-запроса в IDE доступна иконка запуска — воспользуемся ей.
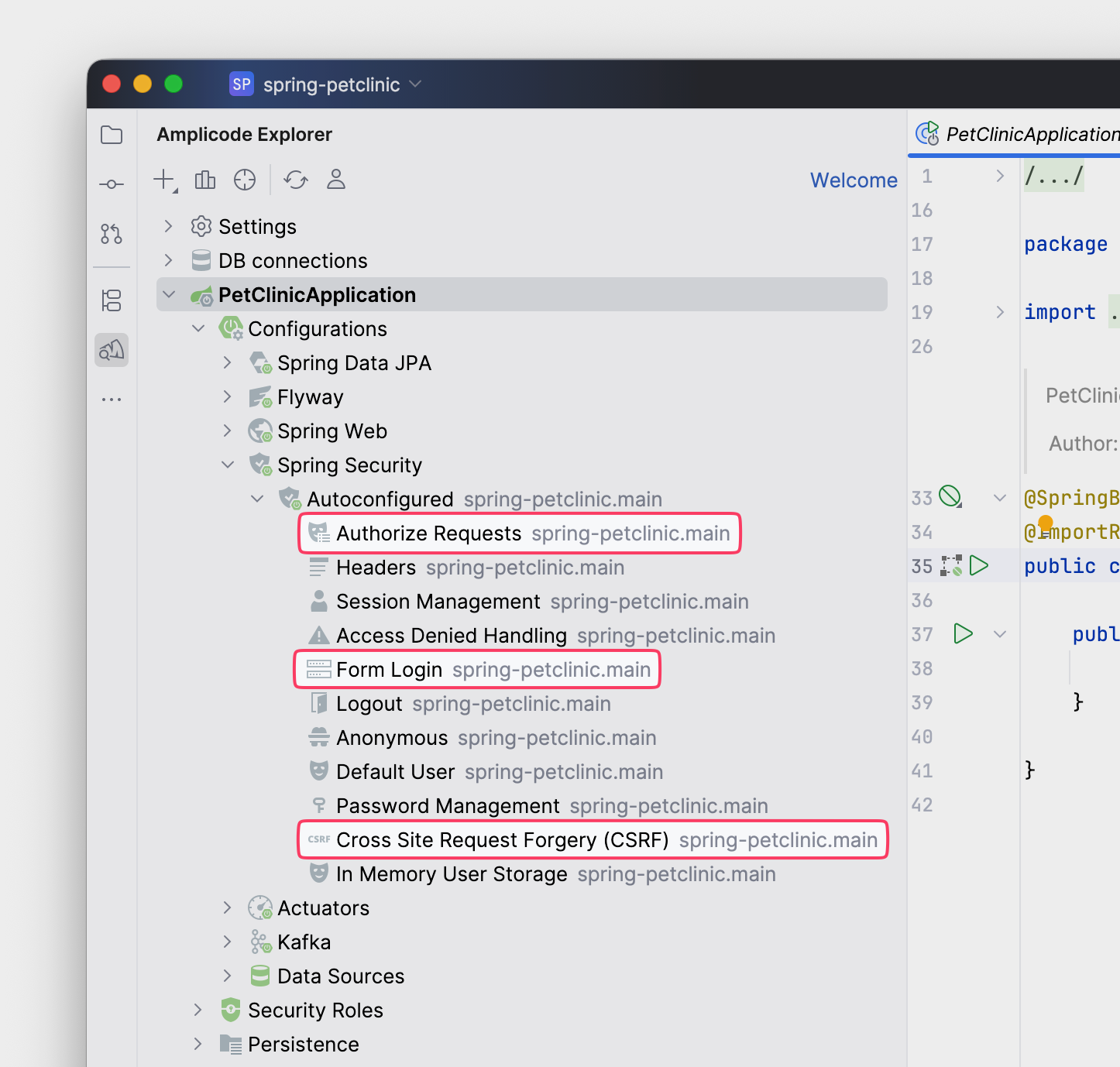
Как видим, запрос вернул 401. Заглянем в раздел Configuration в Amplicode Explorer. В проекте есть конфигурация Security — помните, в самом начале мы добавляли ее при генерации проекта. Даже если мы не определяли
SecurityFilterChain
, Spring-автоконфигурации сделали это за нас. Но как понять, в каком виде настроена Security? Искать нужную автоконфигурацию, читать документацию?
Достаточно развернуть конфигурацию Spring Security в Amplicode Explorer. В нашем случае автоконфигурация включает Form Login, Basic Auth и CSRF. Реализуем вариант Basic Auth + CSRF.
Сначала получим CSRF-токен. Так как у нас подключен Form Login, токен можно извлечь из страницы ответа — воспользуемся регулярным выражением:
val csrfToken by GET("http://localhost:8080/login") {
} then {
val csrfRegex = """<inputs+name="_csrf"s+type="hidden"s+value="([^"]+)"s*/>""".toRegex()
csrfRegex.find(body!!.string())?.groupValues?.get(1)
}
Как можно заметить, значение CSRF-токена сохранено в константу (ее можно вычислять лениво — полезно в сценариях с условными блоками).
Возвращаемся к ранее сгенерированному эндпоинту создания ветеринара и добавляем заголовок
X-CSRF-TOKEN
. Этого недостаточно — нужно еще авторизоваться.
Для Basic Auth в Connekt есть нативная поддержка. Поскольку в основе лежит Kotlin DSL, достаточно вызвать completion, начав набирать
basi...
, и выбрать
basicAuth
. Пользователь по умолчанию —
user
, пароль возьмем из логов приложения.
Осталось проверить, что ветеринар действительно создан. В запросе выше мы уже извлекли
id
созданного ветеринара и сохранили его в переменную. Вызовем получение ветеринара по
id
и убедимся, что он создан корректно.
На этот раз сгенерируем запрос через Amplicode Explorer: в контекстном меню на endpoint
getOne
выбираем Generate request in Connekt (аналогичное действие доступно в любом файле Connekt в меню Generate). В сгенерированном запросе указываем
id
созданного ветеринара как параметр, добавляем CSRF-токен и авторизацию уже известными способами. Осталось убедиться, что фамилия в ответе совпадает с указанной при создании.
Это можно сделать и глазами, но в Connekt есть функциональность assertion. Начните писать
asse...
, выберите в completion
assertThat
, укажите ожидаемое и актуальное значение. Актуальное извлечем через
jsonPath
. Выполняем запрос:
Запрос выполнился без ошибок — значит, созданный ранее ветеринар действительно имеет фамилию «Ivanov». Конечно, сценарий не идеален: как минимум, пользователя и пароль стоит вынести в переменные окружения. Это всё также можно сделать. Читайте подробнее про возможности Connekt в этой статье.
Connekt — мощный инструмент: с его помощью можно реализовывать самые сложные сценарии. При этом простые вещи делаются просто, а сложные — настолько просто, насколько это возможно.
Теперь повторим сценарий в классическом Spring Boot-тесте. По сути, написанный сценарий уже является тестом: в нем есть
assert
, а сам сценарий, ничего не меняя, можно запустить на CI.
Spring Boot Web-тесты (MockMvc / @SpringBootTest)
Ранее мы обсуждали классические инструменты и генераторы, основанные на статическом анализе. Но говорить о тестах и не упомянуть AI уже невозможно. Именно тесты и документация — те области, где AI набрал наибольшую популярность.
В IntelliJ IDEA, помимо множества плагинов в JB Marketplace, есть два предустановленных плагина: AI Assistant и Junie. Оба хорошо справляются с написанием большинства тестов, но не всегда с первого раза результат совпадает с ожиданиями. Возникает выбор: продолжать «промптить» или воспользоваться классическими инструментами. Момент, когда стоит остановиться, каждый определяет сам — но он неизбежно наступит. Разберемся, какие инструменты будут доступны в этот момент.
За основу возьмем endpoint
create
. Сначала нужен тестовый класс. В Spring есть несколько подходов к тестированию web:
- Sliced-тесты — контекст включает только компоненты web-слоя. Подробнее читайте в документации.
-
@SpringBootTest+MockMvc— поднимается полный контекст, упрощается работа с инфраструктурой (например, с security). -
@SpringBootTest+TestRestTemplate— тесты, сопоставимые с вызовами через Connekt.
Выбор зависит от задачи, но чаще всего используют комбинацию
@SpringBootTest
и
MockMvc
— золотая середина: основной контекст поднят, ощущение реального приложения есть, при этом не нужно заботиться о web-инфраструктуре и реальном порте. Как создать такой тестовый класс?
Проще всего сгенерировать Spring Web Test от контроллера или его метода. Откройте контроллер (
VetRestController
), слева от названия класса нажмите на иконку бина и в выпадающем списке выберите Generate Spring Web Tests.... В открывшемся окне напротив Target нажмите
+
(Create Web Test), укажите имя тестового класса и в качестве контекста выберите Spring Application Context. Ниже в списке методов контроллера отметьте
create
. Справа видно, что Amplicode корректно распознал конфигурацию Spring Security и CSRF. Снимите галочку Print results и выполните генерацию. Останется поправить
body
(например, фамилия
"Petrov"
) и добавить утверждения.
Как и в сценарии с Connekt, нужно убедиться, что фамилия действительно совпадает с указанной в запросе на создание. Чтобы извлечь
id
из ответа, распарсим результат вызова endpoint с помощью
ObjectMapper
. Поскольку это Spring Boot-тест, нет необходимости делать дополнительный запрос — достаточно заавтовайрить
VetRepository
и получить ветеринара по
id
. Затем написать
assert
.
@Test
public void create() throws Exception {
String vetCreateDto = """
{
"lastName": "Petrov"
}""";
MvcResult response = mockMvc.perform(post("/rest/vets")
.with(SecurityMockMvcRequestPostProcessors.csrf())
.with(SecurityMockMvcRequestPostProcessors.user("user"))
.content(vetCreateDto)
.contentType(MediaType.APPLICATION_JSON))
.andExpect(status().isOk())
.andReturn();
String responseContent = response.getResponse().getContentAsString();
// Parse JSON to extract ID using ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(responseContent);
Long createdVetId = jsonNode.get("id").asLong();
Vet vet = vetRepository.findById(createdVetId).orElseThrow();
assertThat(vet.getLastName()).isEqualTo("Petrov");
}
Как видно, в IDE есть мощные инструменты тестирования — на случай, если тесты все же пришлось писать вручную.
Остается еще одна задача перед деплоем на test/production-контуры: рассказать, как работает наш API. Пора подготовить схему OpenAPI.
Генерация OpenAPI-схемы
Решить эту задачу можно по-разному: аннотировать методы дополнительными аннотациями, подготовить описание вручную или сгенерировать автоматически. И IntelliJ IDEA Ultimate, и Amplicode включают удобные инструменты генерации OpenAPI-схемы на основе описания в RestController. На выходе можно выбрать формат (YAML/JSON) и область, для которой выполнить генерацию.
Далее вы сами решаете, что делать с результатом: использовать его целиком, заменив существующую схему (если это не первая генерация), или дополнить уже имеющуюся.
Вызвать генерацию можно так же, как и для тестов — из gutter-иконки. Откройте
VetRestController
, нажмите на иконку и выберите действие Generate OpenAPI Schema. В открывшемся окне задайте формат, область и место сохранения результата. После нажатия OK схема будет сгенерирована. В нашем случае это первая генерация, поэтому сохраняем результат в файл и публикуем вместе с приложением.
Приложение создано, бизнес-логика реализована, REST готов — самое время заняться публикацией приложения.
Продакшн-деплой
Умение деплоить приложение в production всегда было важным навыком разработчика. Еще 3–5 лет назад часто использовали серверы приложений или UberJar. Сейчас стандартом де-факто стал Kubernetes. Он не единственный, но явно доминирующий.
Кластер Kubernetes можно получить разными способами. Для разработки и тестирования удобно использовать локальные решения — Minikube или Rancher. Production-кластер проще всего заказать у облачного провайдера — это значительно дешевле, чем разворачивать и поддерживать его своими силами (если, конечно, речь не о большой компании, где этим занимается внутренняя команда).
Важно учитывать, что Kubernetes у разных провайдеров может отличаться. Идеальный сценарий выглядит так:
- подготавливаем конфигурацию локально (быстрый фидбек при изменениях),
- деплоим приложение в Kubernetes выбранного облака без изменений,
- при проблемах (цена, стабильность) переносим решение к другому провайдеру.
На практике все не так гладко, но не критично. Часть проблем решается инструментами.
Существует множество решений, упрощающих работу с конфигурациями. Два самых популярных — Helm и Kustomize. Helm, помимо поддержки разных окружений (test, prod, разные облака), является пакетным менеджером. Это упрощает деплой приложения и всей необходимой инфраструктуры. В дальнейшем мы будем использовать именно Helm.
Подключение к Kubernetes-кластерам в IDE
Для тестирования конфигурации нужно подключиться к кластеру Kubernetes. Это можно сделать средствами IDE:
- в панели Services вызовите контекстное меню элемента Kubernetes (убедитесь, что установлен и включен Kubernetes-плагин),
- выберите Add Clusters,
- Если используется локальный кластер, выберите From Default Directory. IDE просканирует доступные Kubernetes, отобразит их в окне — останется выбрать нужный кластер.
После выбора он появится в панели Services. IDEA предоставляет удобные средства анализа кластера: можно просматривать ресурсы, логи, подключаться к контейнерам и многое другое.
Если кластер новый, в нем будут только ресурсы установщика. Самое время заняться деплоем приложения — начать стоит с инфраструктуры.
Инфраструктура: PostgreSQL через Helm
В нашем случае приложению нужна только база данных — PostgreSQL. Развернуть ее в Kubernetes можно с помощью Helm. Есть два варианта: развернуть как сервис или как оператор. Оператор имел бы смысл, если бы мы строили собственное облако.
В репозитории Helm-чартов ArtifactHub доступно множество пакетов PostgreSQL. С одной стороны, это хорошо, с другой — возникает вопрос, какой выбрать. В ArtifactHub нет метки «официальный», как на DockerHub, но указаны вендоры — Bitnami, Celtic и т.д. Долгое время чарт от Bitnami был выбором по умолчанию, но недавно они изменили политику распространения: теперь доступны только latest-версии. Сообщество ждет, кто займет их место, но для нас сейчас это не критично — используем Bitnami.
Поставить PostgreSQL в кластер можно простой командой
helm install
, указав пакет. Но этот способ ограничен: все параметры конфигурации нужно передавать прямо в командной строке. Удобнее указать PostgreSQL как зависимость в собственном Helm-чарте. Для этого создадим пустой Helm Chart.
В IntelliJ IDEA это делается через контекстное меню New…. Обратите внимание: меню содержит два варианта создания чарта — стандартный и от Amplicode.
- Стандартный всегда использует один и тот же шаблон.
- Amplicode позволяет сгенерировать пустой чарт, Spring Boot-чарт и т.д.
Выбираем действие от Amplicode, тип — Empty Helm Chart, имя —
postgresql
. Далее добавляем зависимость. .
Также список доступных для генерации сервисов можно найти в панеле Amplicode Designer:
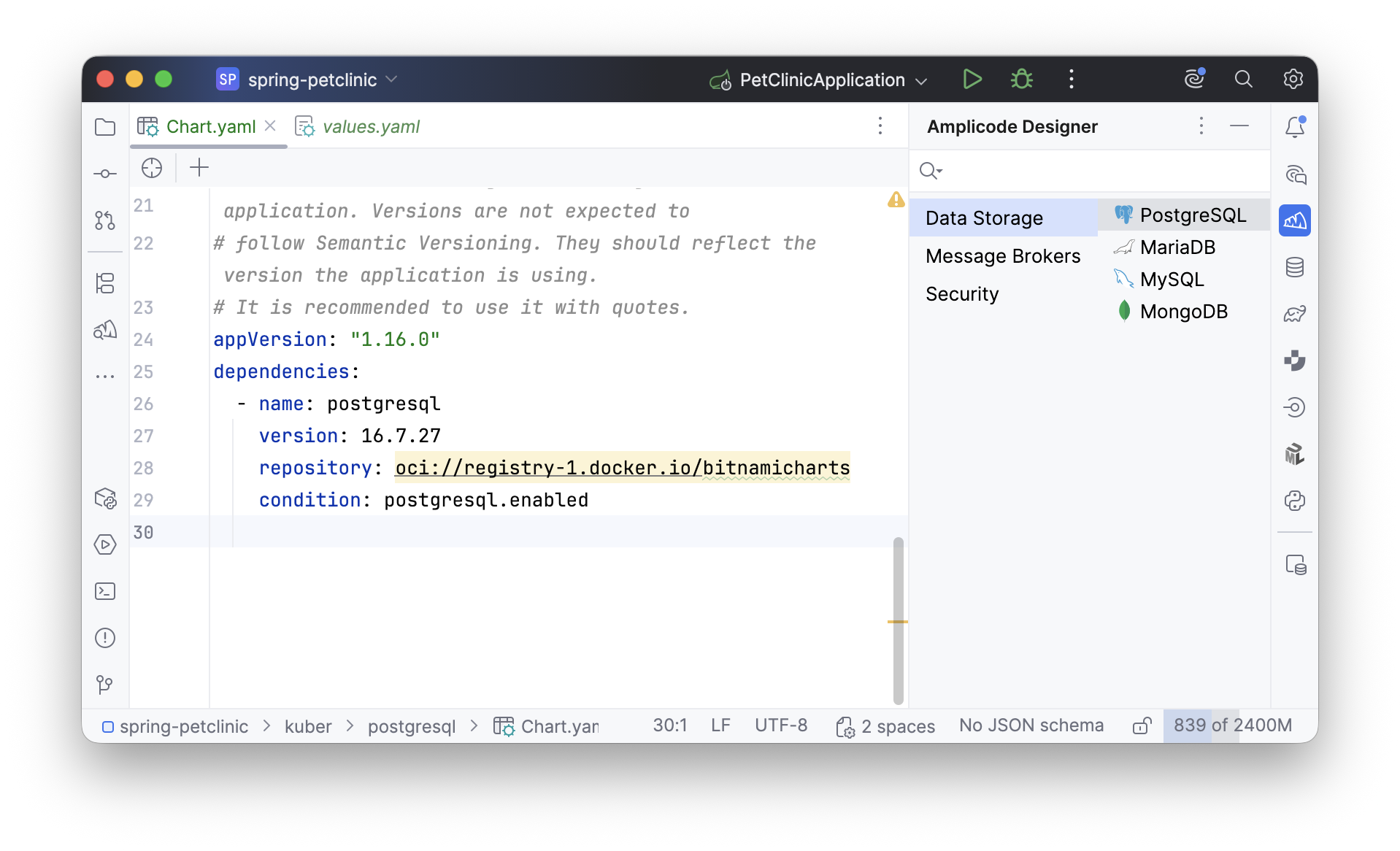
После генерации видно, что зависимость добавлена точно так же, как если бы мы делали это вручную, а в
values.yaml
сразу появилась готовая конфигурация.
Осталось задеплоить конфигурацию.
- В Amplicode Explorer откройте контекстное меню для
postgresqlи выберите Run. - Укажите namespace (если его нет, он создастся автоматически).
Amplicode запустит Helm с нужными параметрами (Helm должен быть установлен). Проверить успешный запуск можно в панели Services — раздел Workloads.
Инфраструктура готова, можно переходить к деплою приложения.
Деплой Spring Boot приложения (Helm, Ingress)
Точно так же, как мы создавали Helm для PostgreSQL, можно создать Helm для нашего Spring Boot-приложения. Отличие лишь в том, что на втором шаге нужно выбрать Spring Boot Application вместо Empty Helm Chart. В открывшемся окне выбираем приложение, проверяем, что Amplicode корректно считал конфигурацию actuator для readiness/liveness-проб, а также порт приложения.
Здесь же можно разрешить внешний доступ к приложению — установите галочку Enable Ingress. Ingress требует DNS-имя и установленный в кластере Ingress-контроллер. Большинство провайдеров Kubernetes предустанавливают контроллер, интегрированный с их инфраструктурой. Локальные инсталляции часто включают Traefik или NGINX. Если контроллер отсутствует, его можно поставить из Helm Chart, как PostgreSQL.
Сгенерированный Helm Chart уже учитывает специфику Spring Boot-приложения, но его нужно доработать. В частности, в
values.yaml
отсутствуют параметры конфигурации DataSource. Чтобы добавить их, редактируем шаблон
deployment.yaml
.
Helm-шаблоны используют Go Template, убедитесь, что включен соответствующий плагин. Плагин JetBrains предоставляет автодополнение, навигацию и другие удобства. Amplicode дополняет их и понимает специфику Spring Boot.
Переопределять свойства Spring Boot можно разными способами, самый популярный — через переменные окружения.
В
deployment.yaml
в секцию
env
добавляем переменные. Для конкретного свойства можно:
- воспользоваться действием Amplicode Wrap property value into environment variable,
- либо использовать стандартное преобразование свойства в переменную окружения.
Выберем второй способ. Автодополнение IDE здесь не помогает, но Amplicode подсказывает доступные опции. Для
name
выбираем
SPRING_DATASOURCE_URL
. Значение берем напрямую из
values.yaml
, выбрав его через completion. После этого задаем базовое значение — Amplicode предложит быстрое исправление. Аналогично добавляем переменные для имени пользователя и пароля.
Запускаем конфигурацию так же, как раньше:
- в Amplicode Explorer для Helm Chart вызываем действие Run,
- указываем тот же namespace, куда был задеплоен PostgreSQL.
Ну а как проверить работу приложения мы уже знаем – через Connekt.
Если что-то пошло не так, в панели Services можно посмотреть логи приложения. Если приложение задеплоено, но не отвечает по имени, можно сделать port forwarding для ресурса — действие доступно в контекстном меню.
Можно выдохнуть: мы прошли полный цикл — от создания приложения до деплоя в production.
Поддержка устаревших версий IntelliJ IDEA Ultimate (2022.x)
Несмотря на то, что актуальная версия Amplicode поддерживает только три последних мажорных версии IntelliJ IDEA, можно установить одну из предыдущих версий Amplicode и получить улучшение даже для outdated инструмента.
Важно: все новые фичи, вышедшие после Amplicode 2024.1, в устаревших IDE недоступны. Поэтому мы крайне рекомендуем вам рассмотреть переезд с устаревших версий IDE на актуальную.
Если ваша команда пока не готова обновляться — свяжитесь с нами через Telegram-чат или форму на сайте, и мы поможем вам спланировать переезд.
Установив Amplicode в IntelliJ IDEA Ultimate 2022.x, вы получите не только функции, описанные выше, но и возможности более поздних версий IDE. Иными словами, Amplicode в IntelliJ IDEA Ultimate 2022.x дает часть функциональности версии 2025.x. Попробуйте и убедитесь сами.
Заключение
Даже не смотря на то, что эта статья получилась просто огромной, у нас всё равно не получилось перечислить все возможности, которые даёт Amplicode в дополнение к функциональности IntelliJ IDEA Ultimate. Например, мы ничего не рассказали про поддержку Terraform, Kafka, MongoDB, лишь вскользь упомянули поддержку Spring Security, не показали всех возможностей для работы со Spring Web и много чего ещё.
Но всё же лучший способ оценить поддержку именно ваше стека со стороны Amplicode – это попробовать его в действии! Устанавливайте Amplicode абсолютно бесплатно уже сейчас, а чтобы получить от инструмент максимум – активируйте триальную подписку на Amplicode PRO!

Ну и подписывайтесь на наш ТГК, там мы рассказываем про Amplicode, Spring и всё что с ними связано!