Amplicode для продуктивной разработки: практическое руководство
Откройте для себя возможности Amplicode — набора инструментов, который помогает сделать разработку на Spring Boot более удобной и продуктивной. В этом руководстве мы шаг за шагом покажем, как использовать плагин в рабочих задачах для ускорения создания веб-приложений.
План:
- Знакомство с UI
- Добавляем новый домен
- Доработка приложения
- Миграции
Знакомство с UI
А что, если я скажу вам, что теперь вы можете понять структуру Spring Boot проекта любого масштаба — не открыв ни единого файла или класса?
Вы сразу получите полное представление об архитектуре, узнаете, какие библиотеки подключены, какие конфигурации заданы, какую базу данных использует проект, какая система версионирования БД используется. Вы увидите доступные эндпоинты, используется ли брокер сообщений и получите массу другой важной информации.
Перед нами стоит задача: получить представление о всем стеке приложения, не изучив ни одной строчки кода.
Шаг 1: Открыть среду разработки, установить Amplicode, открыть проект.
Начнем с того, что склонируем данный проект, откроем его. В среду разработки должен быть установлен Amplicode.
Первым делом в глаза бросается Welcome Screen, на котором расположена краткая информация о возможностях плагина, а также ссылки на ресурсы.
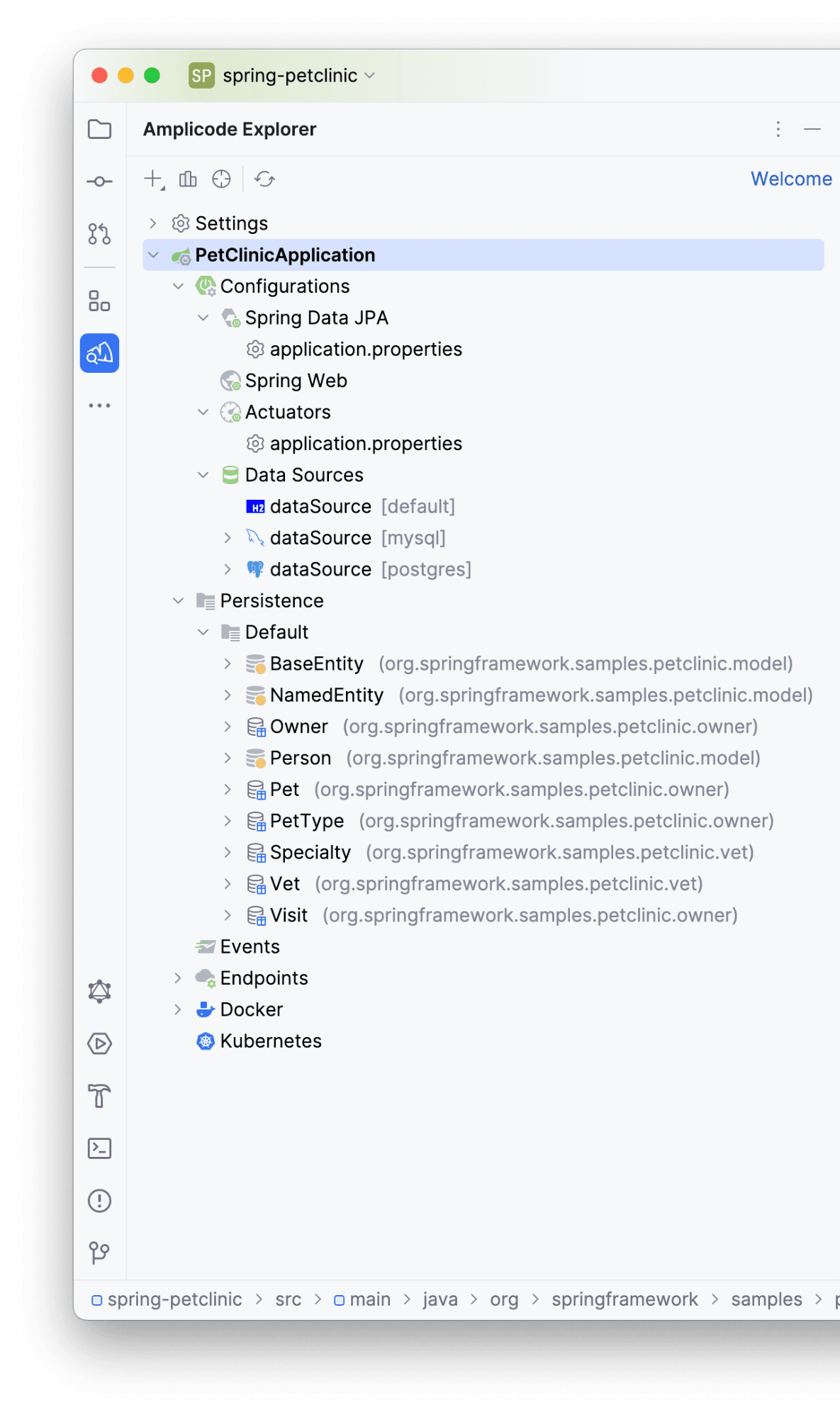
Шаг 2: Панель Amplicode Explorer
На левой части интерфейса среды разработки расположена иконка Amplicode, по нажатию на которую можно показывать/скрывать панель Amplicode Explorer.
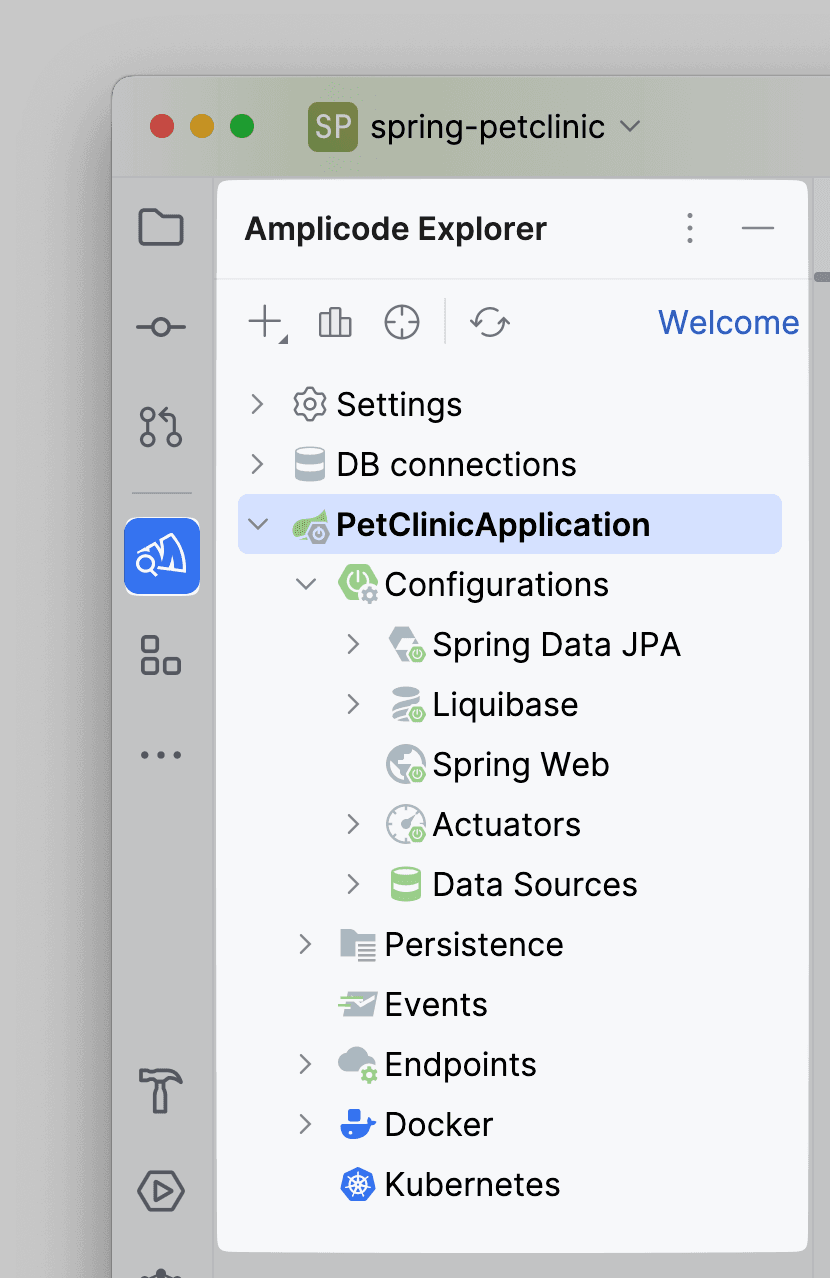
На данной панели содержится несколько секций:
-
Settings: содержит действия по навигации к настройкам плагина.
-
DB Connections: со всеми подключениями к БД в текущем проекте.
Блок с названием проекта, содержащий всю информацию по нему, включает секции:
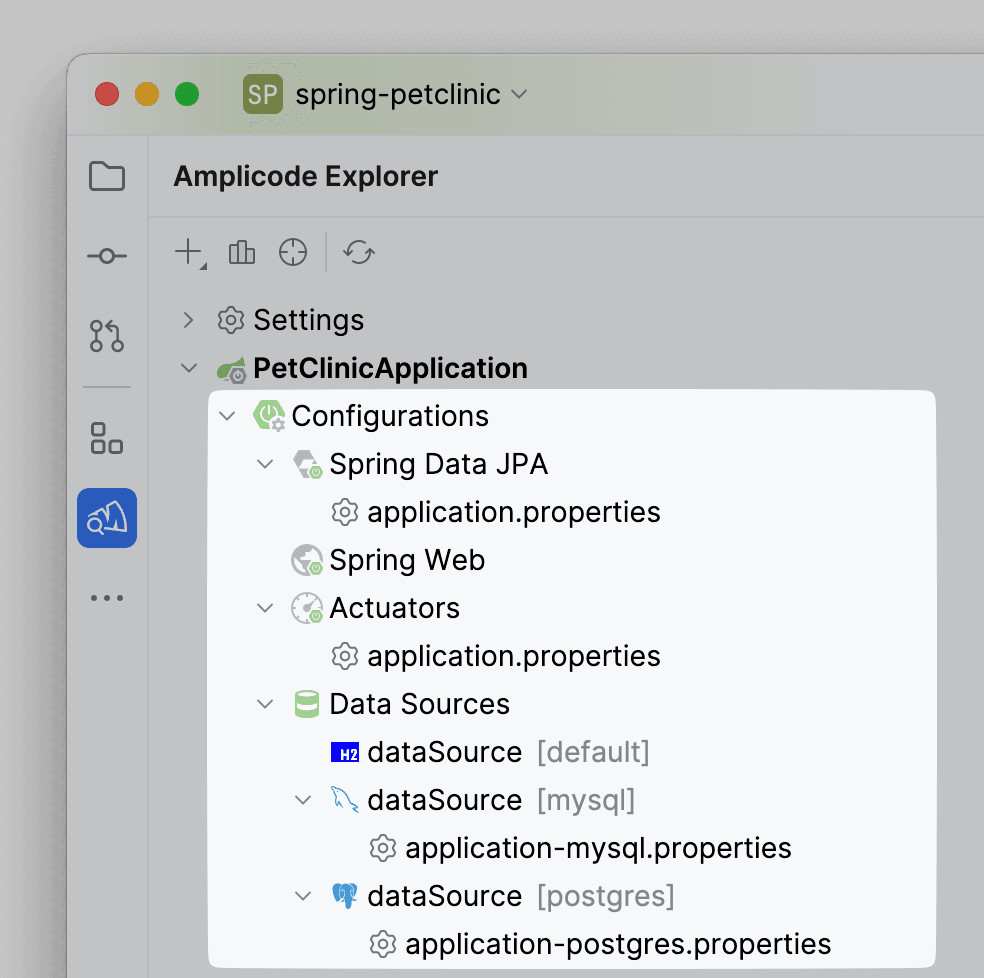
- Configurations. В нем представлены блоки с конфигурациями, содержащимися в проекте.
Здесь мы видим, что в проекте:
- Подключена зависимость на Spring Data JPA
- На Spring Web
- Описан Actuators в файле application.properties
- Data Sources (h2, PostgreSQL - свойства описаны в файле application-postgres.properties, MySQL - свойства описаны в файле application-mysql.properties).
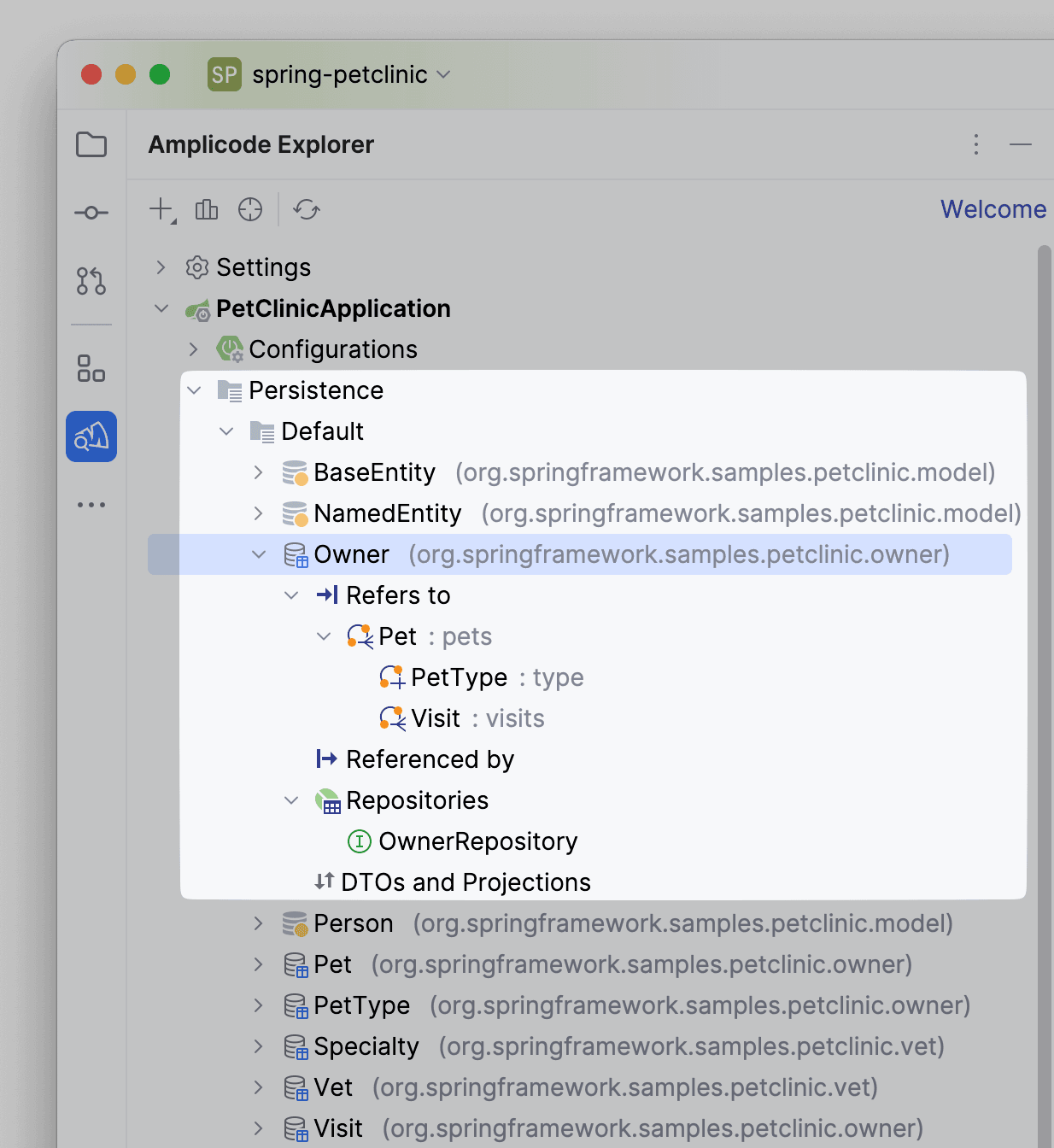
- Persistence. В данной секции представлены классы, относящиеся к доменному слою приложения. Взаимодействуя с ними, узнать информацию о связях между сущностями, наличие репозиториев, DTO и проекций.
- Events. Блок содержит информацию по отслеживаемым/отбрасываемым ивентам внутри приложения. Блок пустой, так как event’ы в проекте отсутствуют
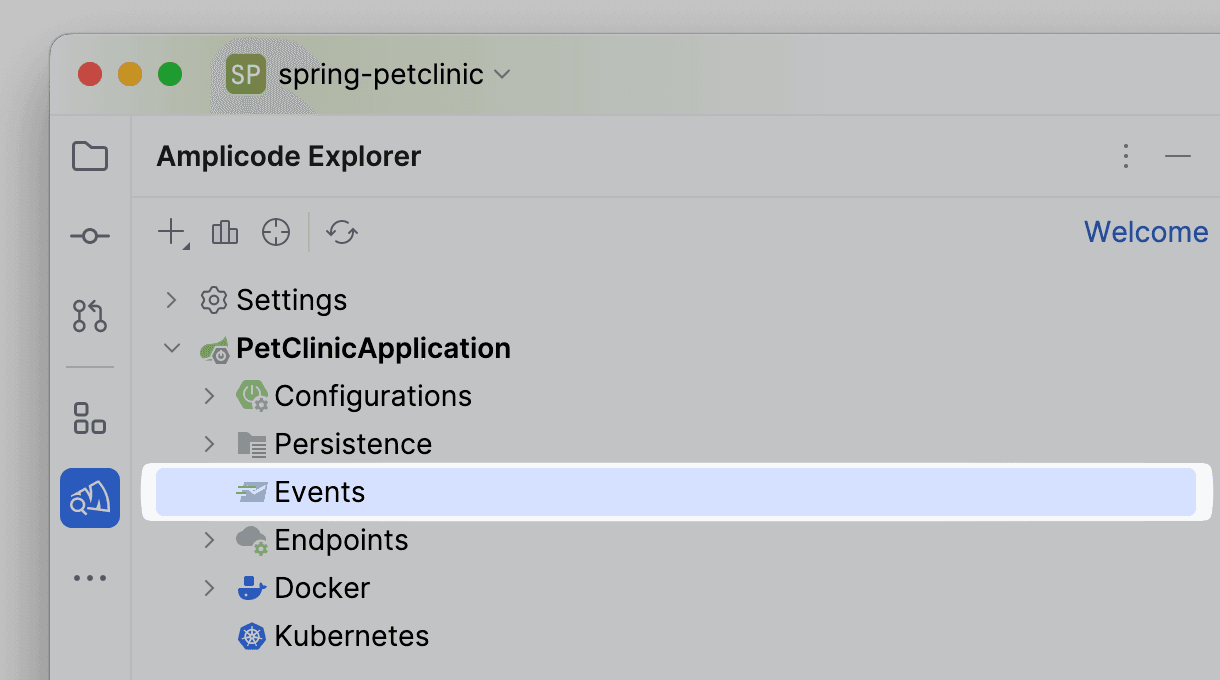
- Endpoints. Блок с информацией по доступным эндпоинтам приложения. Поддерживается группировка (ПКМ по блоку → Endpoints Grouping)
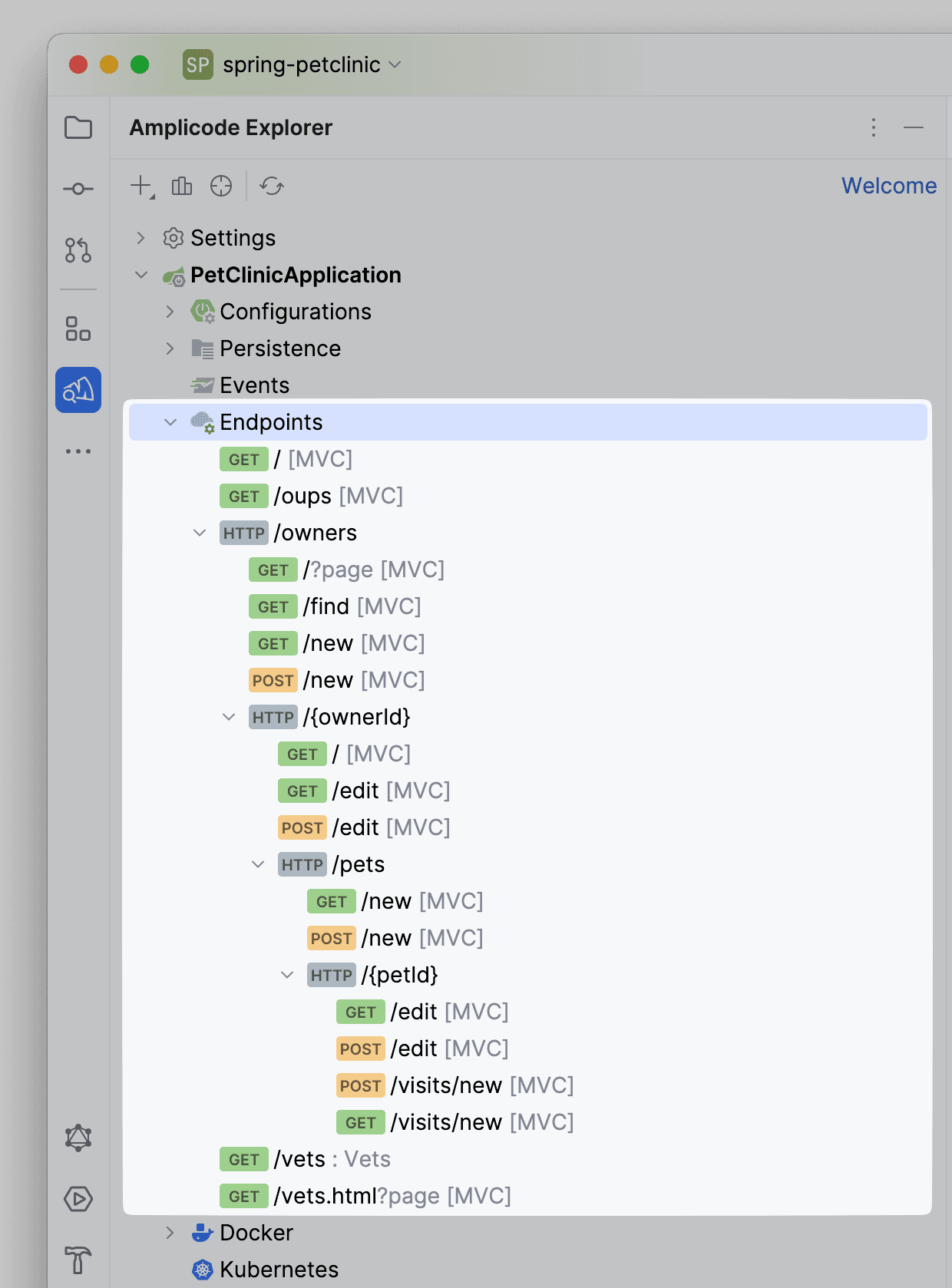
- Docker. Содержит информацию о наличии docker-compose.yaml и Dockerfile - файлов, а также сервисам, описанным внутри docker-compose. Мы видим, что в docker-compose описаны конфигурации для mysql и postgres сервисов.
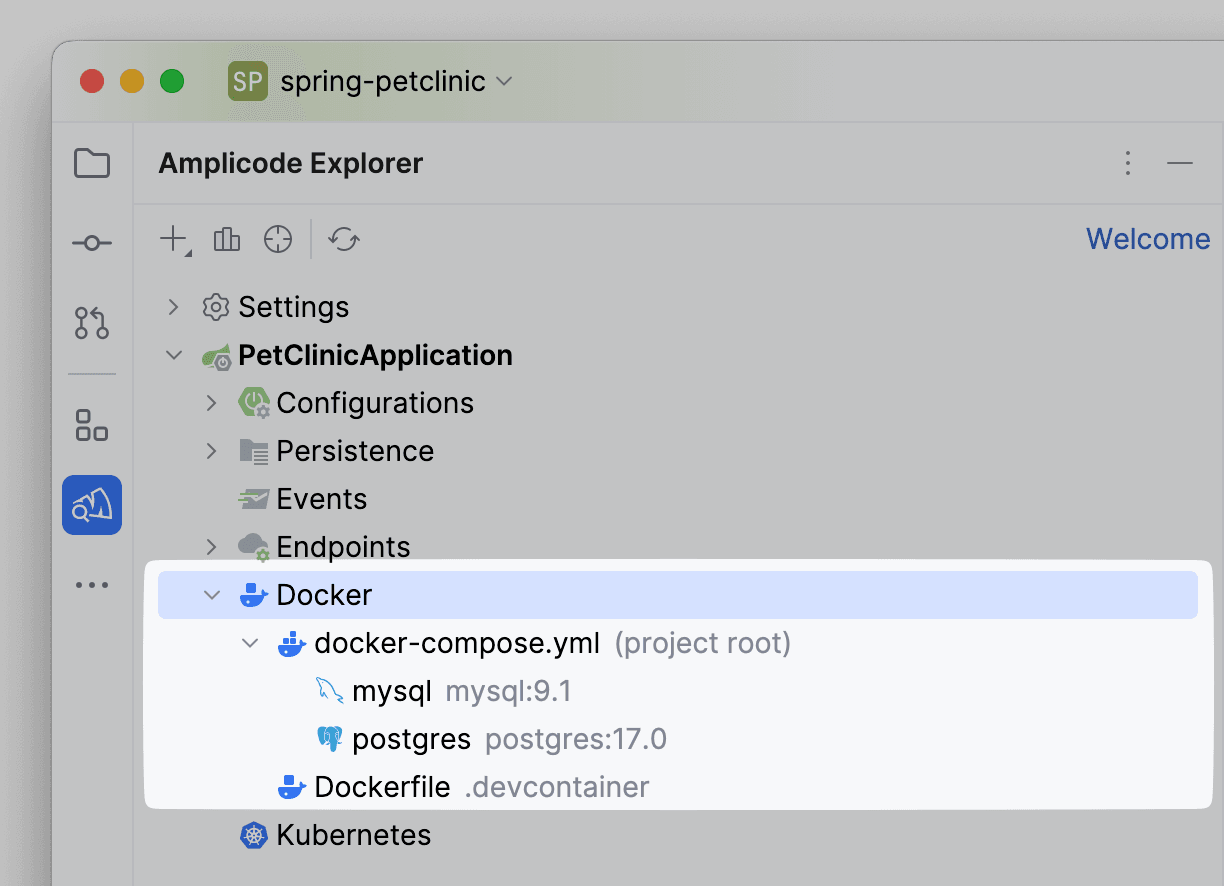
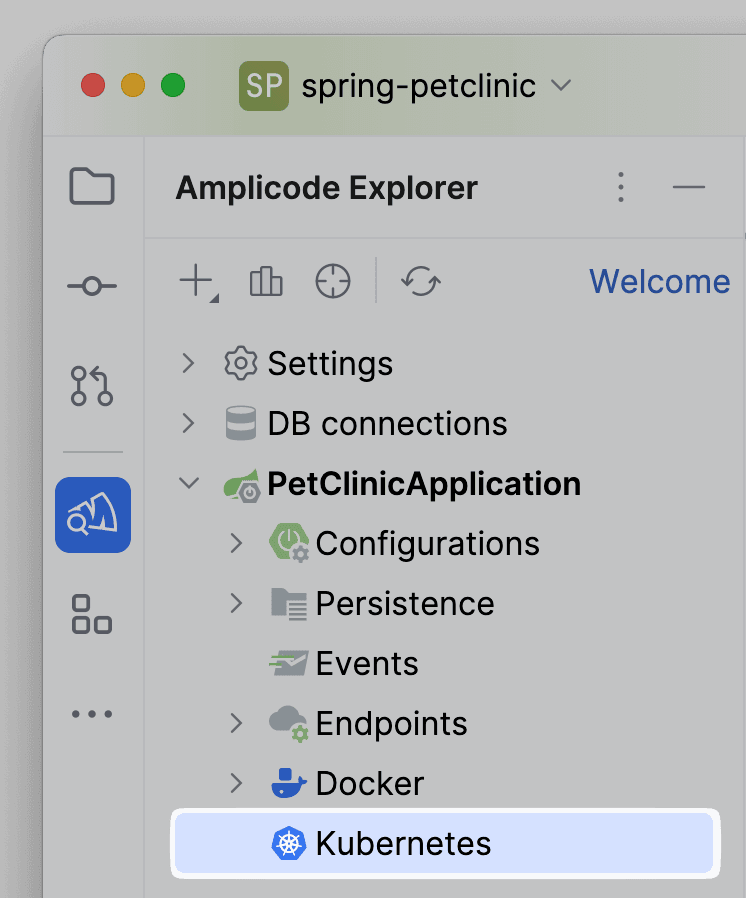
- Kubernetes. Блок с описанием информации, относящейся к файлам Kubernetes. Их в проекте нет.
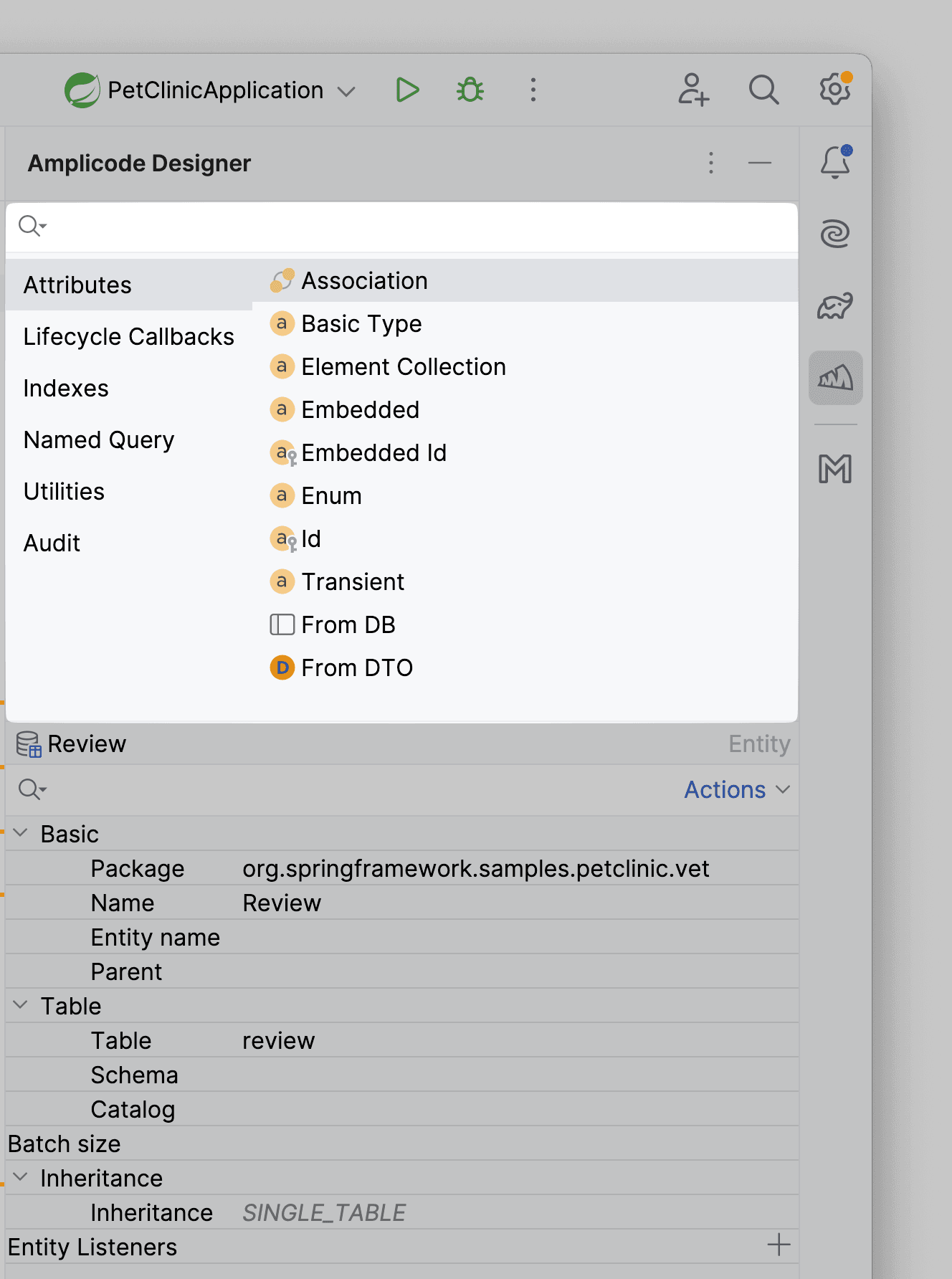
Шаг 2: Панель Amplicode Designer
Amplicode Designer — инструмент для работы с кодом. Панель разделена на две ключевые зоны: палитру и инспектор.
Палитра, расположенная в верхней части, позволяет выполнять различные действия с текущим файлом. Например, добавление базовых, ассоциативных атрибутов для класса-сущности.
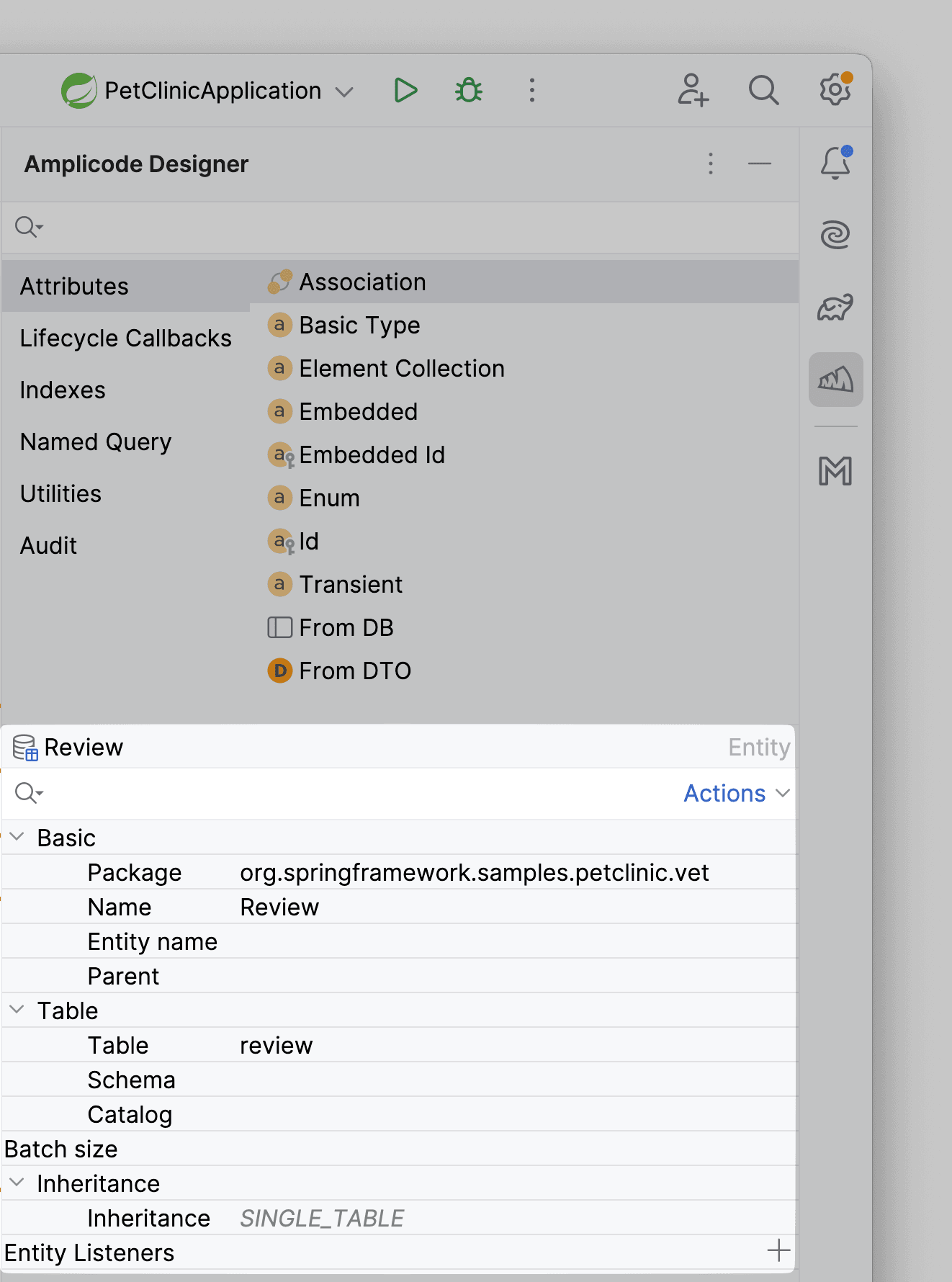
Инспектор — раскрывает всю информацию о конкретном элементе в файле. Установив курсор на поле домена, вы сможете задать его свойства, настраивая все так, как требуется вам.
Так как Amplicode Designer предназначен для взаимодействия с файлом, который открыт в текущий момент, нам понадобится открыть один из таких файлов.
Откроем доменный класс. Например, Owner. В правой части интерфейса нас встречает панель.
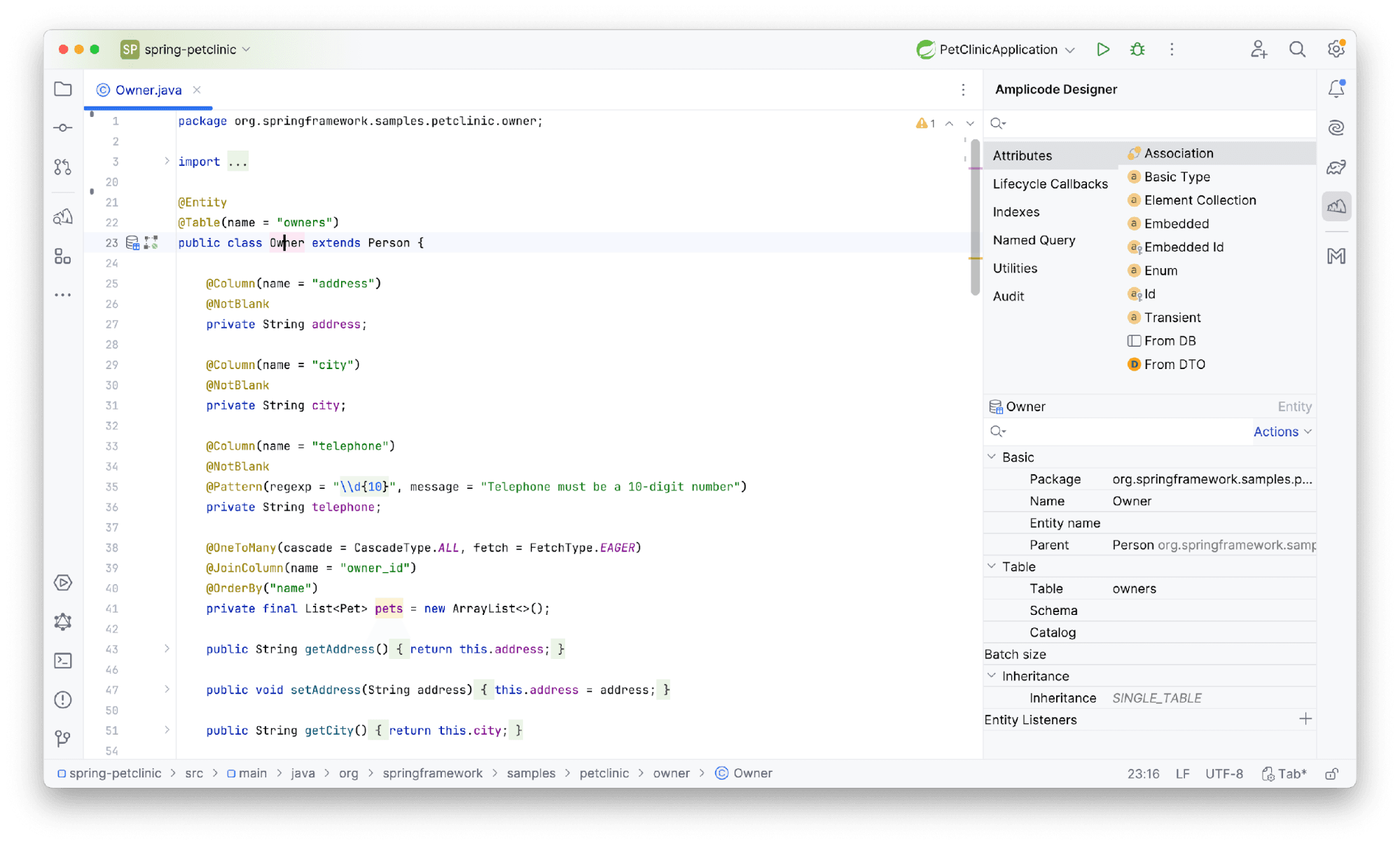
Как было упомянуто выше, палитра предлагает набор действий для всего файла: добавление атрибутов, Id, Lifecycle Callbacks и все то, что свойственно именно для сущности.
Инспектор же в свою очередь позволяет настраивать конкретное место в файле. В данном случае мы можем сконфигурировать поле сущности, задав настройки валидации, уникальность и т.д.
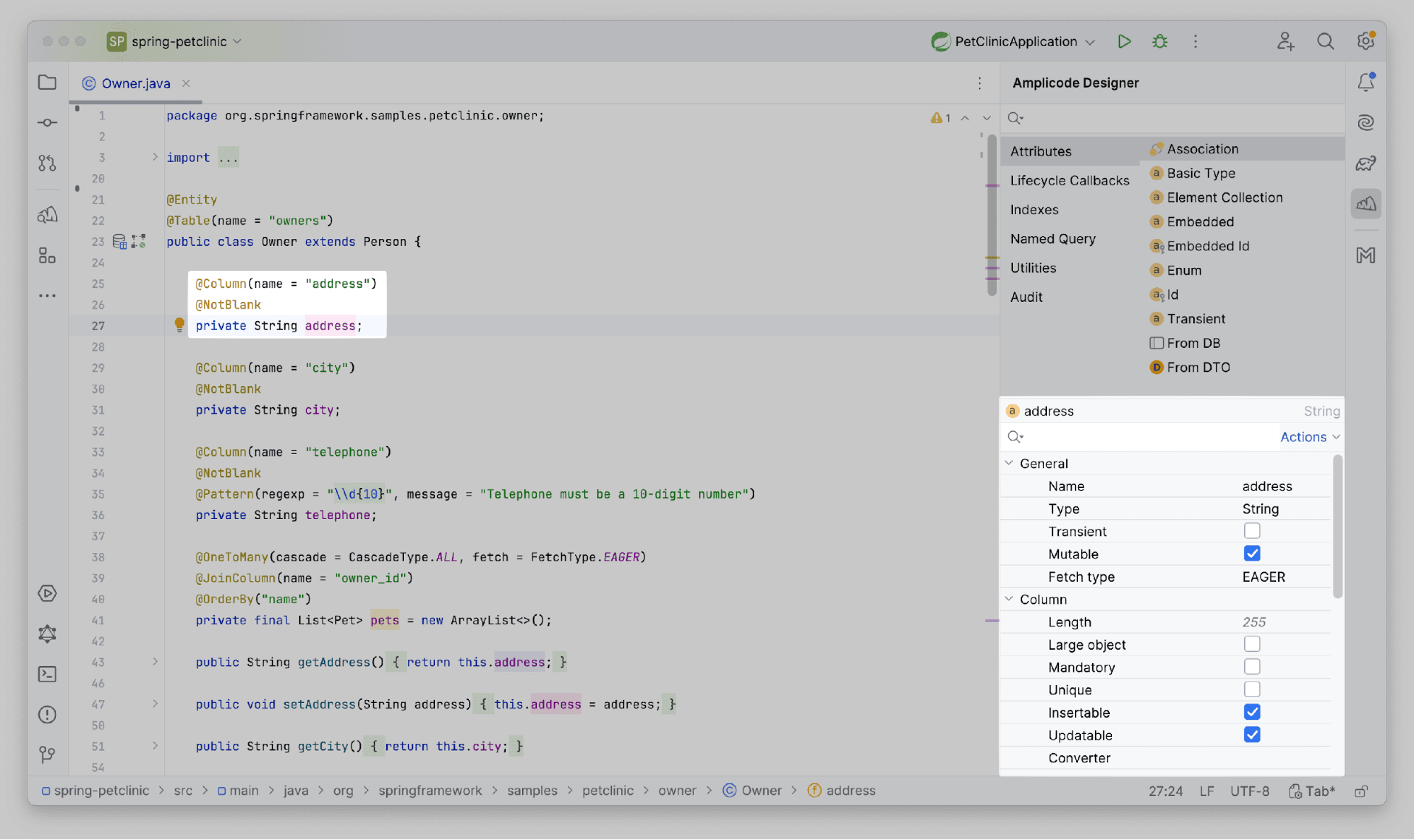
Попробуйте заглянуть в другие файлы проекта и исследовать, как меняется содержимое панели в зависимости от контекста. Возможно, вы обнаружите новые возможности Amplicode Designer, которые помогут вам еще эффективнее управлять структурой и настройками файлов.
Шаг 3: Панель Bean Navigation
При работе с классом-бином, компонентом, нам доступна панель Bean Navigation, которая нужна для анализа зависимостей. Здесь вы найдете полный список всех мест в проекте, где данный бин был заинжектирован.
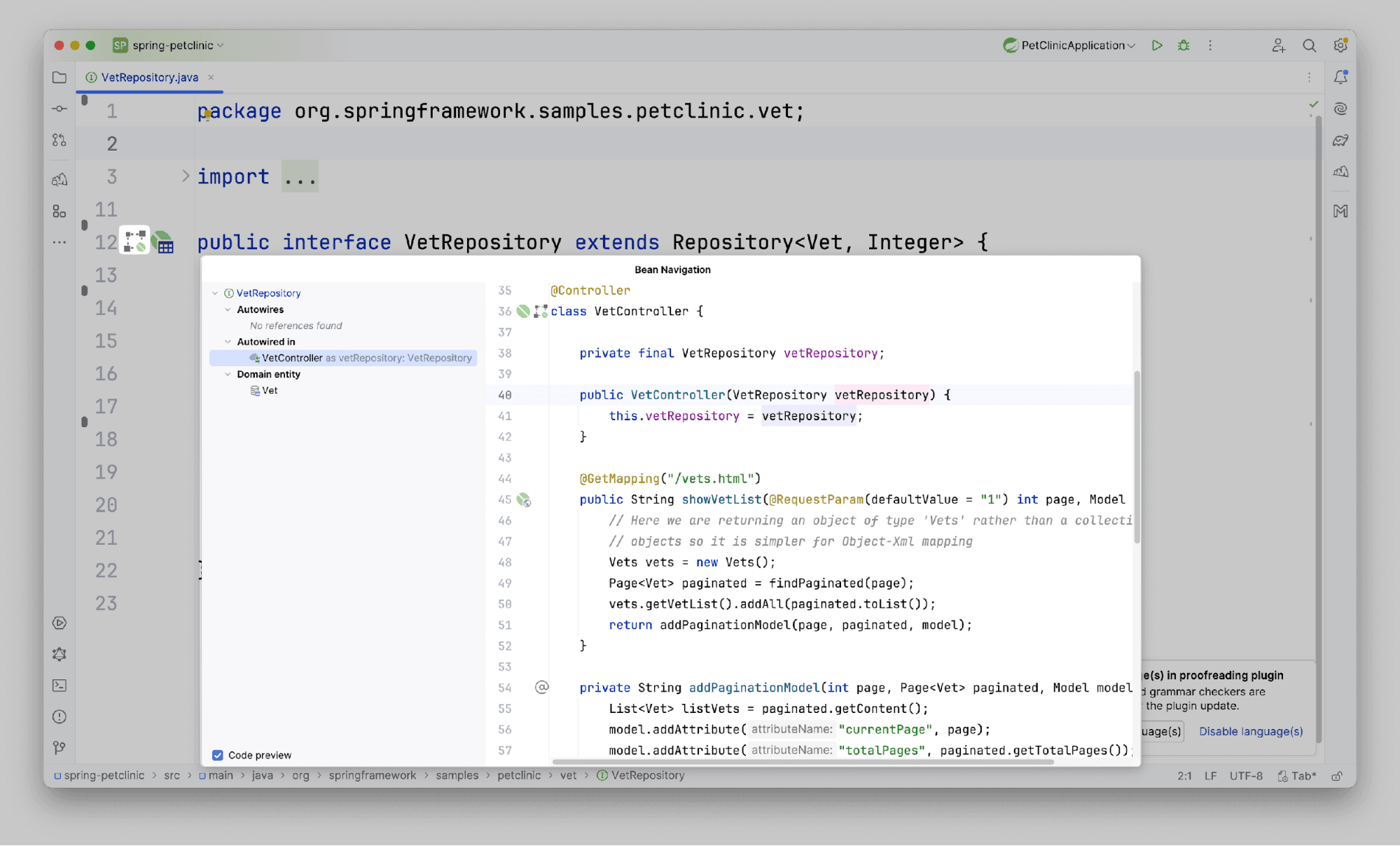
Попробуйте открыть любой бин и воспользоваться этой панелью: одним кликом вы сможете мгновенно переместиться к месту его инжектирования и глубже разобраться в логике его использования.
Добавляем новую сущность
Amplicode позволяет автоматизировать генерацию boilerplate кода. На данном этапе нам предстоит доработать приложение, но не написав ни одной строки boilerplate кода.
Процесс расширения модели данных приложения довольно ясен: создаем сущности, навешиваем @Entity, пишем репозитории, добавляем атрибуты в модель, а потом вручную создаем DTO: копируем поля, убираем ненужные, если не хотим отдавать их наружу. Затем неизменно идет этап поиска правильной конфигурации маппинга. А еще есть сервисы, контроллеры и много всего, за что мы так любим Spring, но не boilerplate код.
Конечно, знать все это полезно, но еще полезнее экономить усилия, а освободившееся время потратить на что-то действительно новое и полезное, например, на доработку текущей или создание новой бизнес-логики. Так давайте попробуем упростить процесс. Возьмем наш тестовый семпл проект Spring PetClinic, добавим в нее новую модель, создадим репозиторий, DTO и все, что нужно, чтобы отдать первую запись наружу.
Шаг 1. Создание сущности
На текущем шаге наша задача - пройти путь от добавления сущности до написания API. На панели Amplicode Explorer можно заметить плюсик, по нажатию на который появится выпадающий список со всеми поддерживаемыми для добавления действиями. Здесь можно добавить новую конфигурацию, DTO, datasource, Spring конфигурацию и многое другое. Нас интересует добавление сущности.
Для добавления сущности перейдем в секцию Data → JPA Entity и создайте новую сущность, которая станет частью доменной модели.
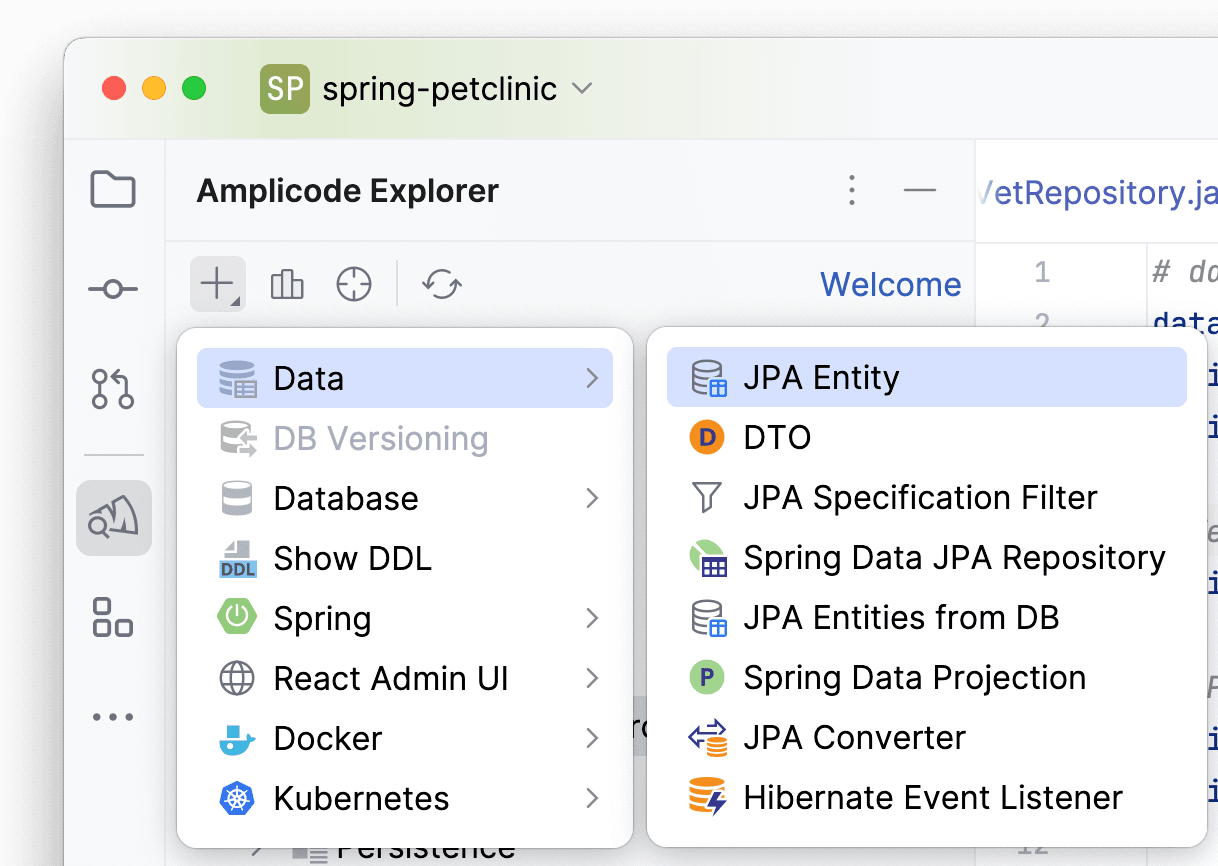
Откроется окно с параметрами для создаваемого класса сущности:
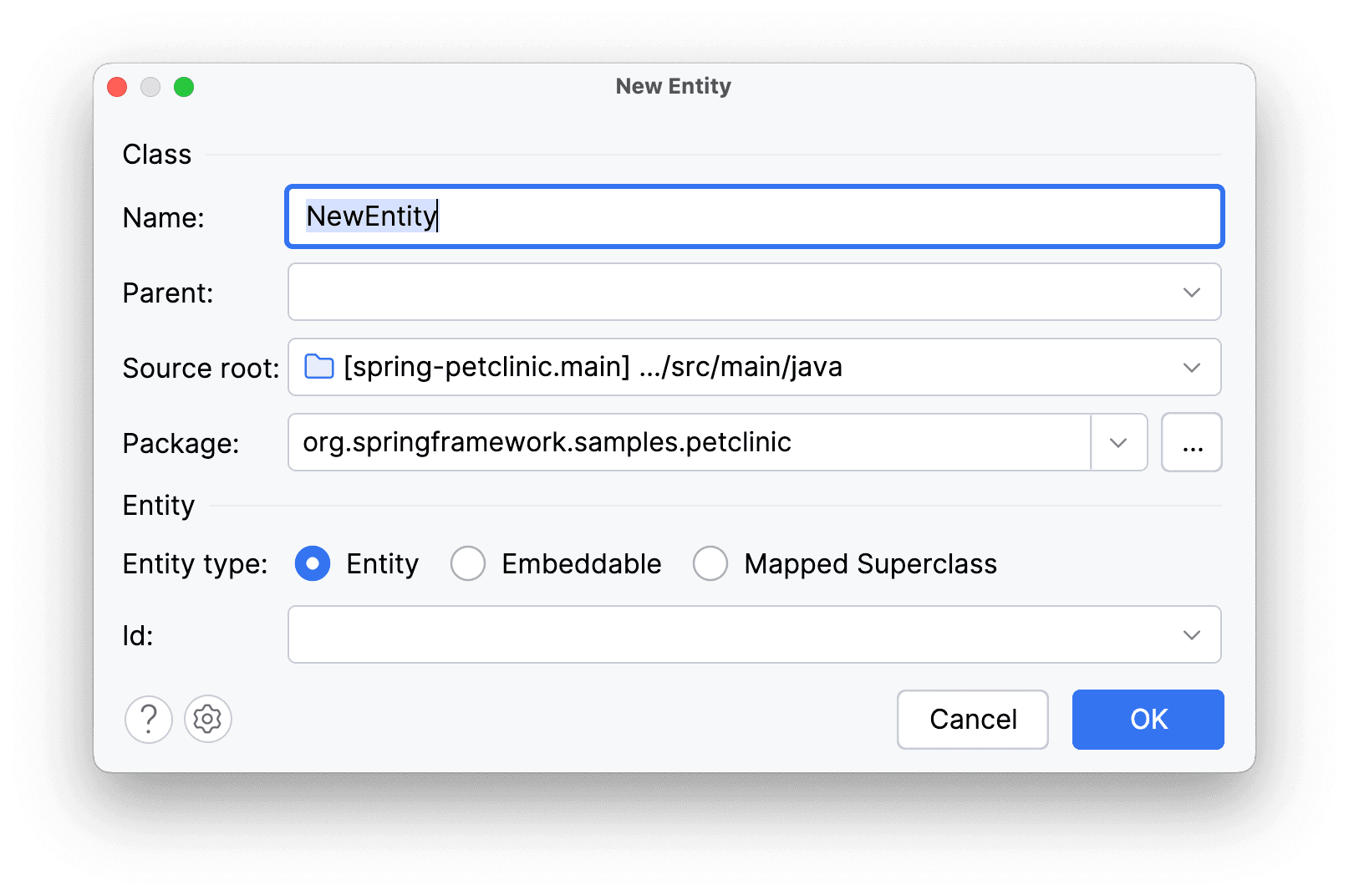
Добавим отзывы о работе ветеринаров. Сущность - Review, id – Long, тип генерации Id – Identity. Заполним параметры:
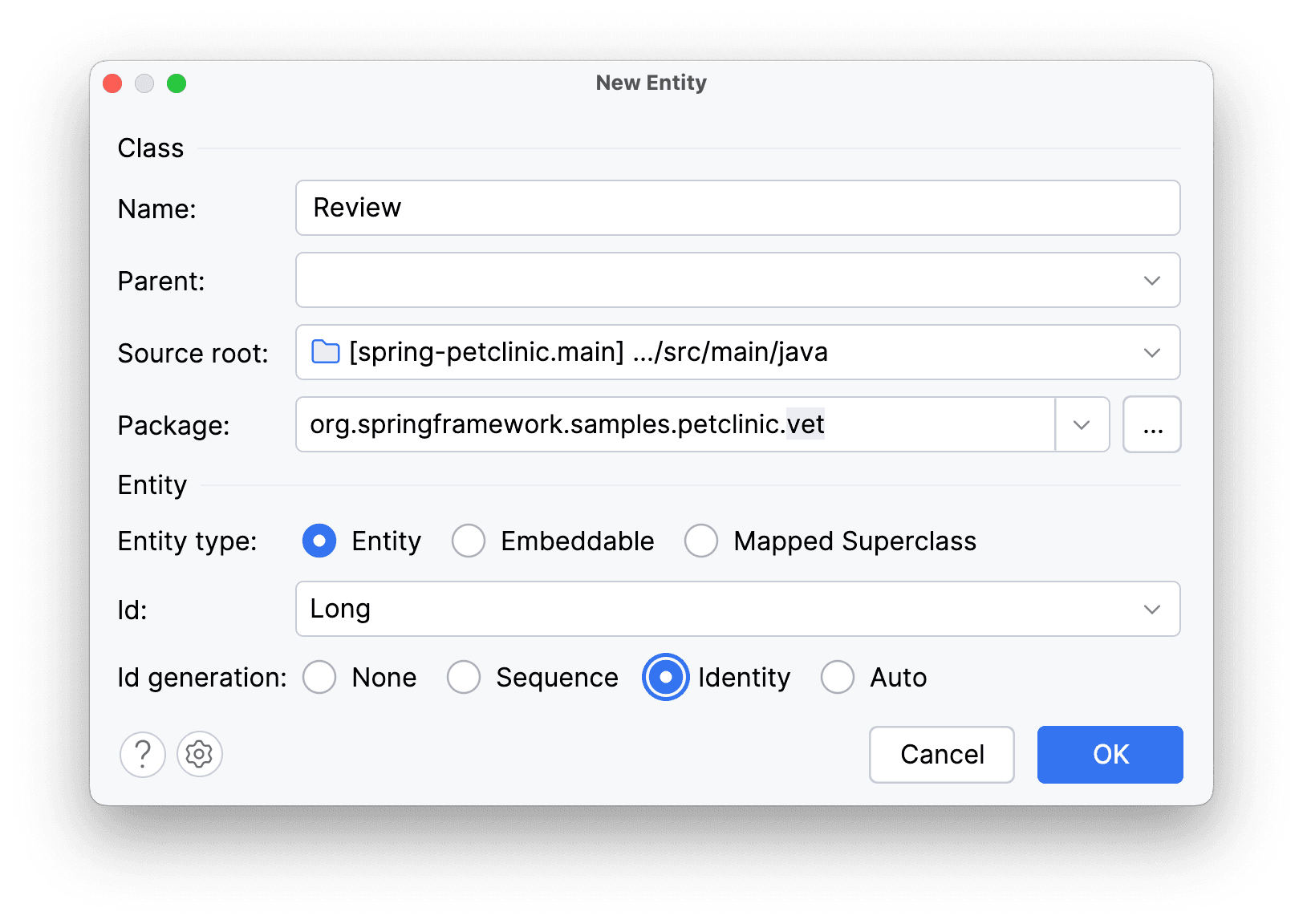
Amplicode создаст класс сущности:
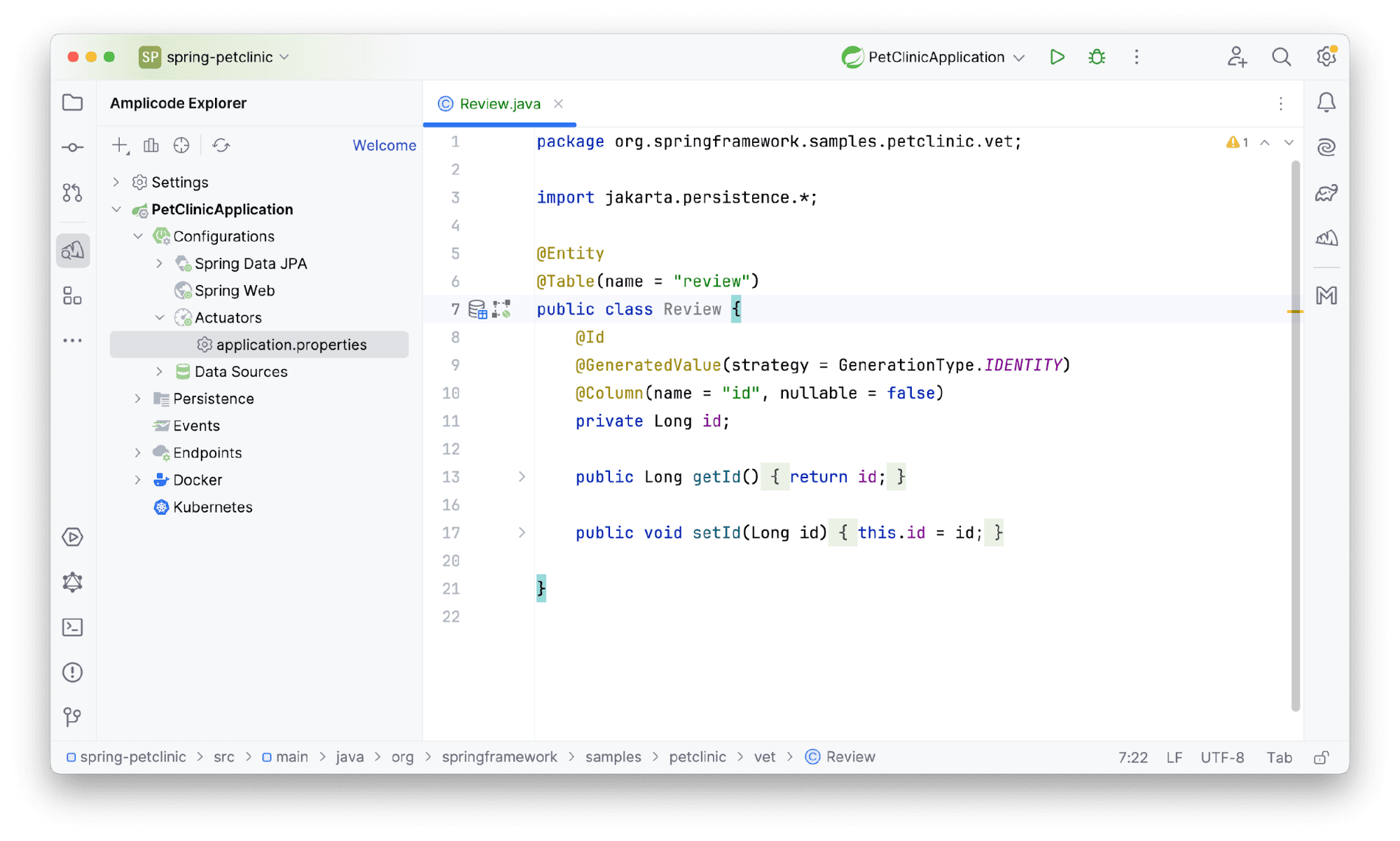
Но какой отзыв лишь с одним айдишником? Конечно, добавим в него поля. Для этого мы можем воспользоваться уже знакомой нам панелью Amplicode Designer. Выбираем Attributes –> Basic Type
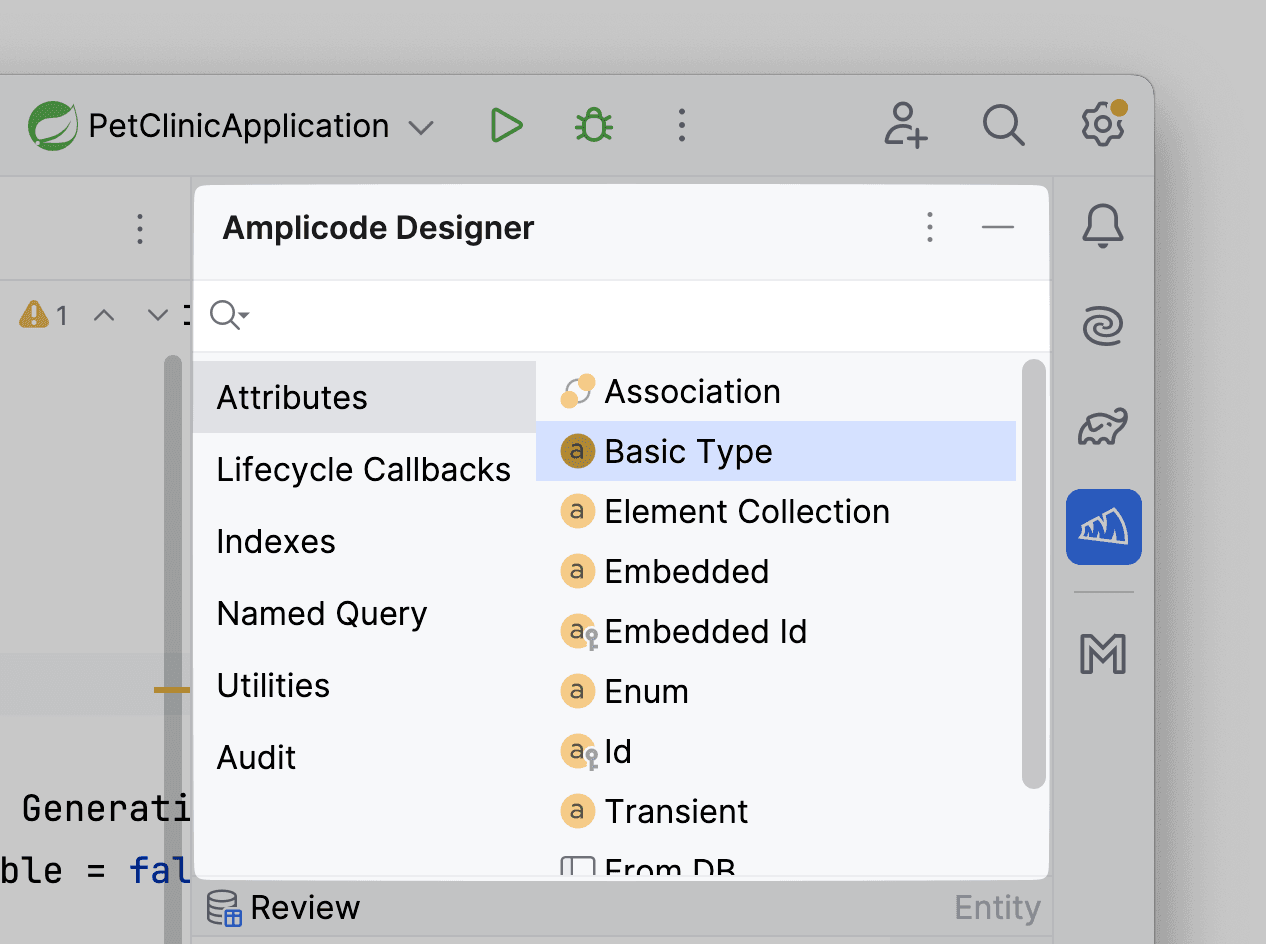
В отзыве почти всегда (а точнее, всегда!) должен быть текст отзыва. Поэтому добавим текстовое поле с комментарием.
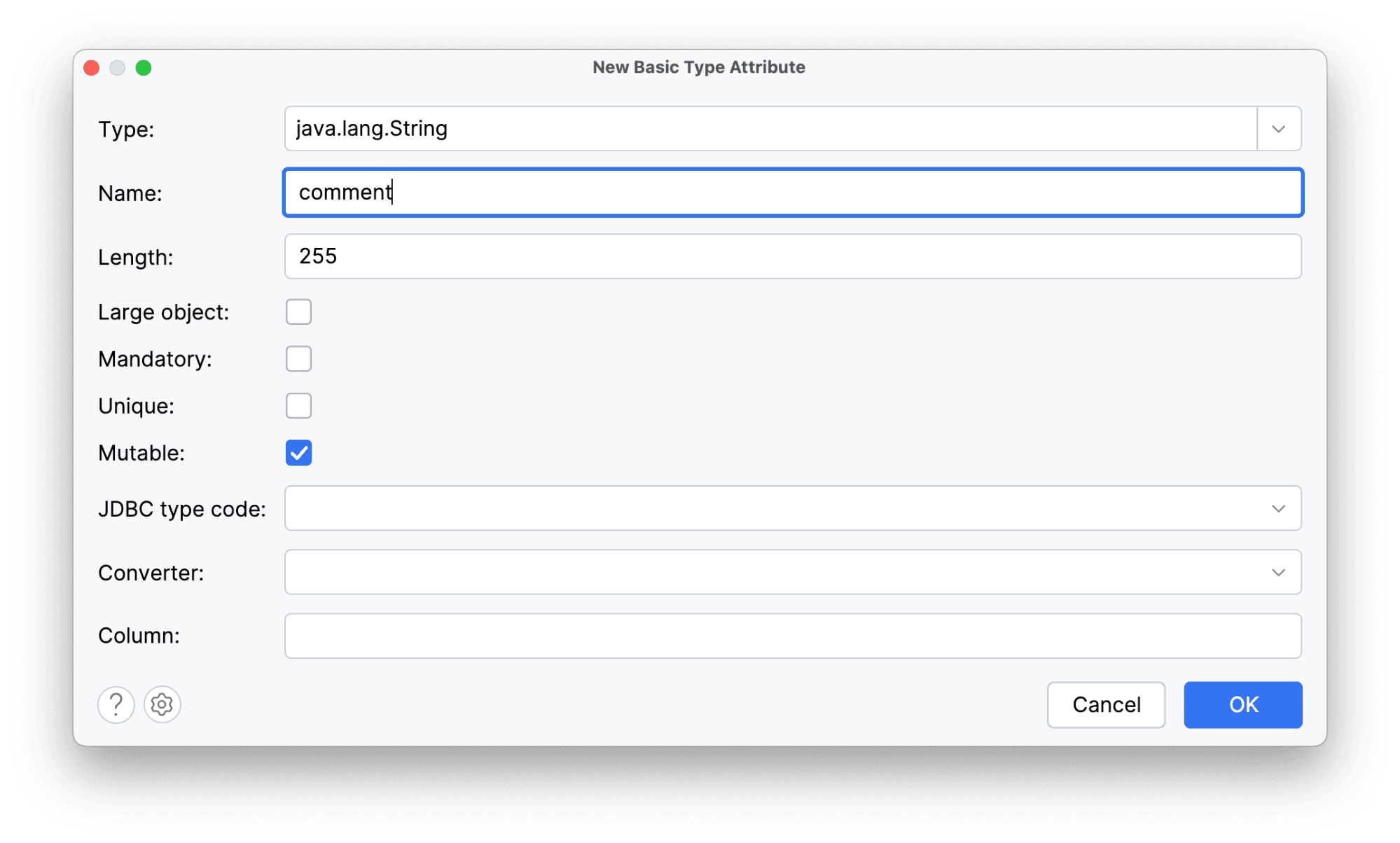
Здесь важно отметить, что Amplicode заботится о вашем времени и минимизирует необходимость ручного ввода и лишних кликов. Многие поля уже заполнены значениями по умолчанию, соответствующими лучшим практикам разработки. Такой подход пронизывает все возможности нашего плагина, помогая вам сосредоточиться на главном — создании качественного кода удобно.
Аналогичным образом добавьте поля rating (int), date (LocalDate).
Сверим результат:
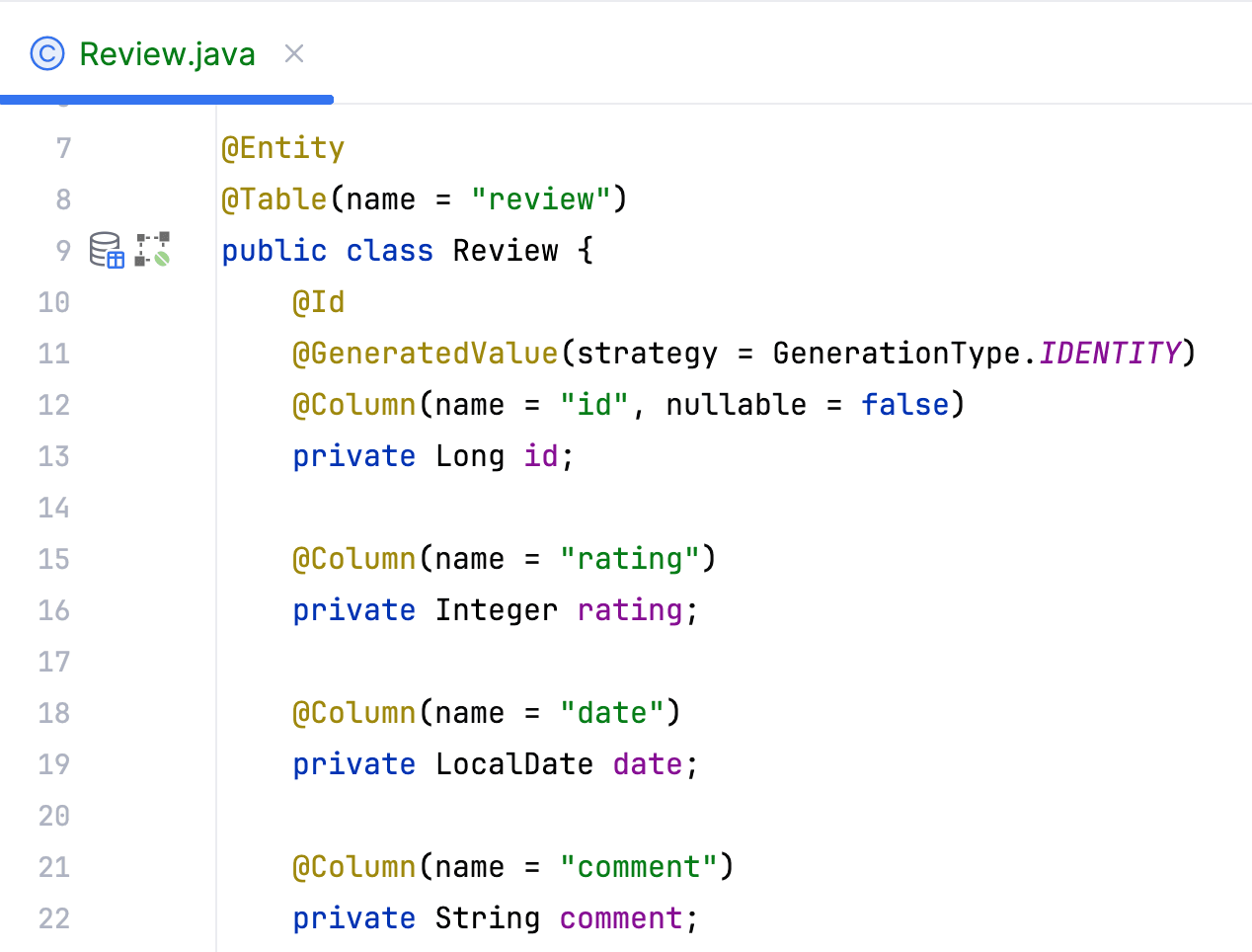
Отзыв так или иначе относится к ветеринару. Так что добавим соответствующий ассоциативный атрибут.
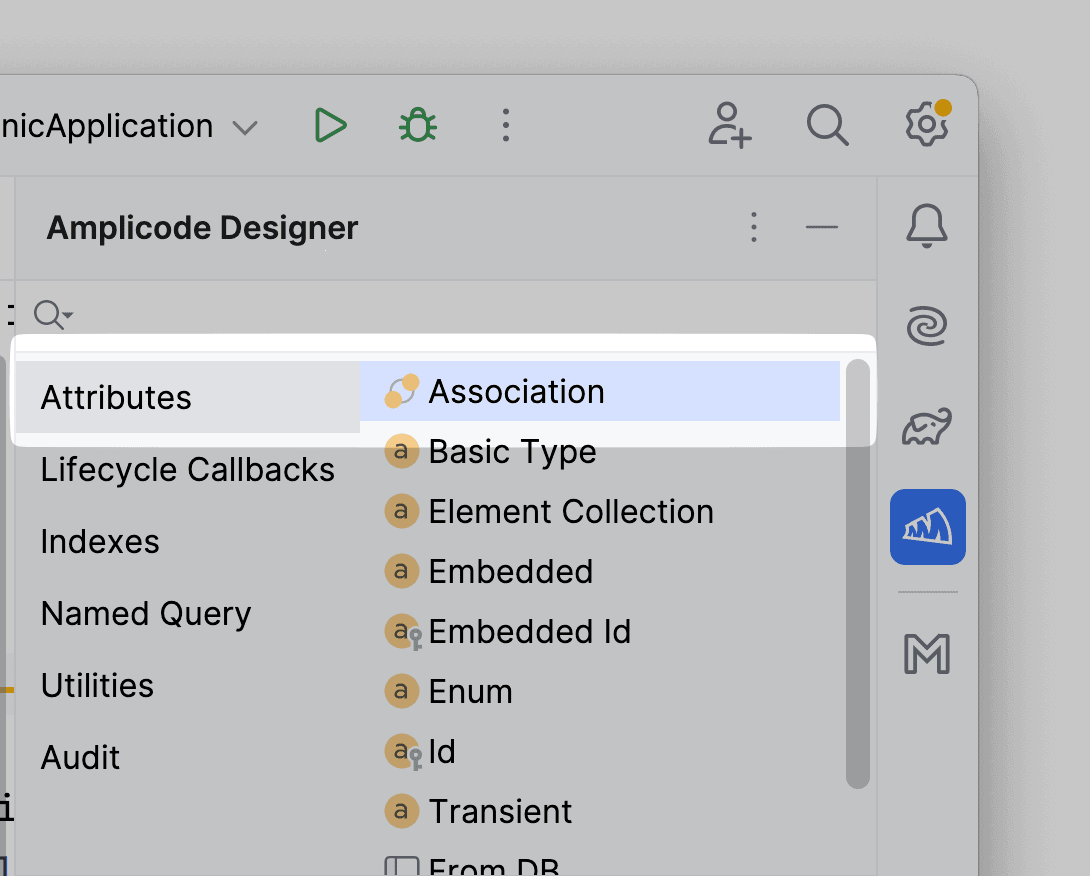
Тип связи @Many to One, тип связи оставим одностороннюю, остальные поля Amplicode заполнил так, как нам и нужно.
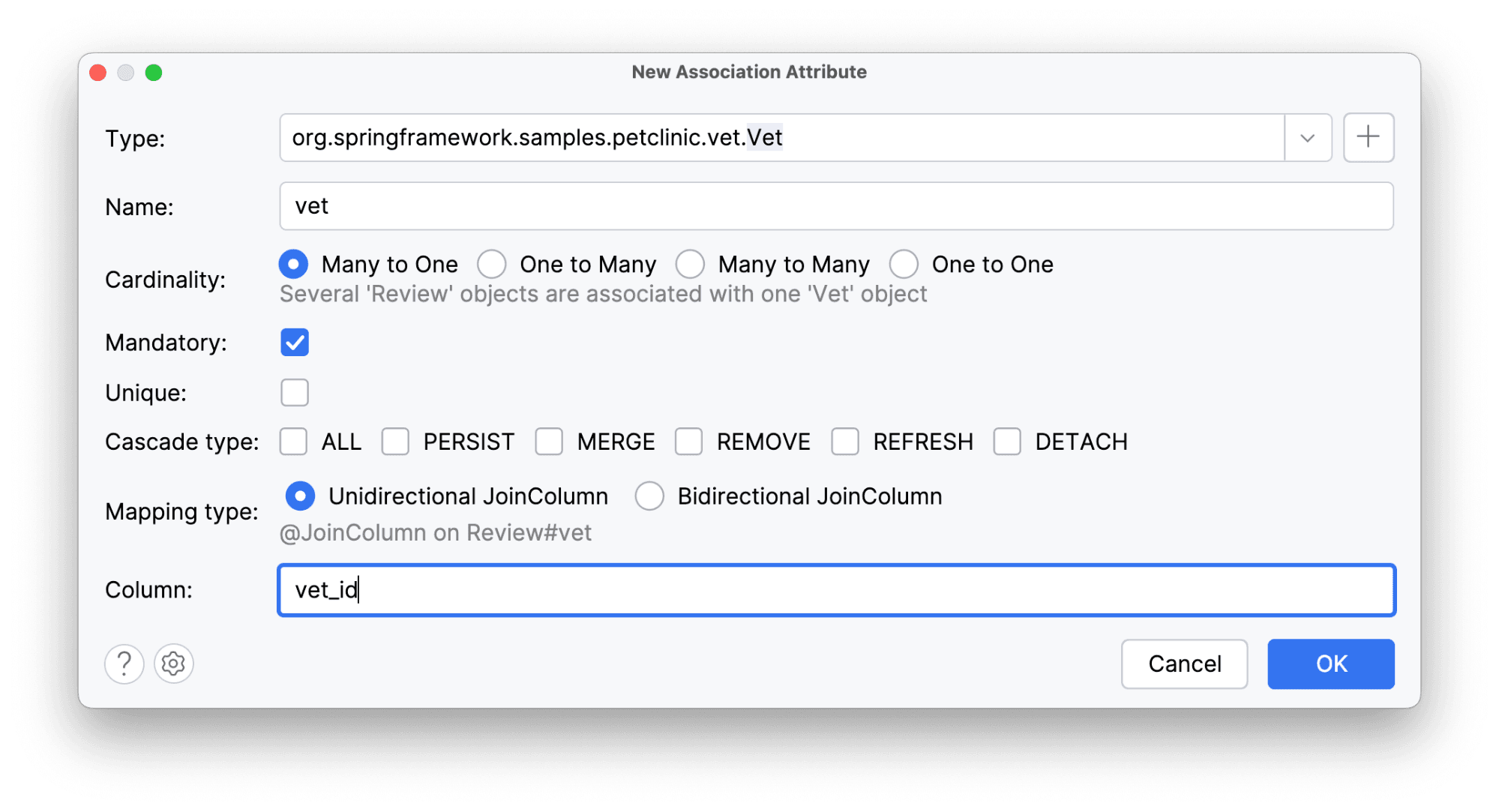
Получаем готовый к использованию доменный класс со всеми необходимыми нам атрибутами.
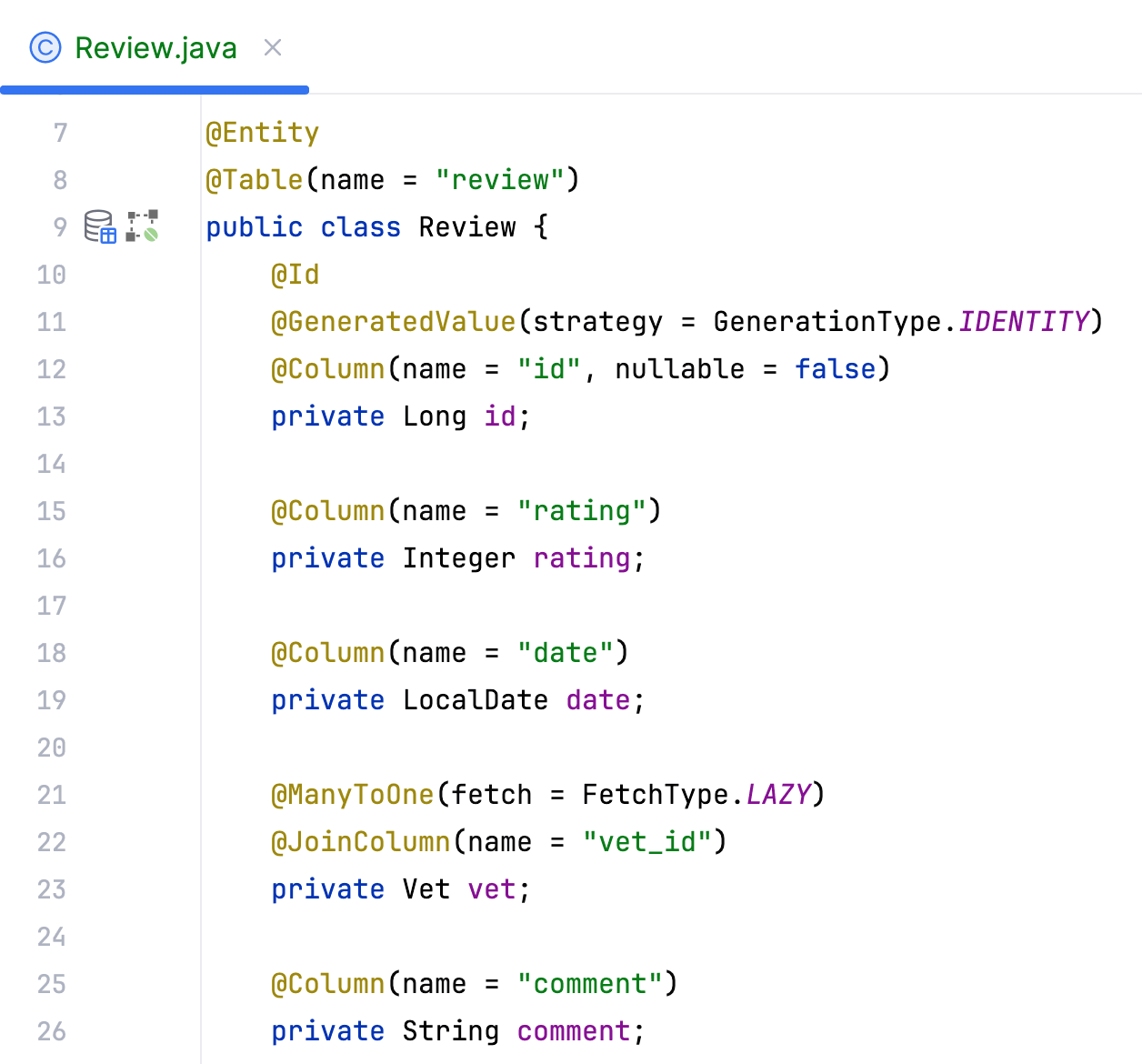
Для работы с данными нам, конечно же, понадобится репозиторий. Создадим его всего за пару шагов: вызовем список действий для домена через Gutter-icon рядом с сигнатурой класса и выберем Create Spring Data Repository.
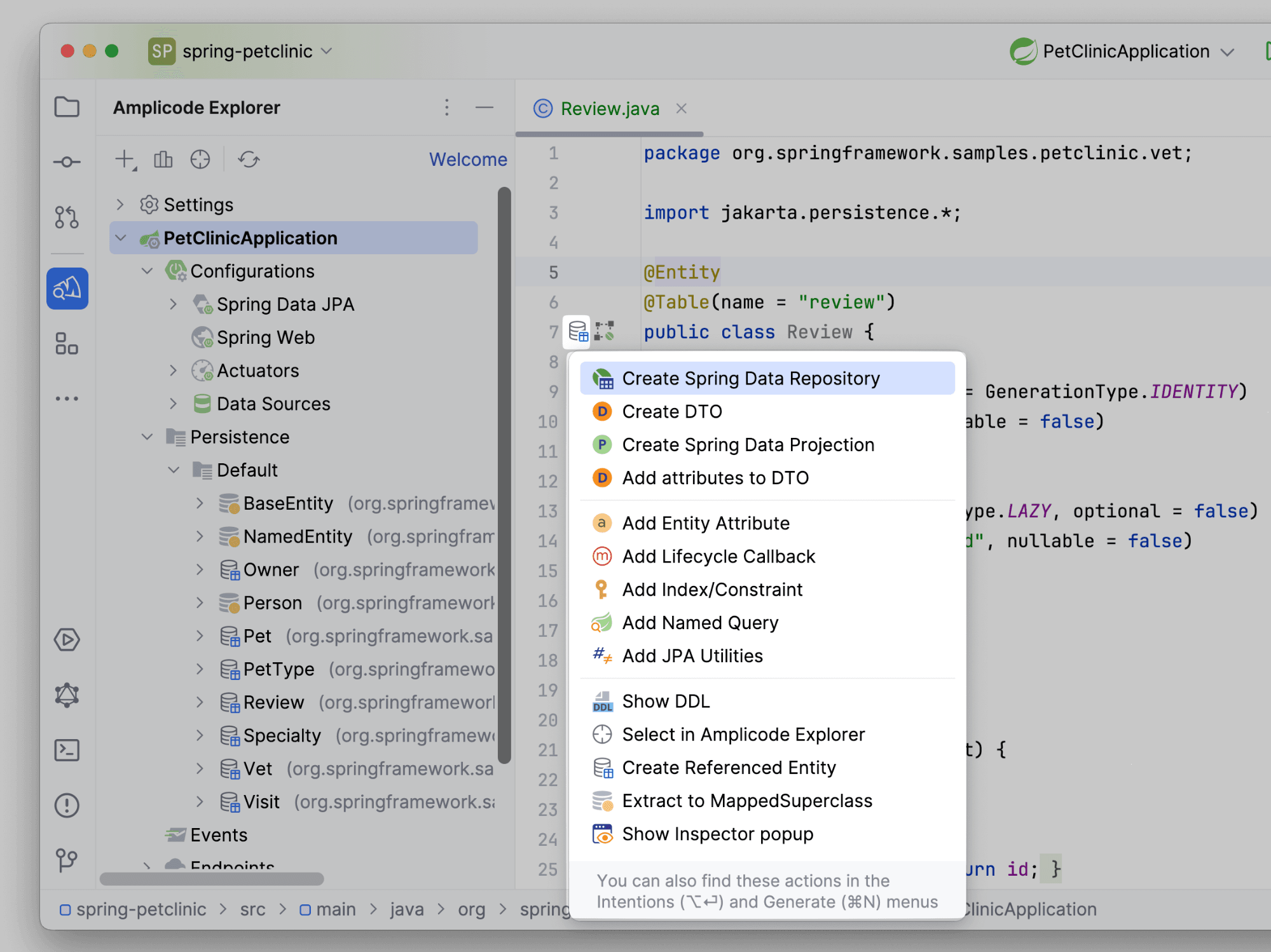
И тут Amplicode будто читает наши мысли. Настройки оставим заполненными по умолчанию:
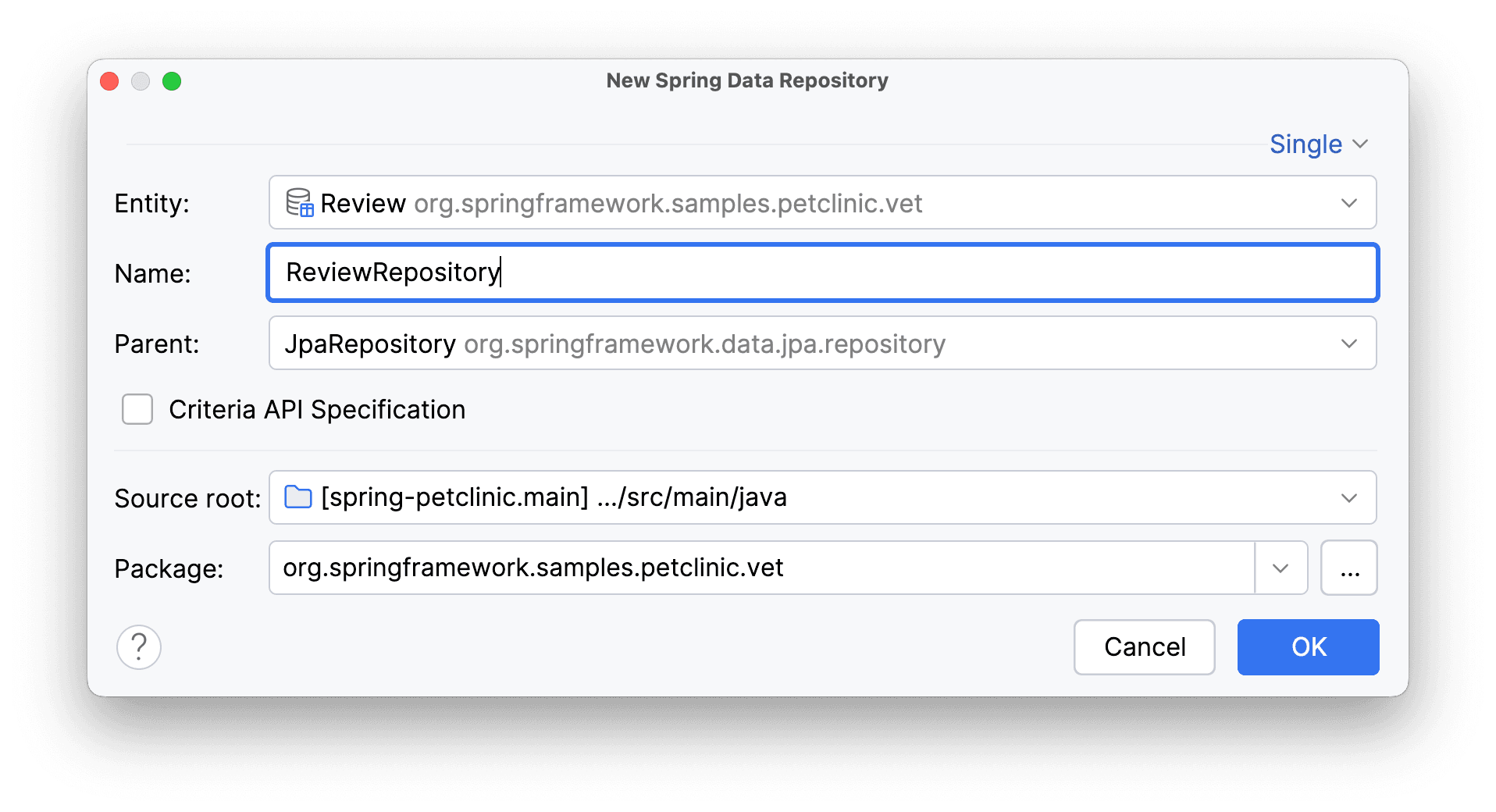
Получаем готовый к использованию репозиторий.
Довольно часто возникает необходимость создать кастомный метод репозитория. С помощью панели Amplicode Designer можно легко добавить метод в интерфейс: для этого раскроем панель и выберем действие Find Collection.
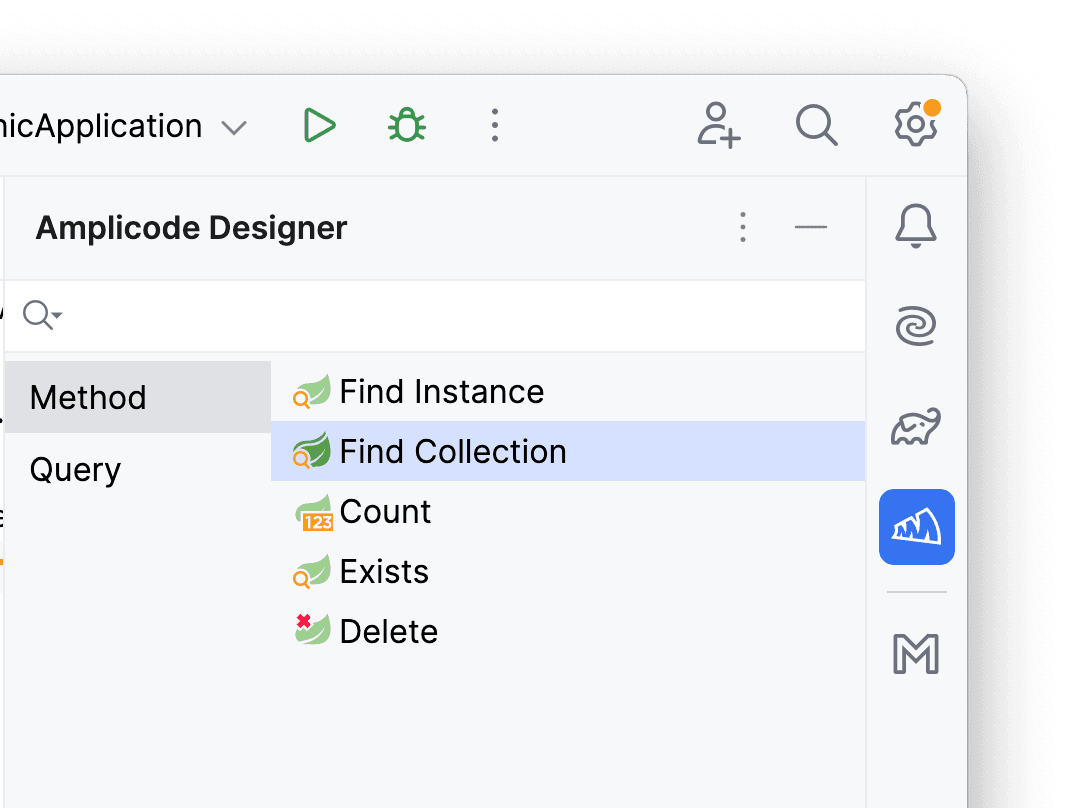
Сформулируем небольшую бизнес-задачу: нужно найти все отзывы по конкретной фамилии ветеринара. В качестве возвращаемого значения оставим обычный список List<Review>, а поле поиска добавим через “+”. В итоге должно получиться следующее:
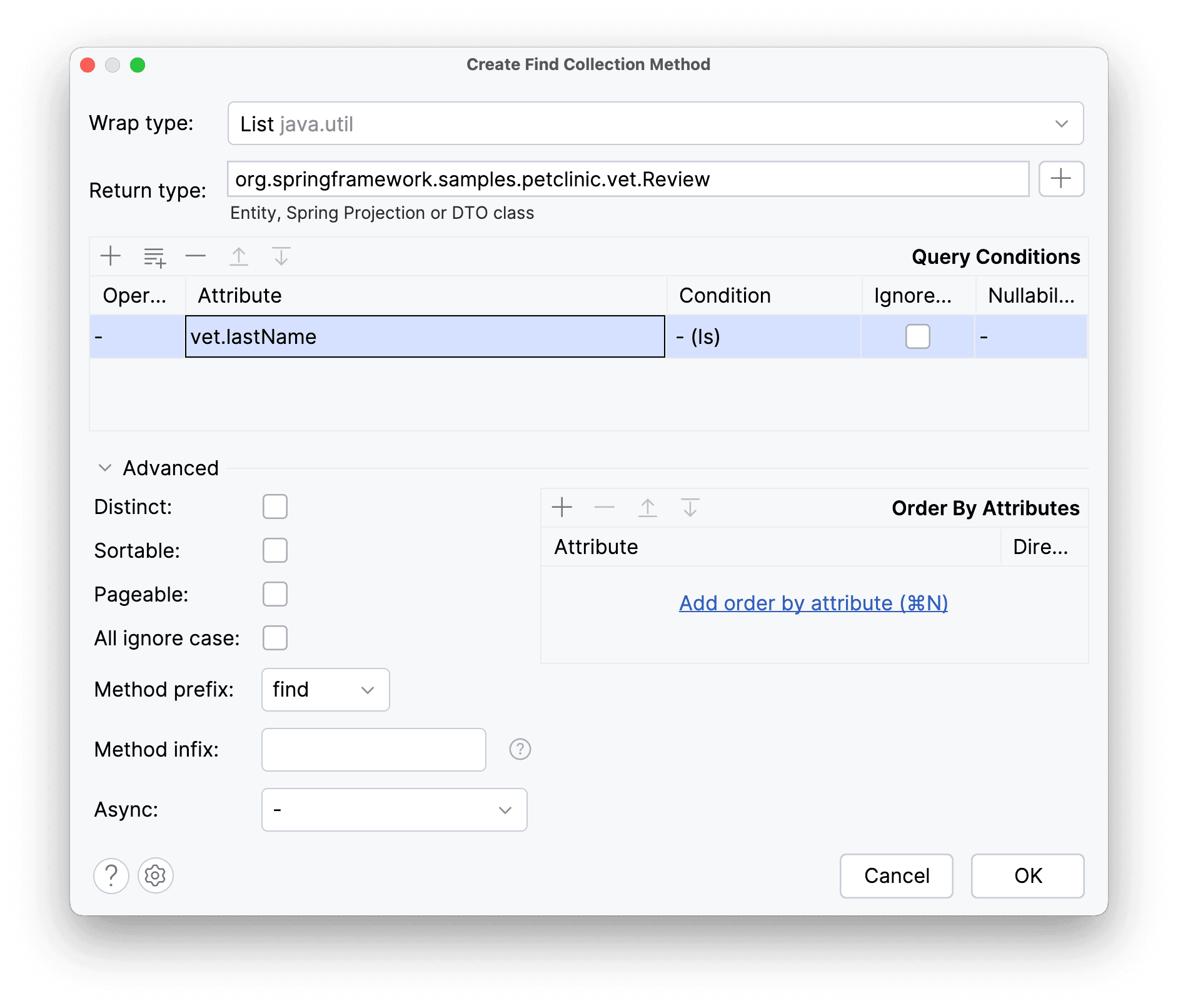
Метод готов:
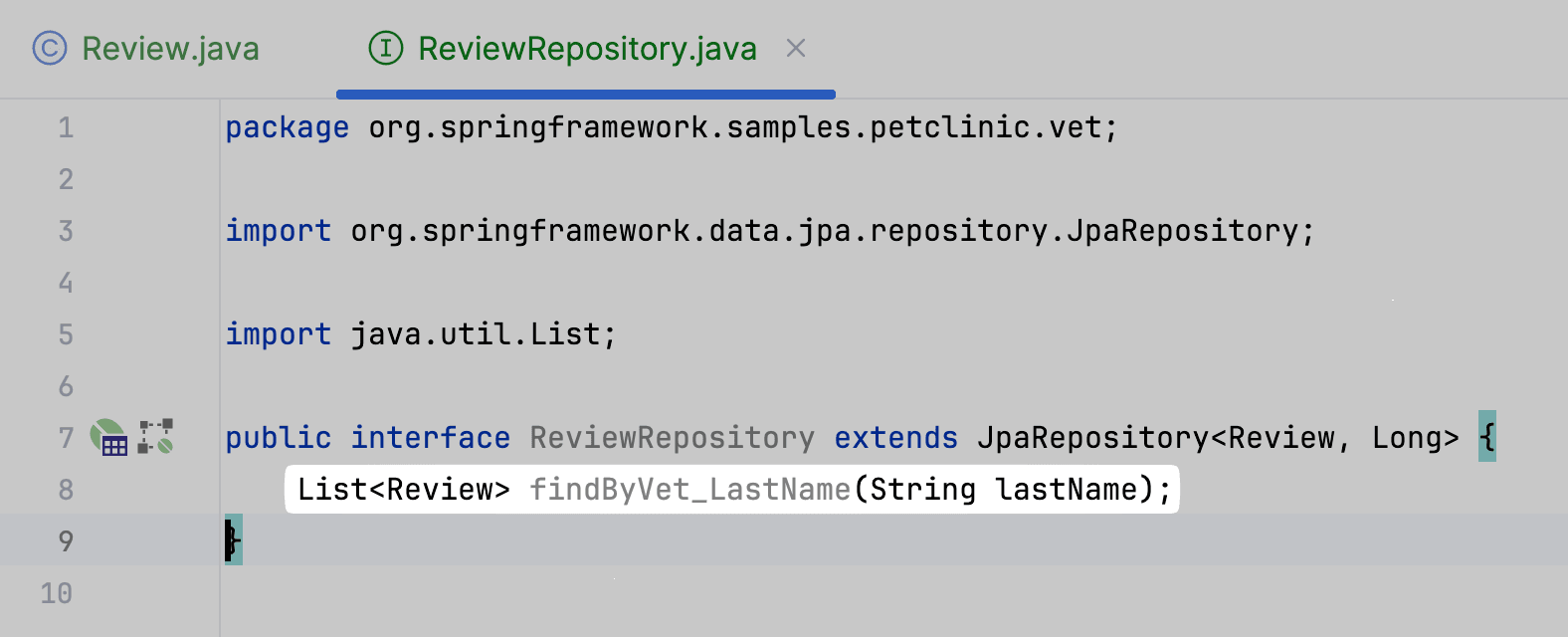
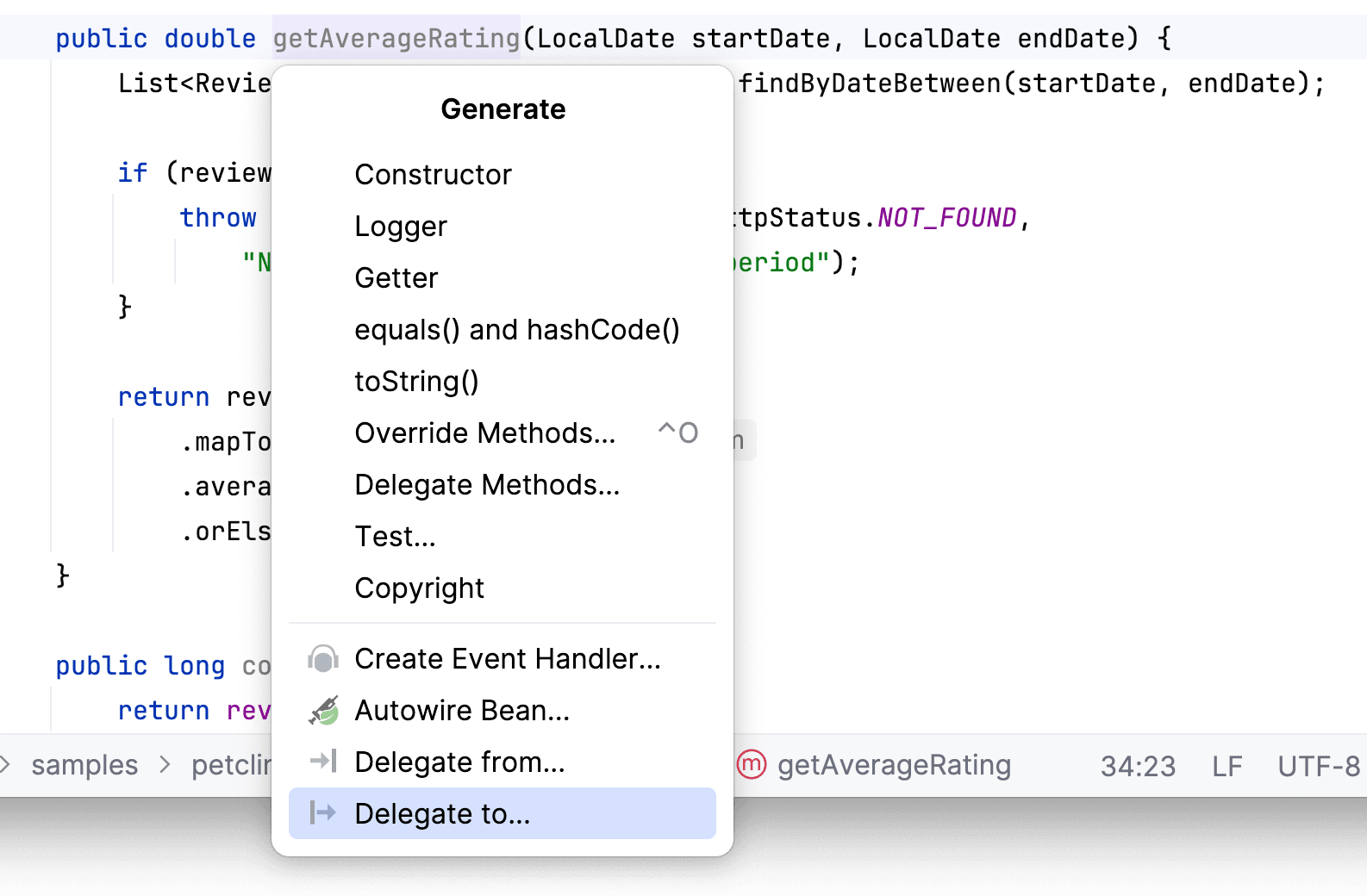
Осталось прокинуть наш метод в сервис. Для этого воспользуемся Gutter icon напротив сигнатуры интерфейса. Выберем действие Delegate to...
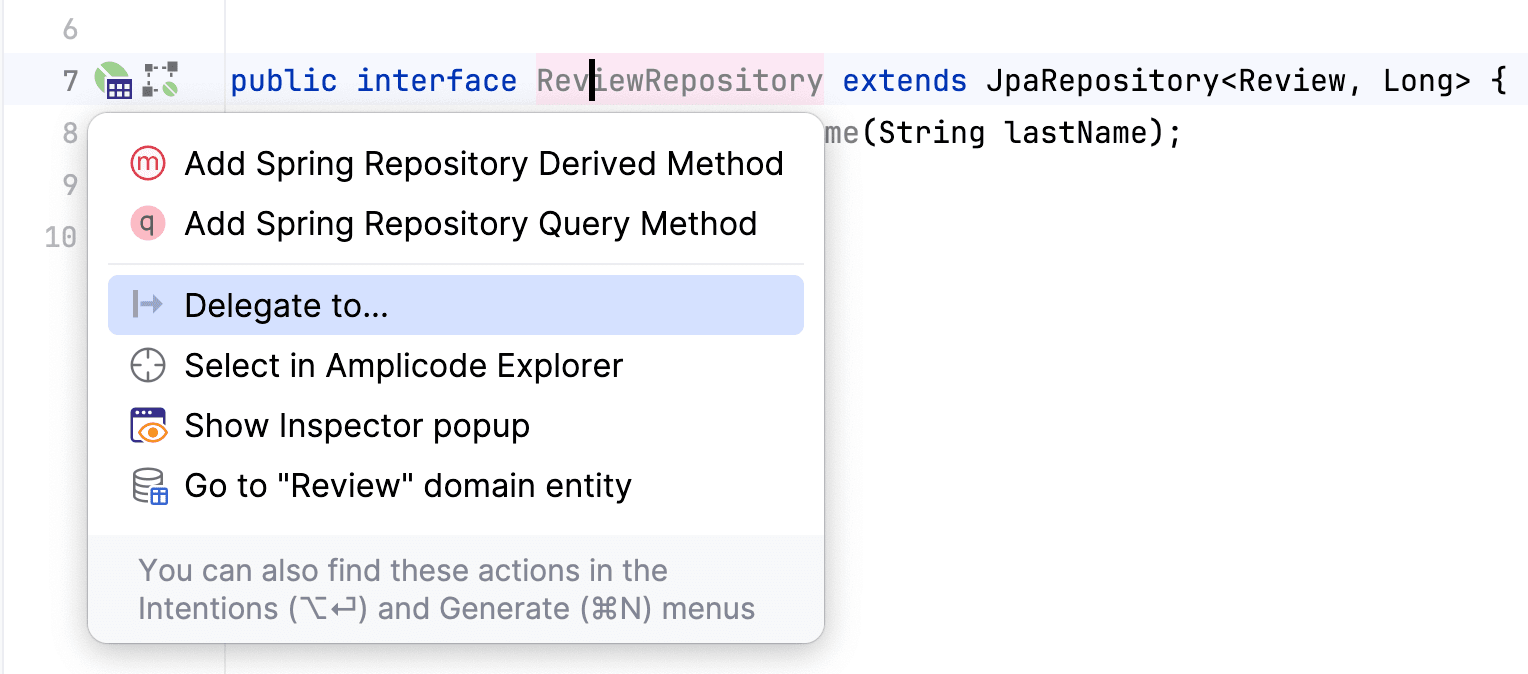
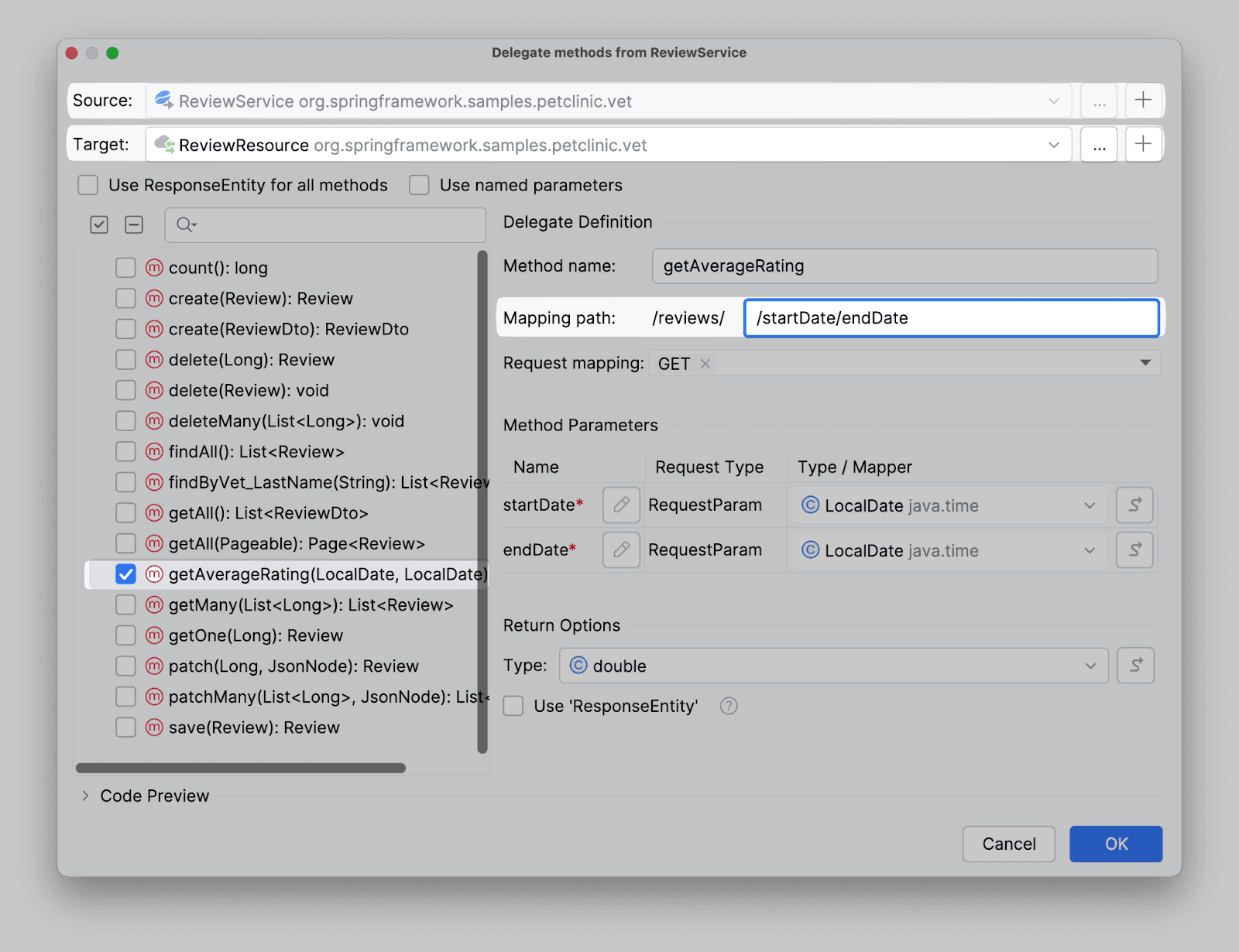
Прямо отсюда мы можем создать сервис для создания сервисного слоя, выбрать методы для делегирования, а также настроить их параметры, если это нужно. Так выглядит окно делегации. В верхней его части расположены поля с источником делегирования, а также с файлом назначения. Слева - список методов, доступных для делегирования, справа - область с настройками конкретного метода. Мы будем делегировать в сервис, но его еще нет.
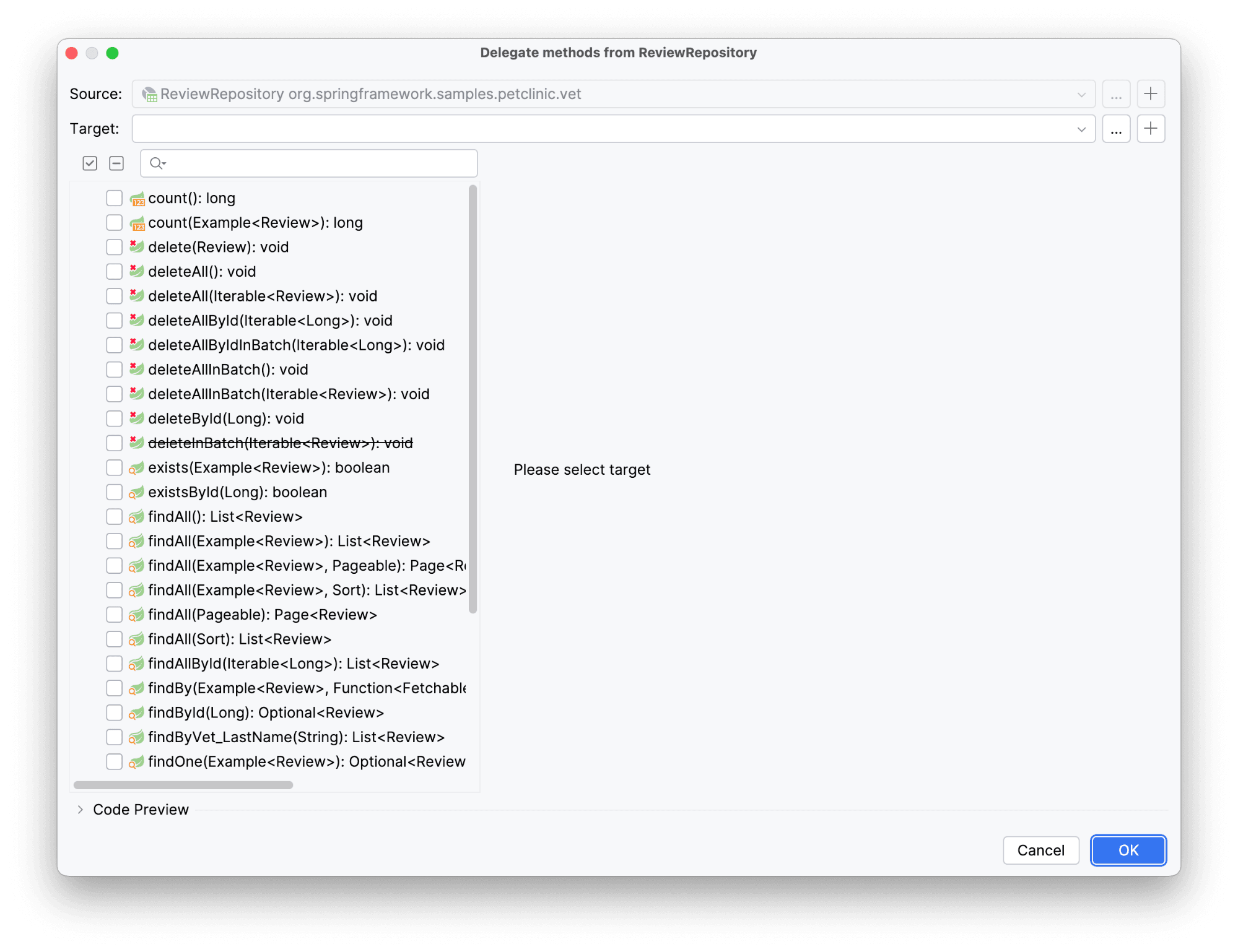
Создадим его:
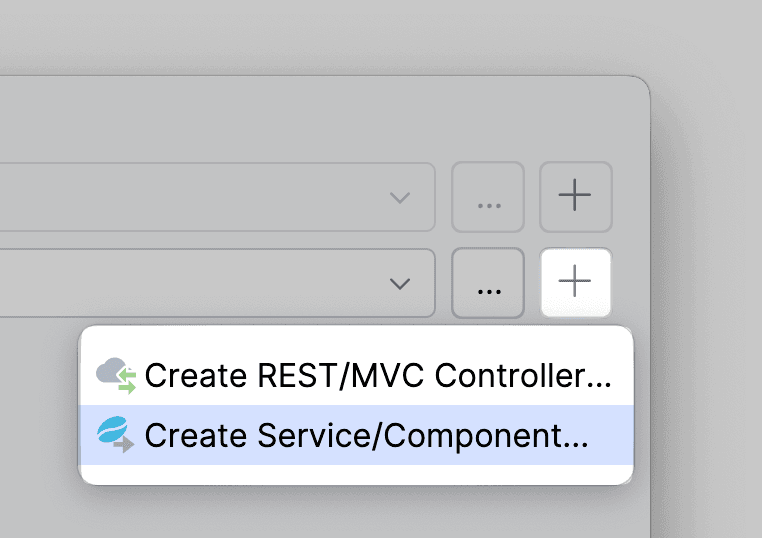
Оставляем поля заполненными по умолчанию. Amplicode сам понимает, в каком пакете мы работаем, какое имя для сервиса подходит больше всего.
Для делегирования выбираем методы count(): long, delete(Review): void, findAll(): List<Review>, findByVet_LastName(String): List<Review>, save(Review): Review
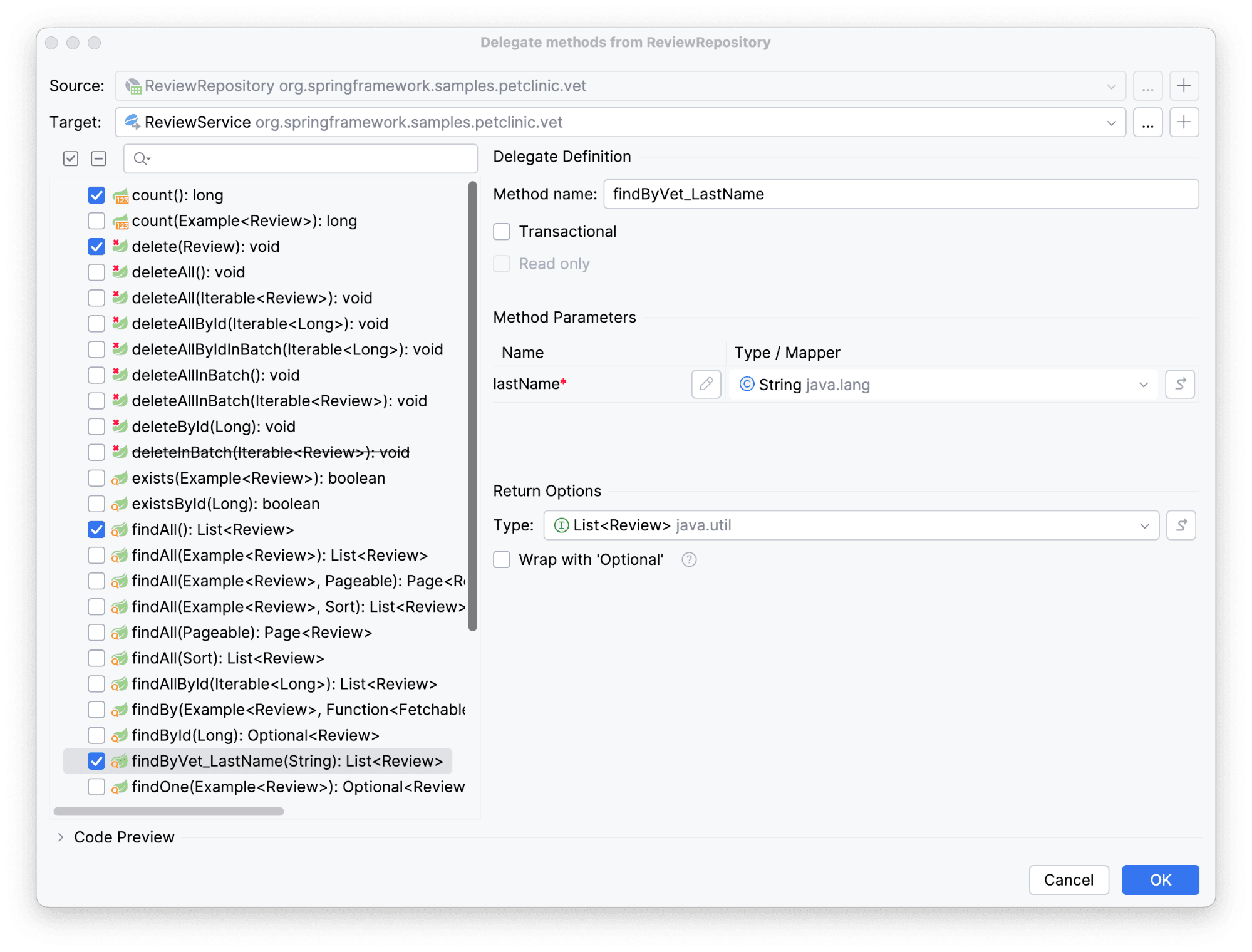
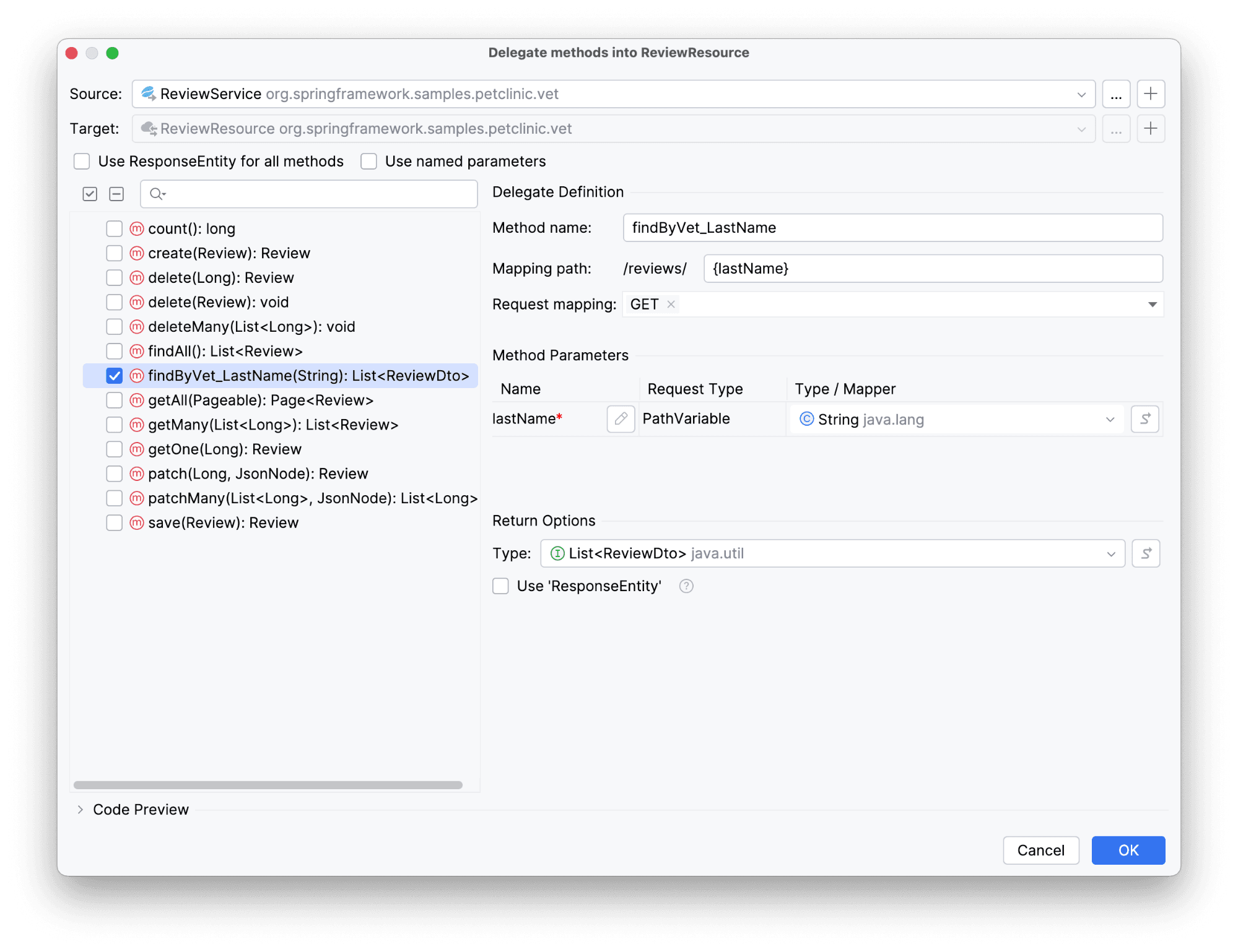
Выберем метод findByVet_LastName(String): List<Review> для более детальной настройки. Все мы знаем, что по правилам хорошего тона метод должен вернуть DTO. Поэтому слегка изменим возвращаемое значение.
Для начала убедимся, что требуемого нам типа возвращаемого значения нет:

Значит, займемся созданием DTO. Перед созданием настраиваем маппинг.
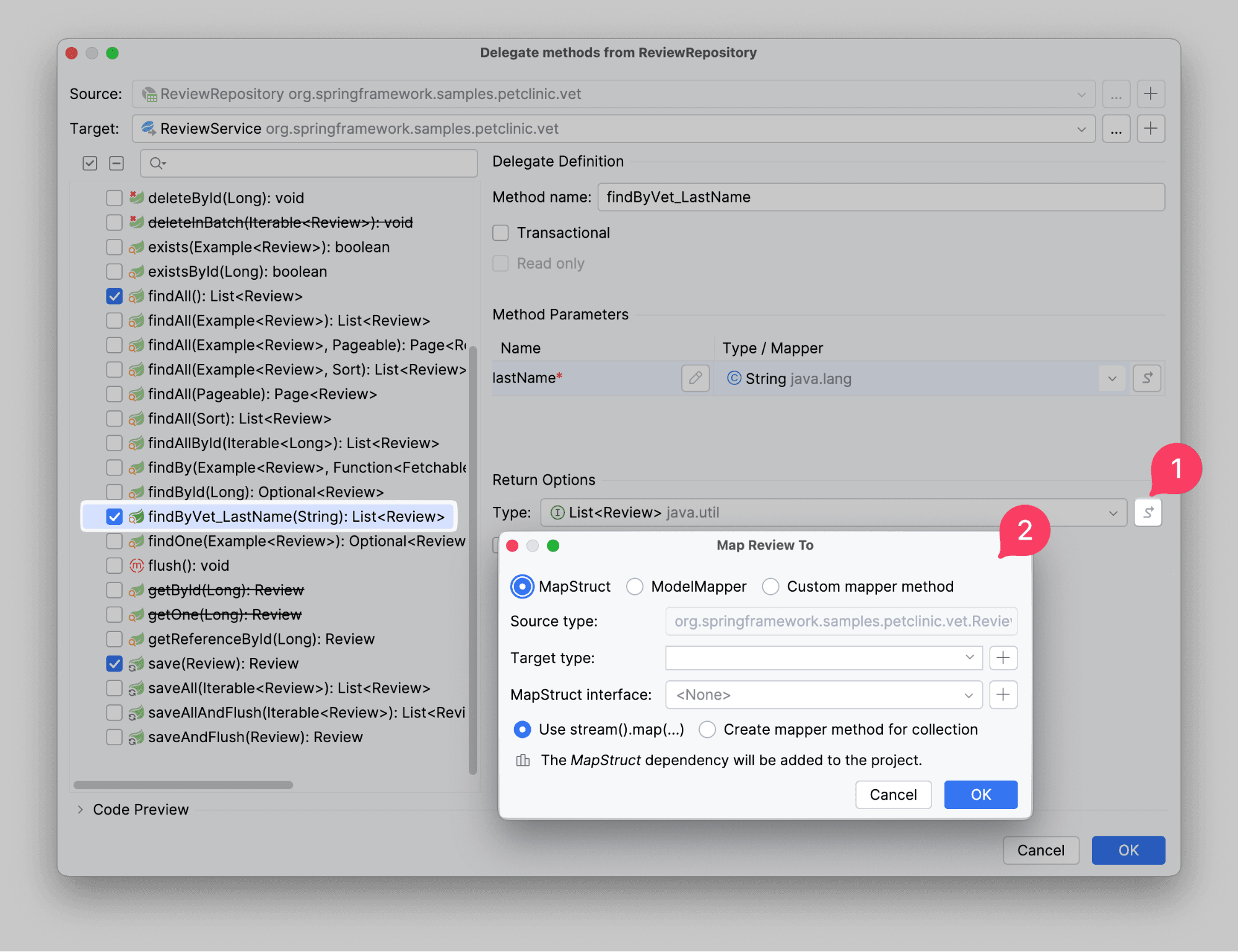
Amplicode поддерживает 3 способа маппинга: с помощью MapStruct, ModelMapper или настроить Custom mapper method. При выборе первых двух Amplicode добавит соответствующие зависимости в проект, а также позволит настроить классы. При выборе кастомного маппера можно задать свой маппер. Для нашего сценария в качестве Target type укажем новую DTO. Но DTO для нашей сущности еще нет, поэтому создадим:
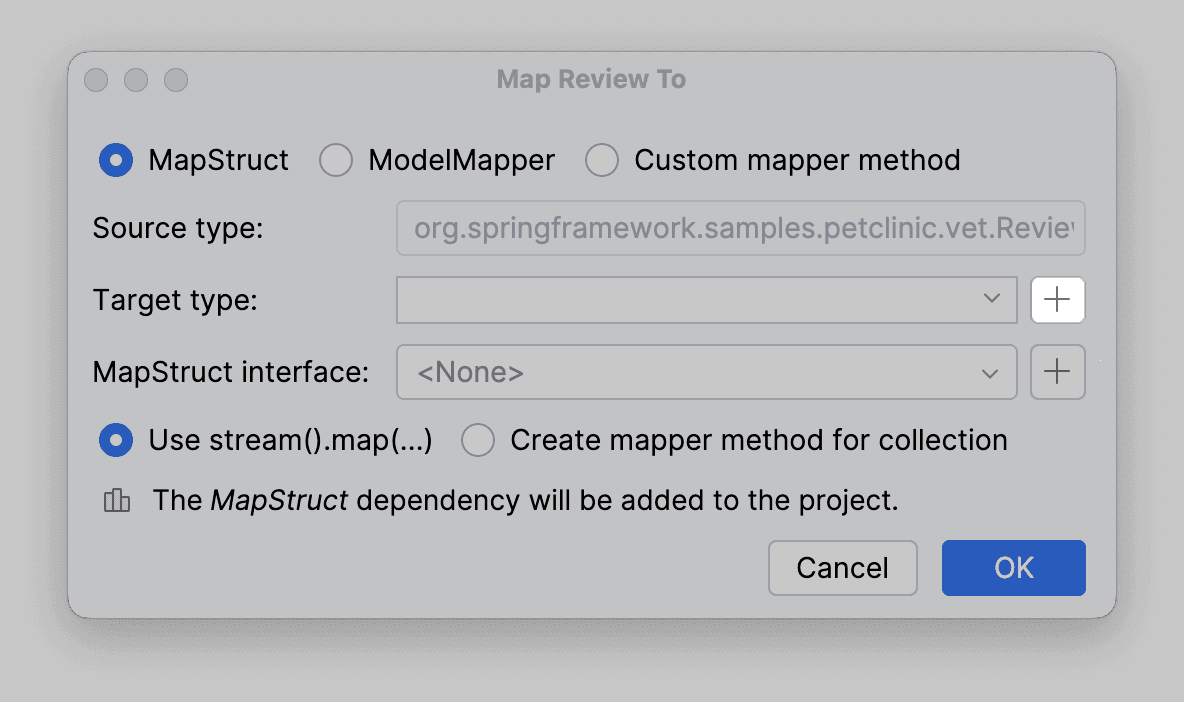
Выберем все базовые поля, а для vet укажем New Nested Class:
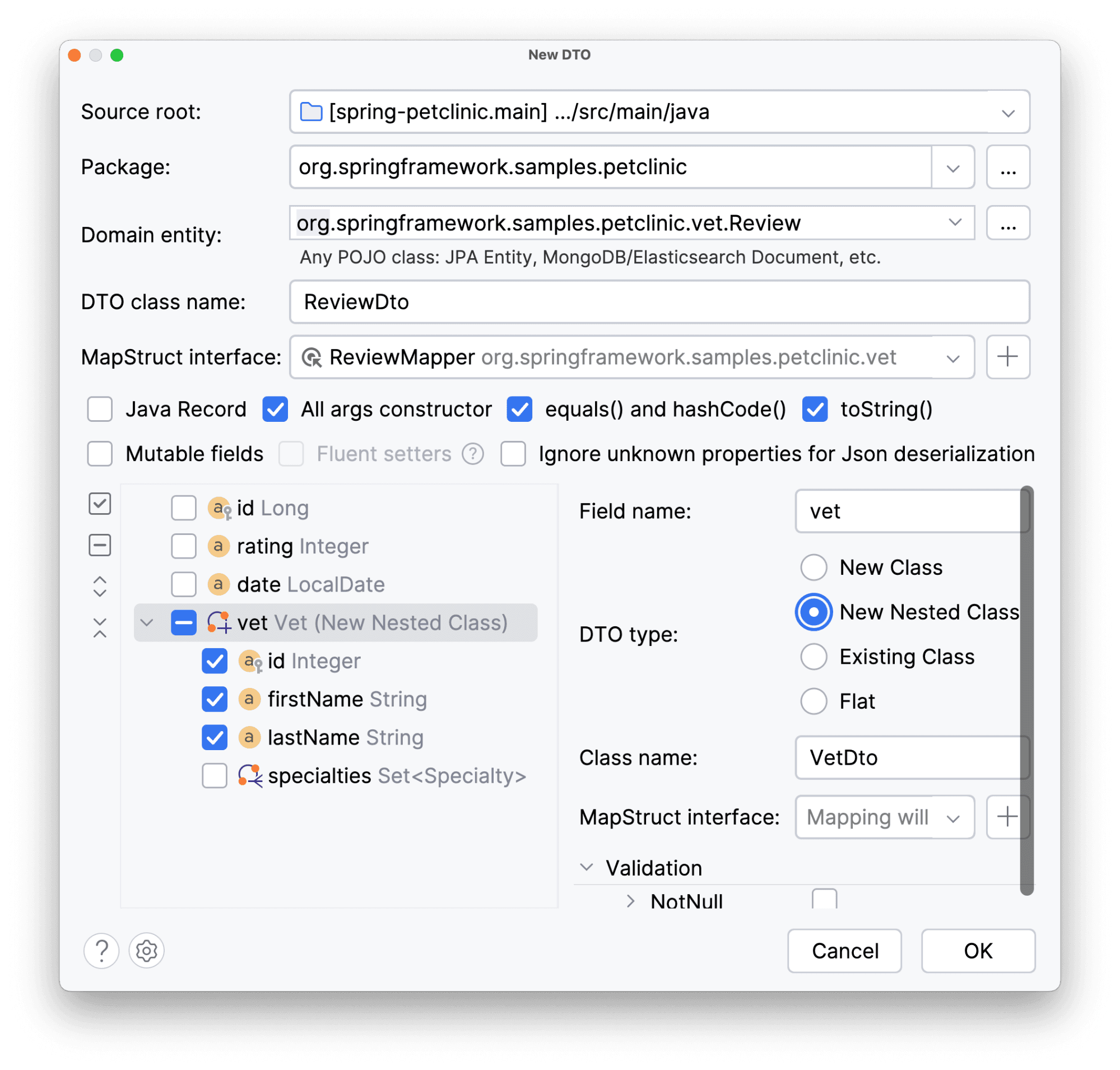
Создадим MapStruct интерфейс:
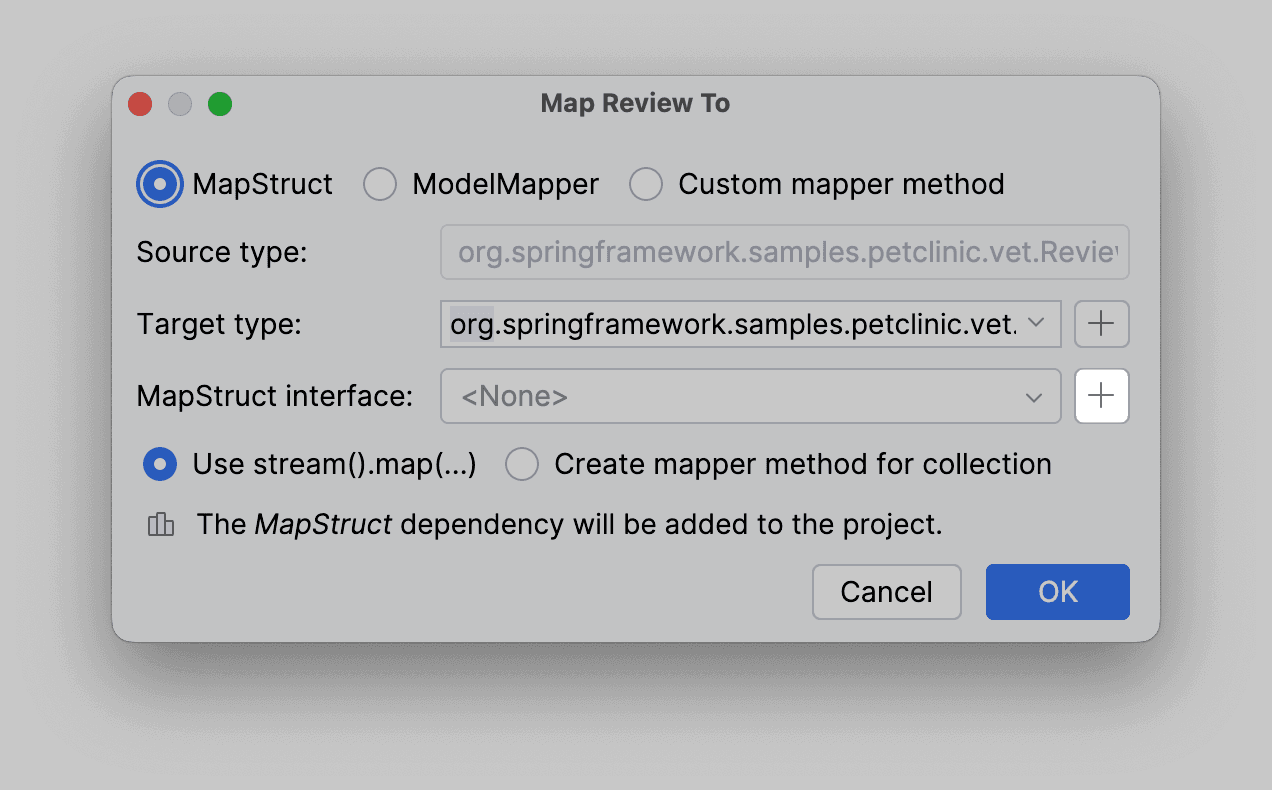
Оставим поля заполненными по умолчанию:
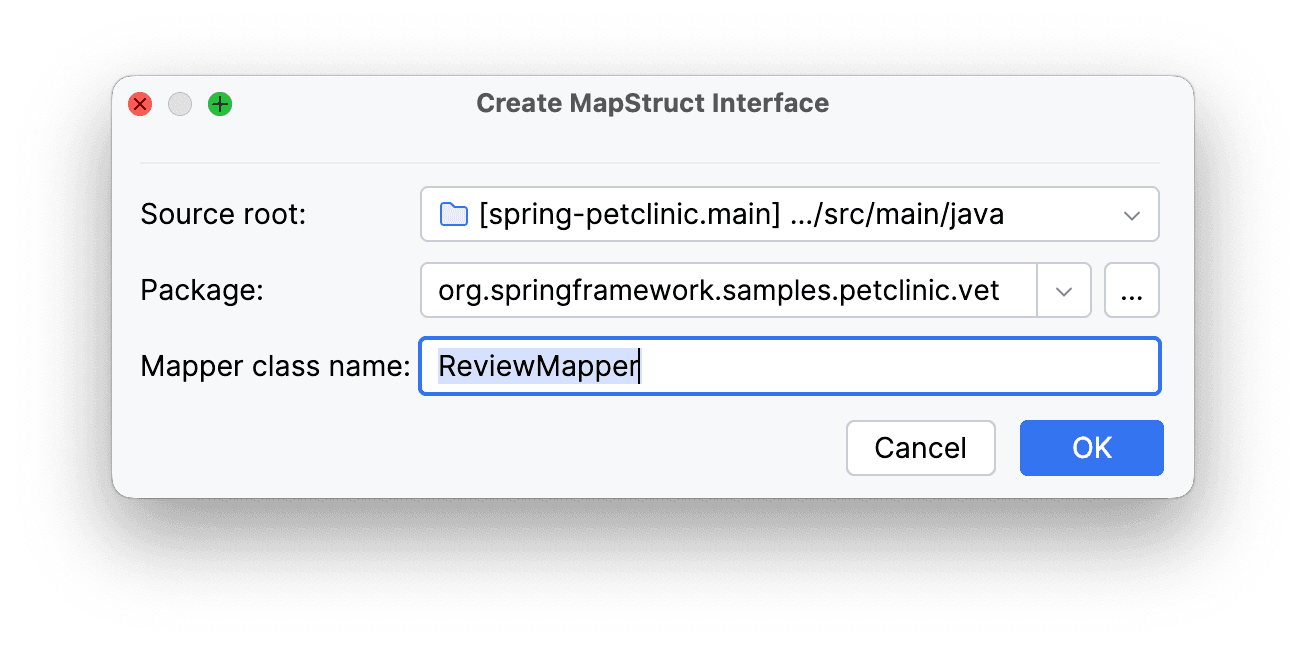
По итогу окно должно иметь поля, заполненные следующим образом:
Amplicode довольно заботлив, поэтому предупреждает, что зависимость на MapStruct будет добавлена в проект. Мы с этим, конечно, согласны (а как иначе?). Нажимаем Ок.
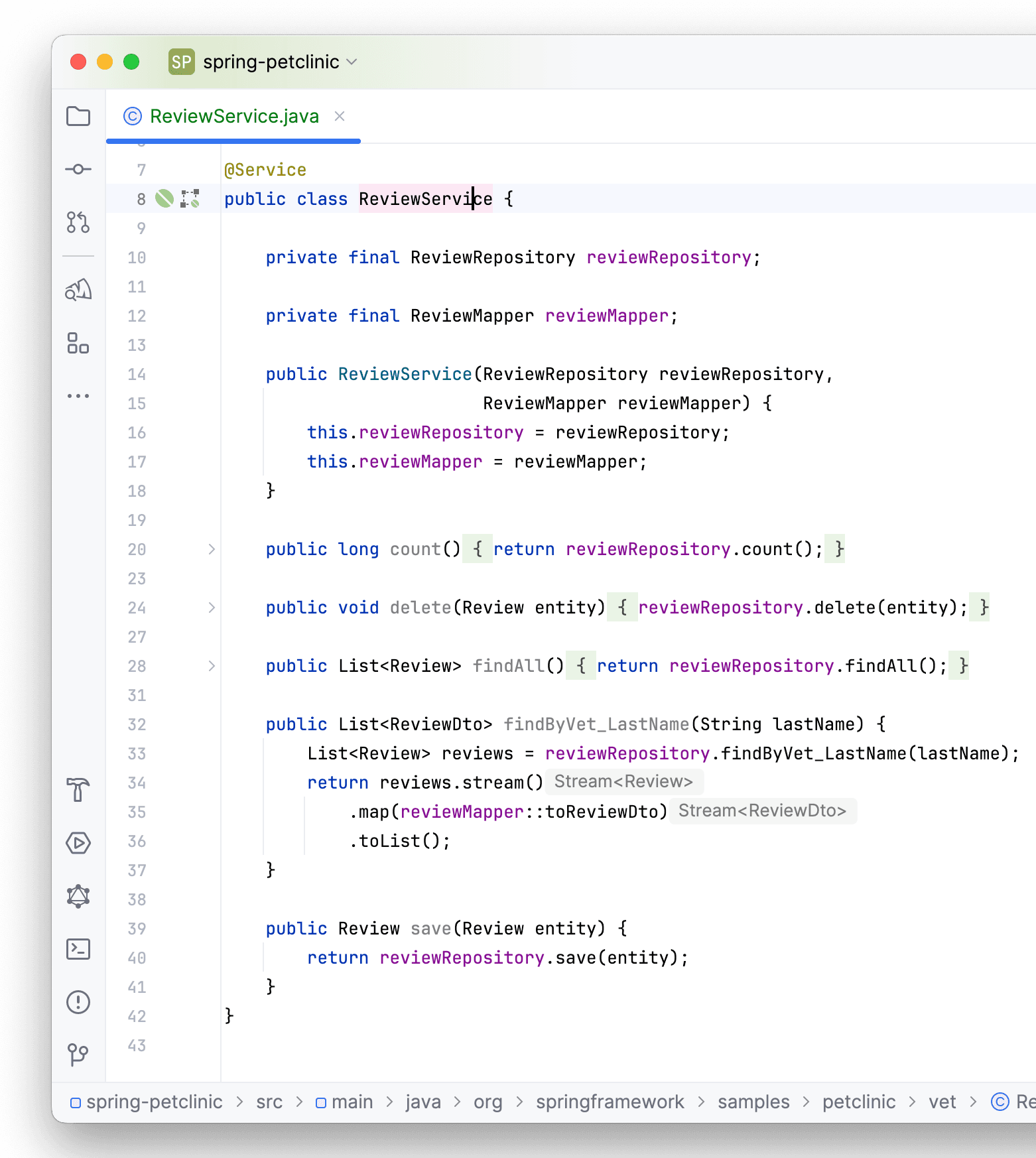
Возвращаемое значение было изменено на созданную нами DTO с настроенным маппером:
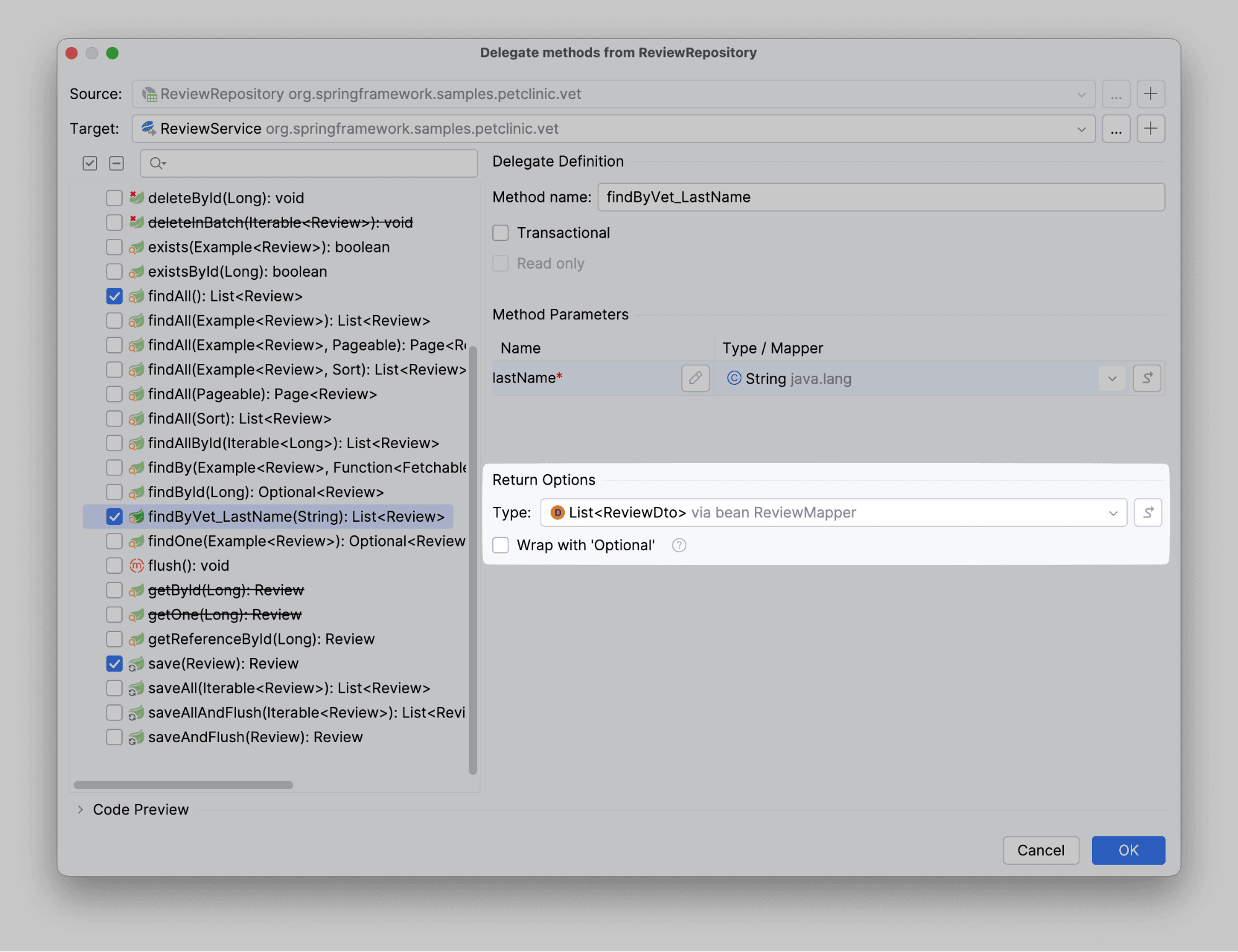
На этом кастомизация заканчивается. Нажимаем Ок, чтобы закончить процесс делегирования (хотя параллельно мы сделали еще кучу действий быстро и удобно).
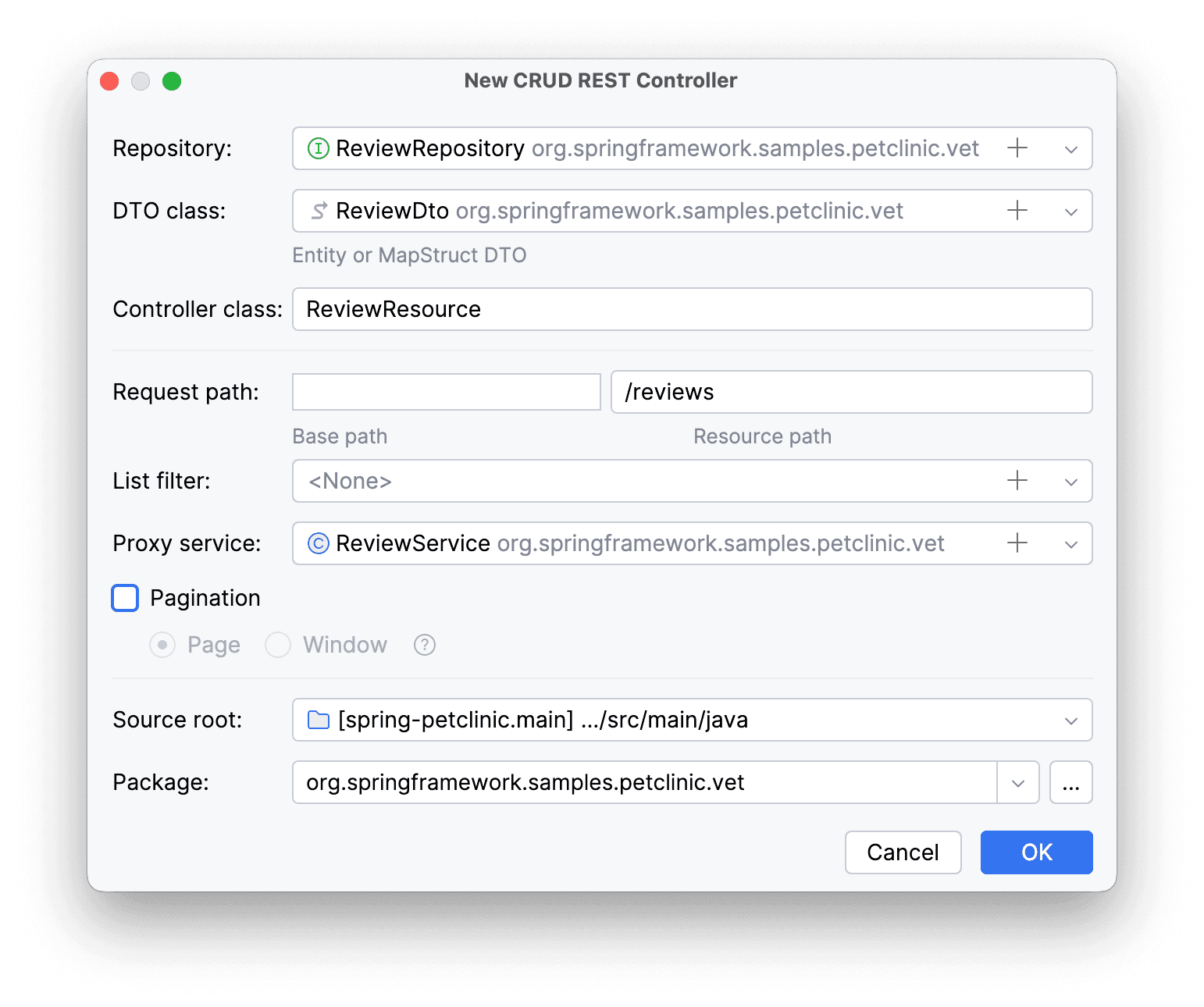
Остается только создать API. На этот раз используем не кнопку «+», а меню New: нажимаем ПКМ по пакету vet → New → CRUD REST Controller.
Здесь мы выбираем наш репозиторий, указываем DTO, сервис и все, что нужно для генерации нужного нам контроллера, но пока что уберем пагинацию.
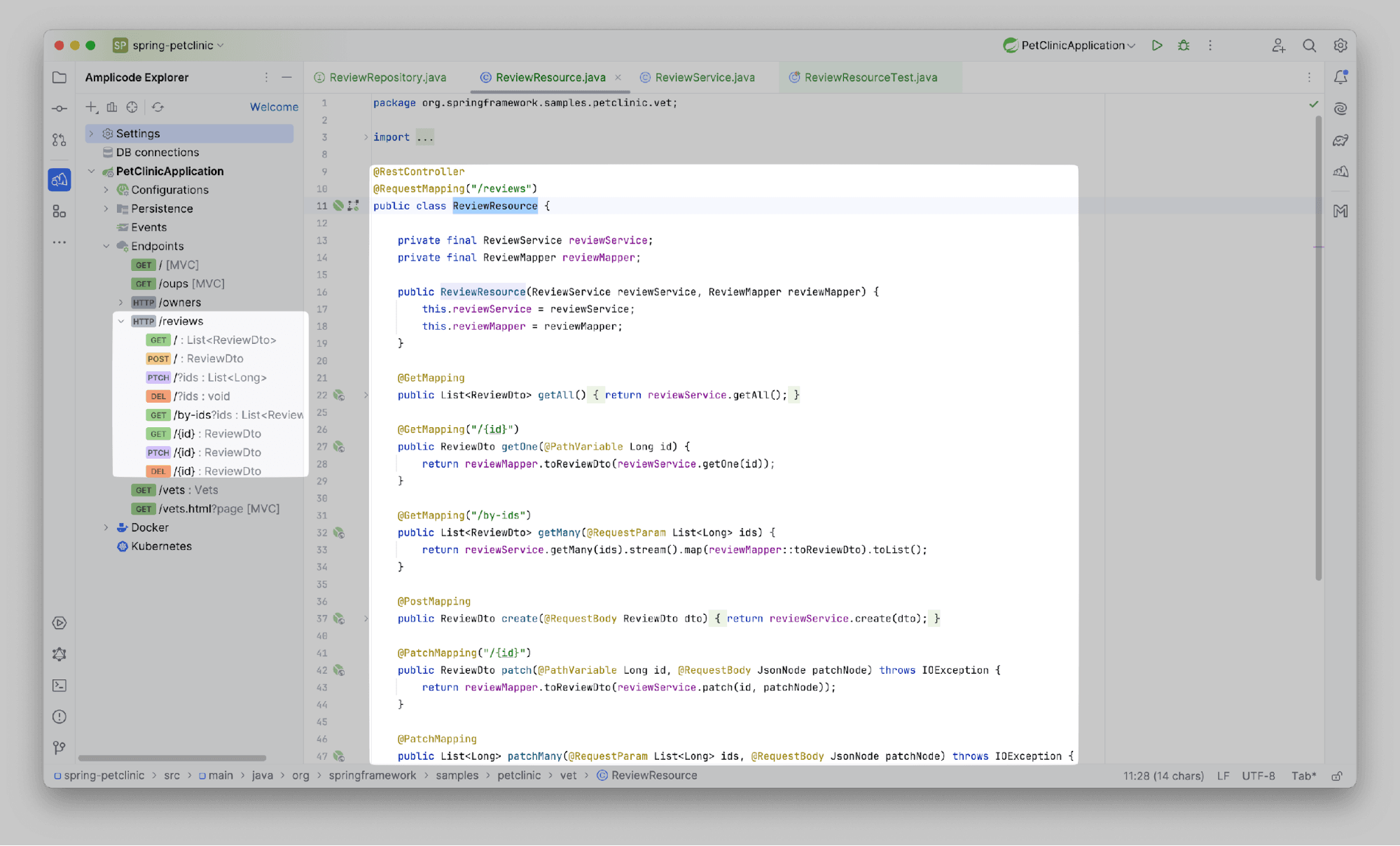
С CRUD-операциями все понятно, но у нас был еще и кастомный findByVet_LastName метод. Его мы можем сделегировать, находясь прямо в классе-контроллере. Воспользуемся Gutter-icon -> Delegate from...
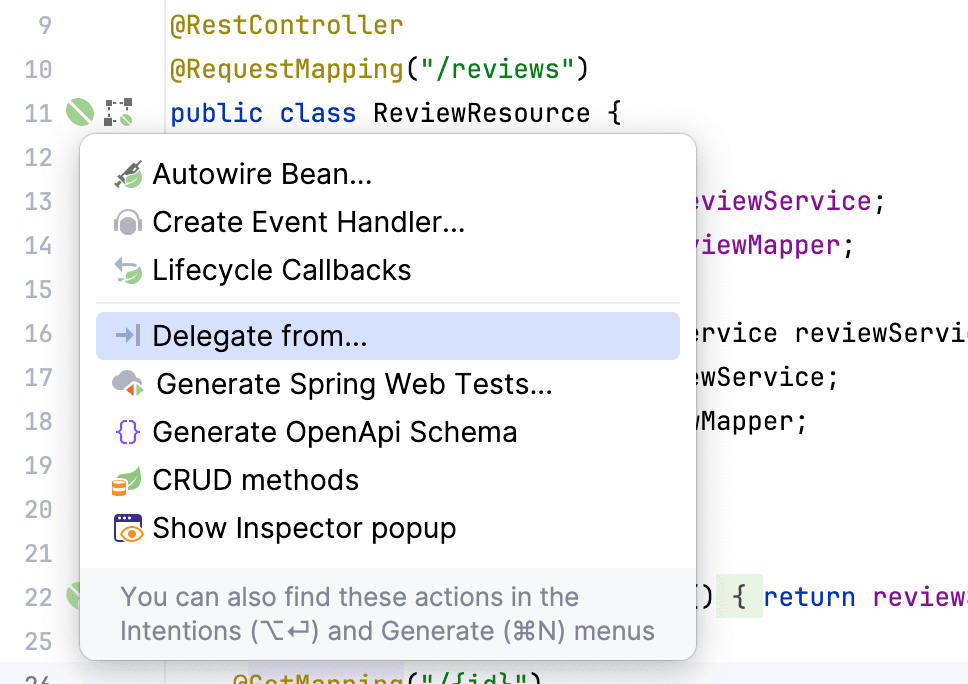
Выбираем наш метод. Тут также можно его закастомизировать под контекст контроллера, но нас устраивают параметры, предложенные Amplicode.
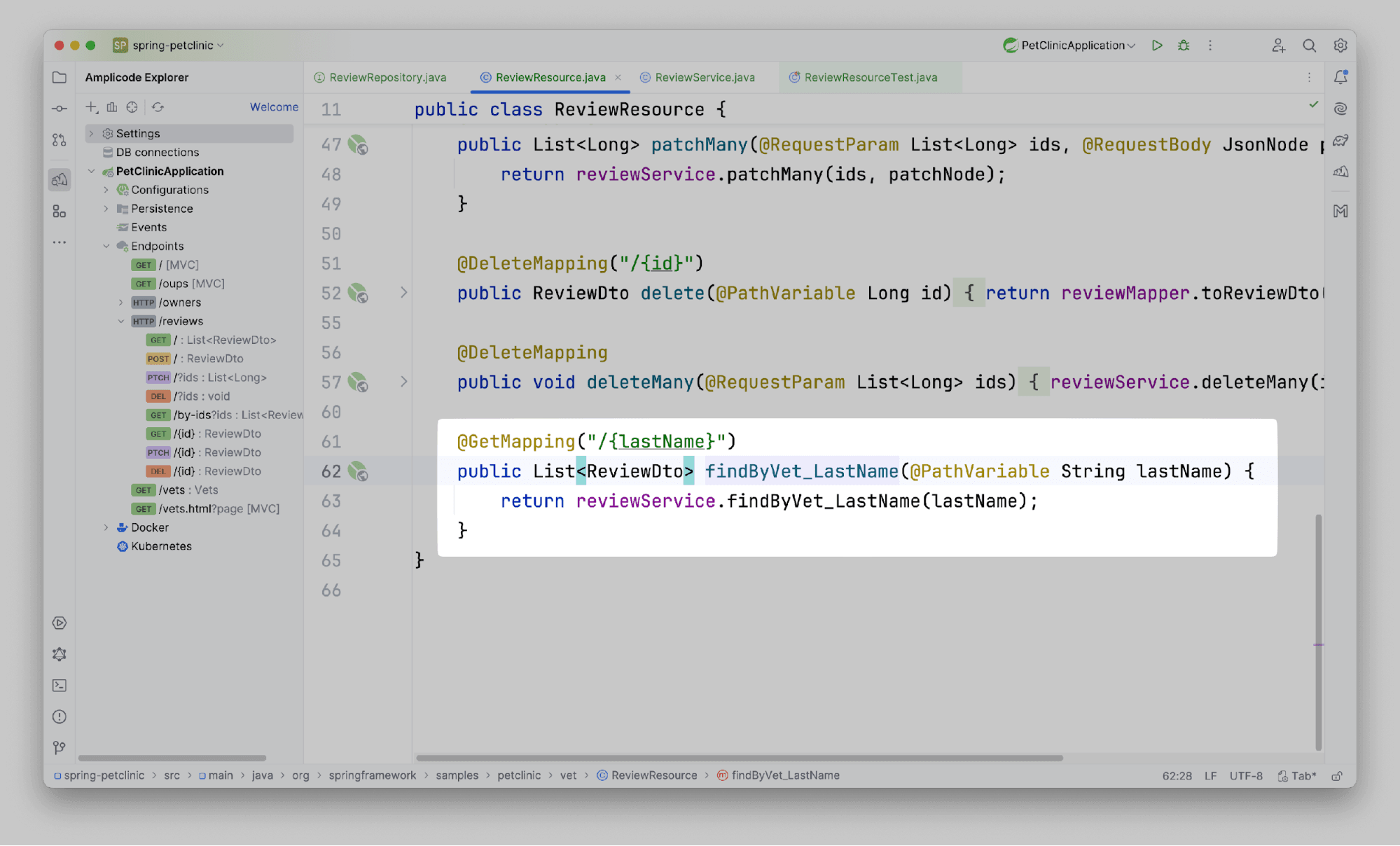
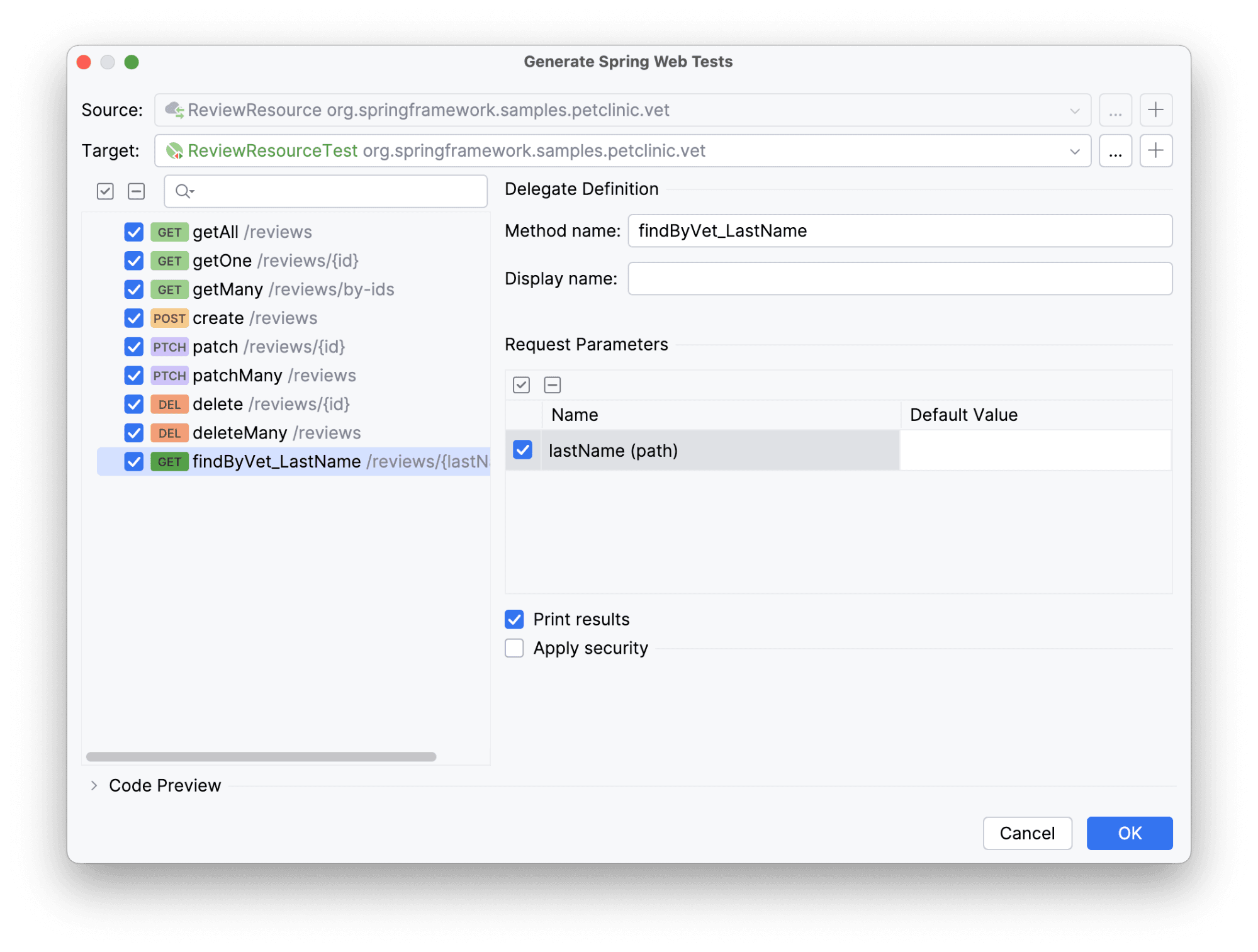
На данном этапе мы предоставили точку доступа в приложение, не вдаваясь в подробности Spring, ведь в местах, где это необходимо, Amplicode подсказывает, как сделать лучше. Но какой код без тестов? Идем по отработанной схеме. Gutter-icon -> Generate Spring Web Tests.
Появится окно с выбором методов, на которые хотим сгенерировать тесты, а также источник и целевой класс.
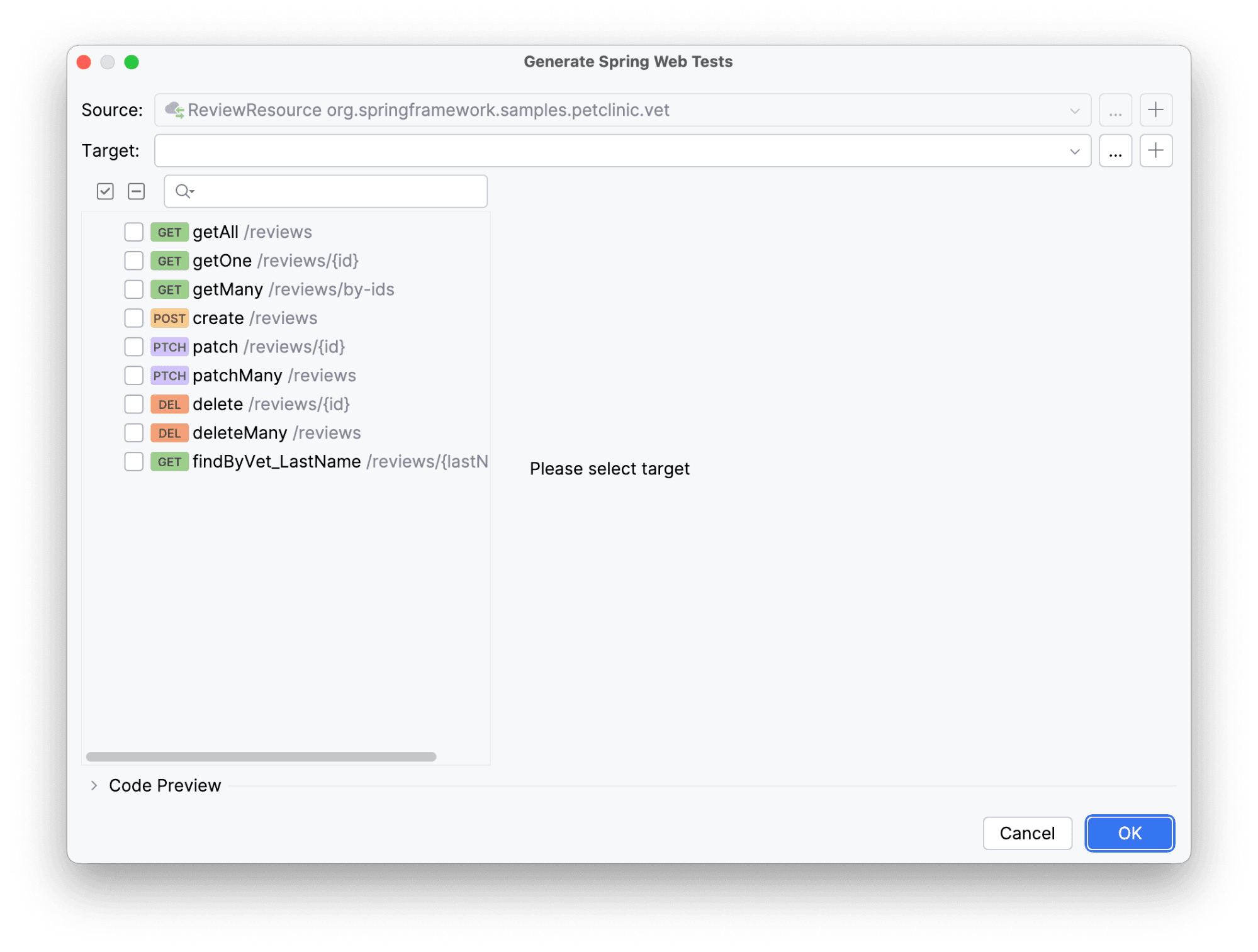
Класса у нас нет, но мы уже знаем, что идти для этого далеко не придется.
Тут все хорошо уже по умолчанию. Оставляем.
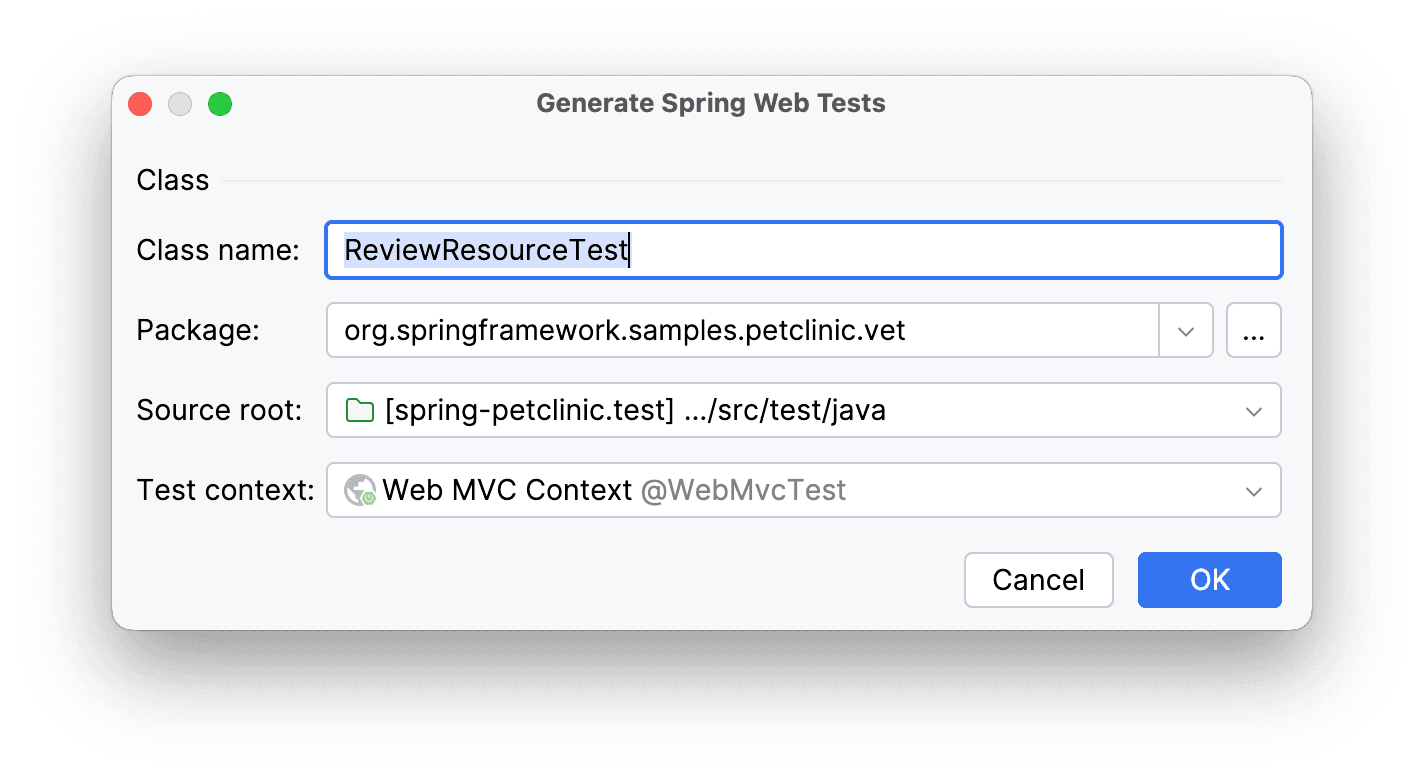
Дополнительно ничего настраивать не будем (хотя могли бы).
Получаем тестовый класс с тестами на каждый выбранный метод.
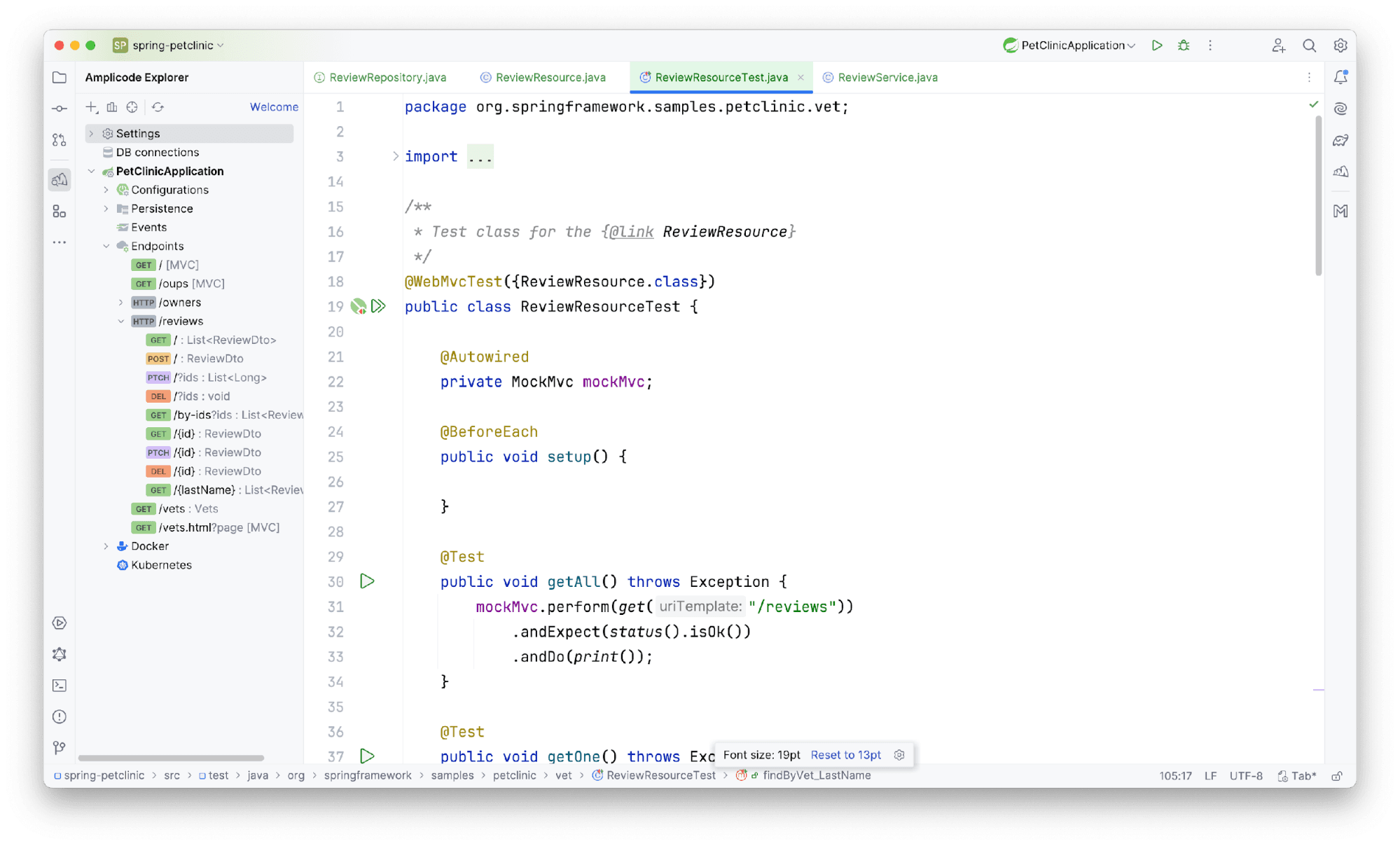
Только посмотрите, мы создали целую единицу инфраструктурной функциональности за такое небольшое количество времени. Но мы не всегда занимаемся созданием чего-то нового, поэтому время писать бизнес логику!
Доработка приложения
Отлично! Петклиника стала чуть лучше. Но ведь мы не каждый день добавляем новый домен, верно? Иногда задача совсем другая: написать новую бизнес-логику, подкрутить конфигурацию или слегка переработать API (все то, чем занят рядовой разработчик каждый день).
И вот тут на сцену выходят usability-фичи Amplicode. Amplicode знает ваш проект вдоль и поперек, а значит, ему ничего не мешает помочь вам с доработкой приложения.
Представим себе задачу: требуется добавить метод, который вычисляет средний рейтинг всех отзывов за определённый период. Нужно это, например, чтобы получать средний рейтинг ветеринара за последний месяц.
Начнем доработку с написания бизнес-логики в сервисном слое. Откроем сервис и напишем сигнатуру нашего метода. Amplicode не претендует на ваш хлеб, поэтому не старается полностью заменить написание кода, а лишь является помощником по его написанию.
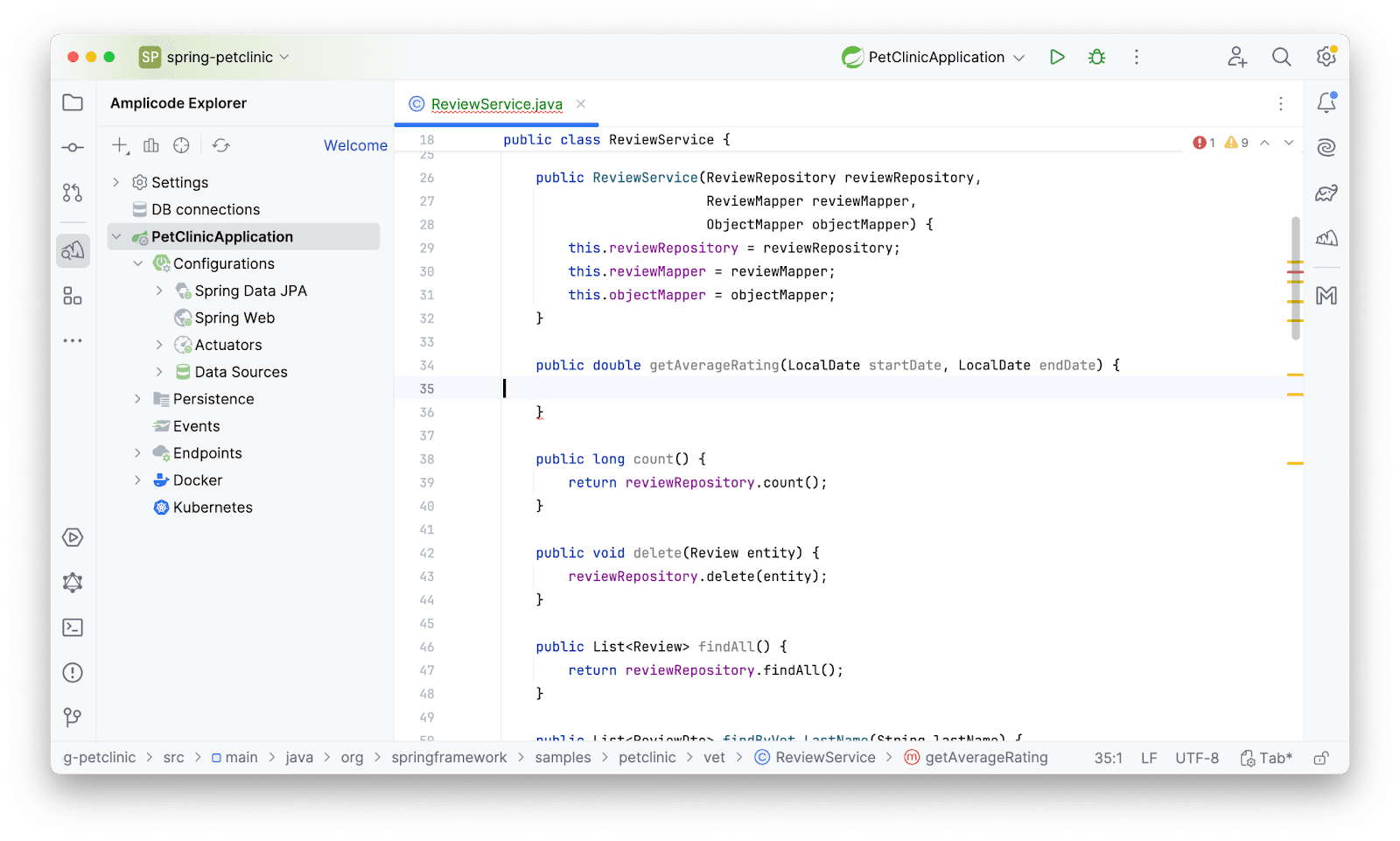
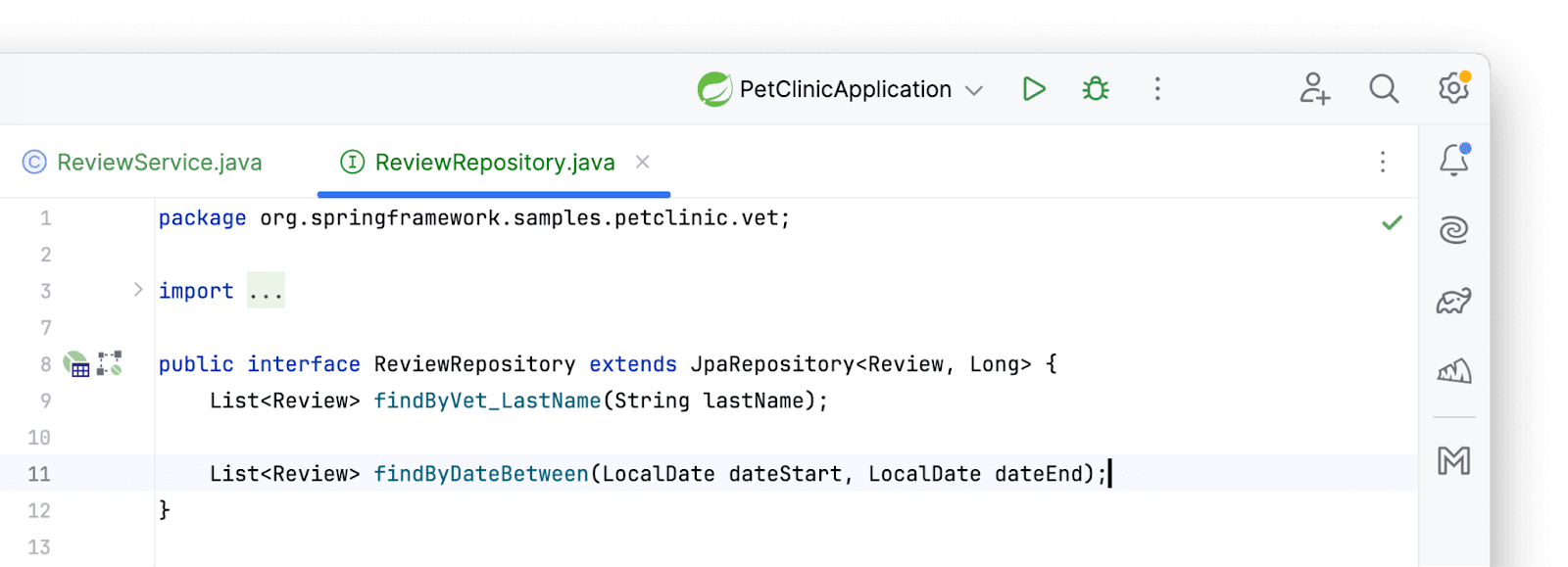
Для того, чтобы получить все записи, созданные в определенный промежуток времени, потребуется метод в репозитории. После получения записей посчитаем среднее. Метод, конечно, нужно создать. Как бы мы поступили, если бы не использовали Amplicode? Пошли бы в репозиторий, написали бы руками метод, затем вернулись бы в сервис и вызвали в нужном нам месте метод. С Amplicode можно миновать лишний шаг по переходу и создать метод репозитория находясь в сервисе. При этом мы будем использовать еще не существующий метод, будто бы он есть. Данная фича называется Ghost Completion. Пишем несколько символов из названия бина прямо в теле метода и Amplicode предлагает выбрать наш репозиторий. Важно отметить, что, если бы бин не был заинжектирован ранее, Amplicode сам заинжектировал бы бин в соответствии с той политикой инжектирования, которая указана в настройках.
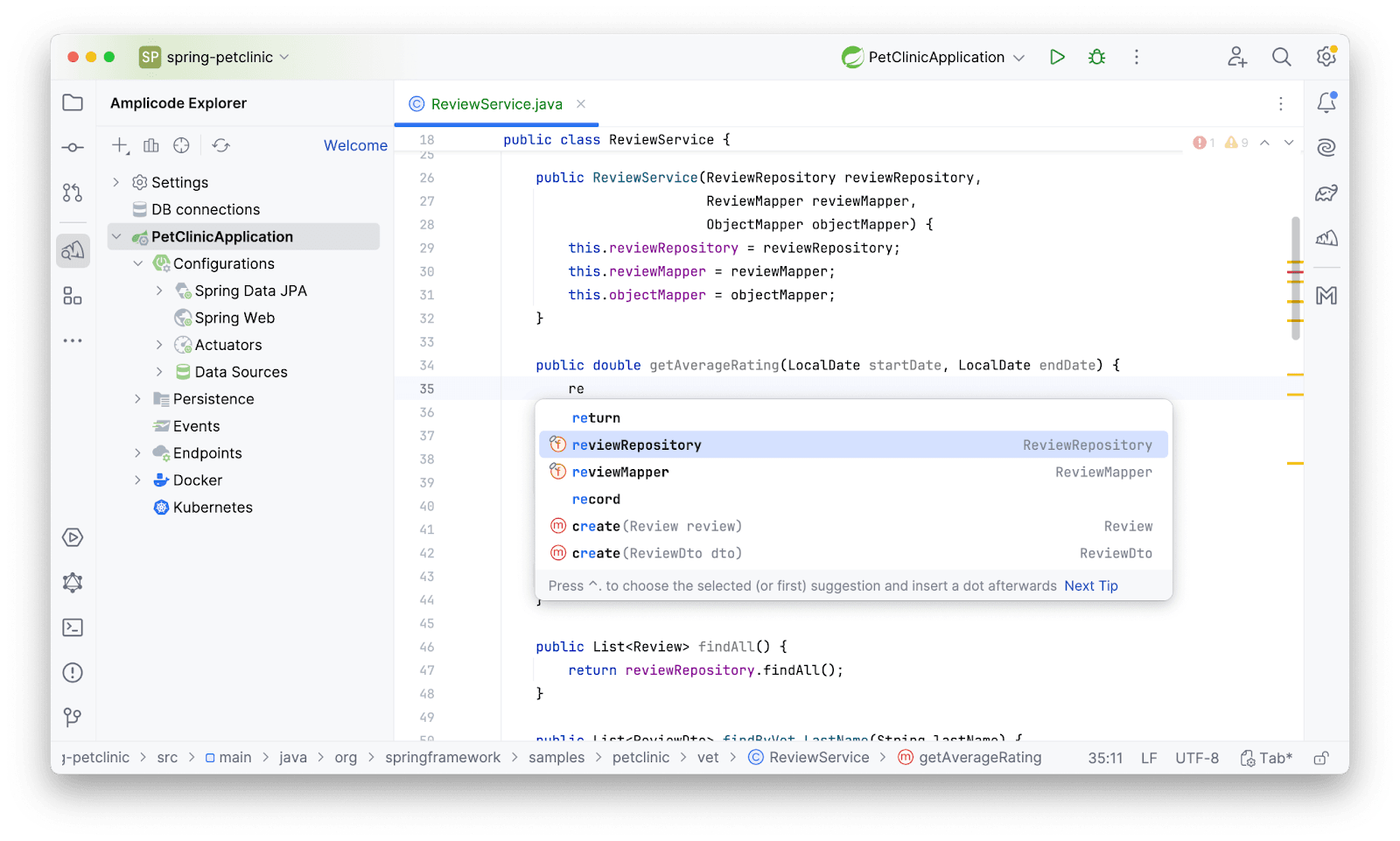
Мы знаем как устроены derived-методы, поэтому пишем название метода:
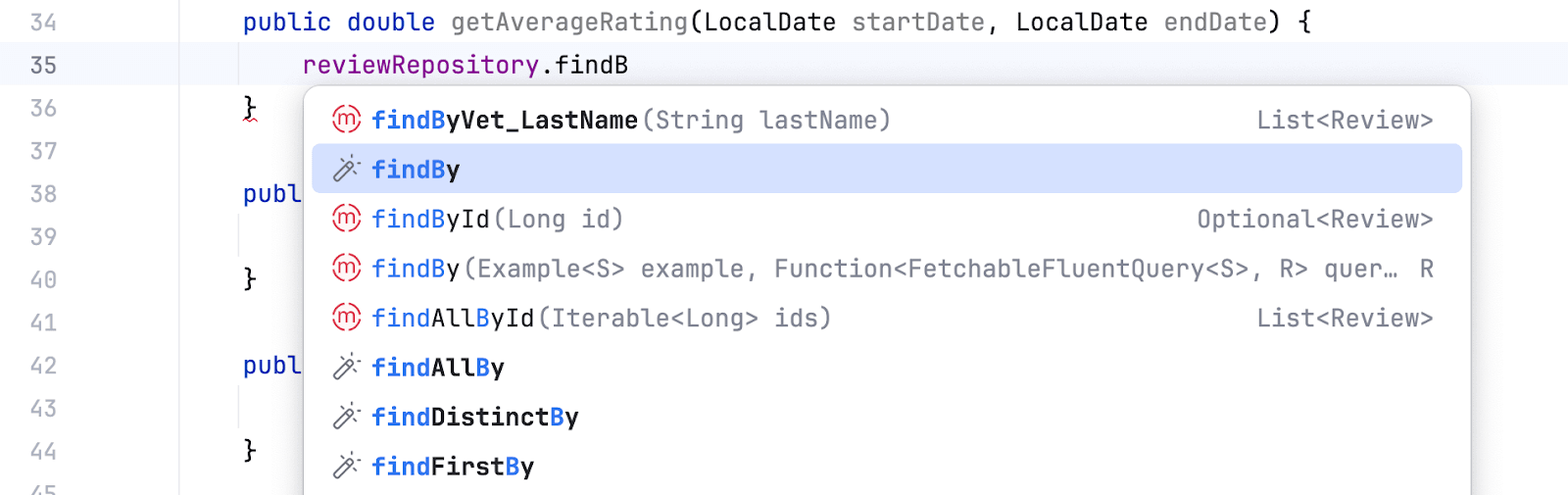
Amplicode знает про нашу модель, поэтому предлагает атрибуты. Выбираем необходимый нам вариант:
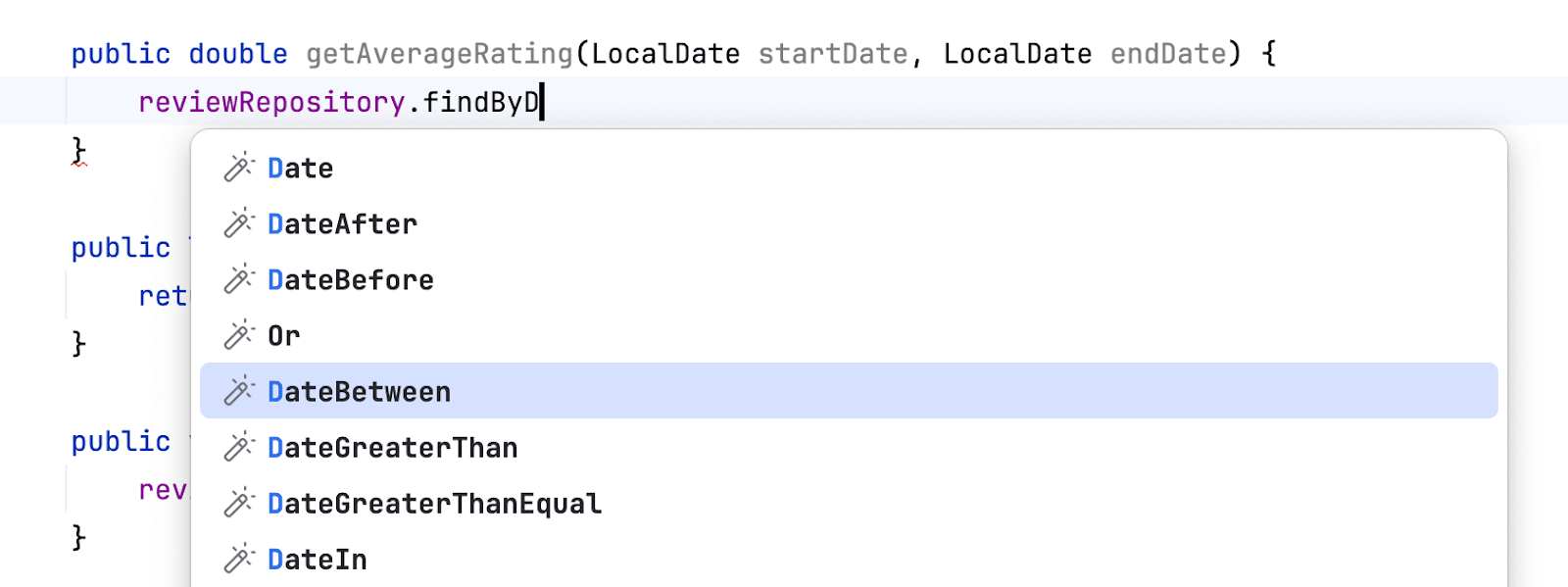
И воспользуемся action’ом для создания метода (Option (Alt) + Enter):
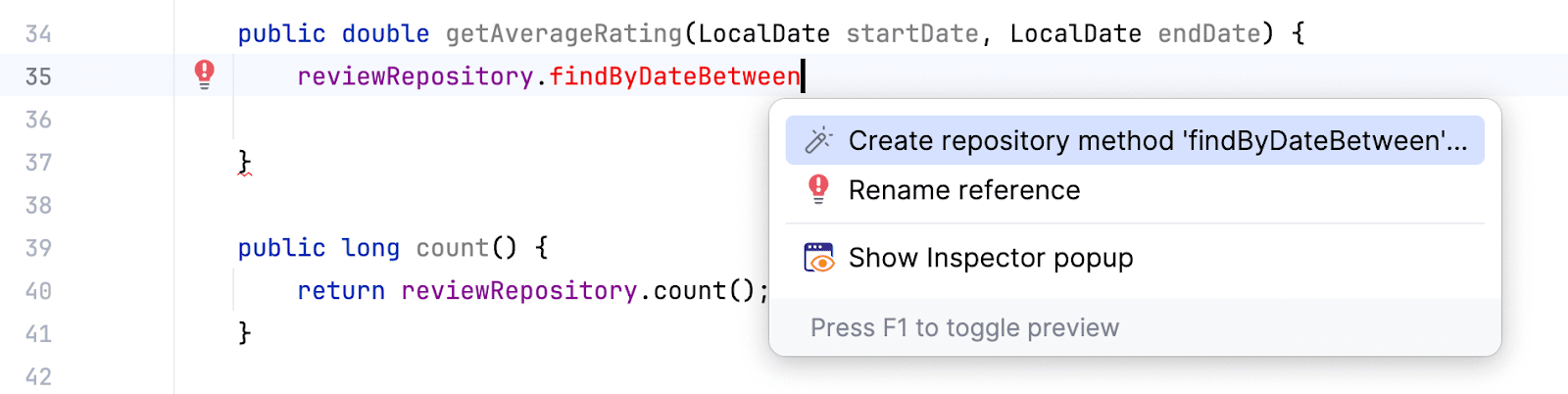
Выберем в выпадающем меню обычный список:
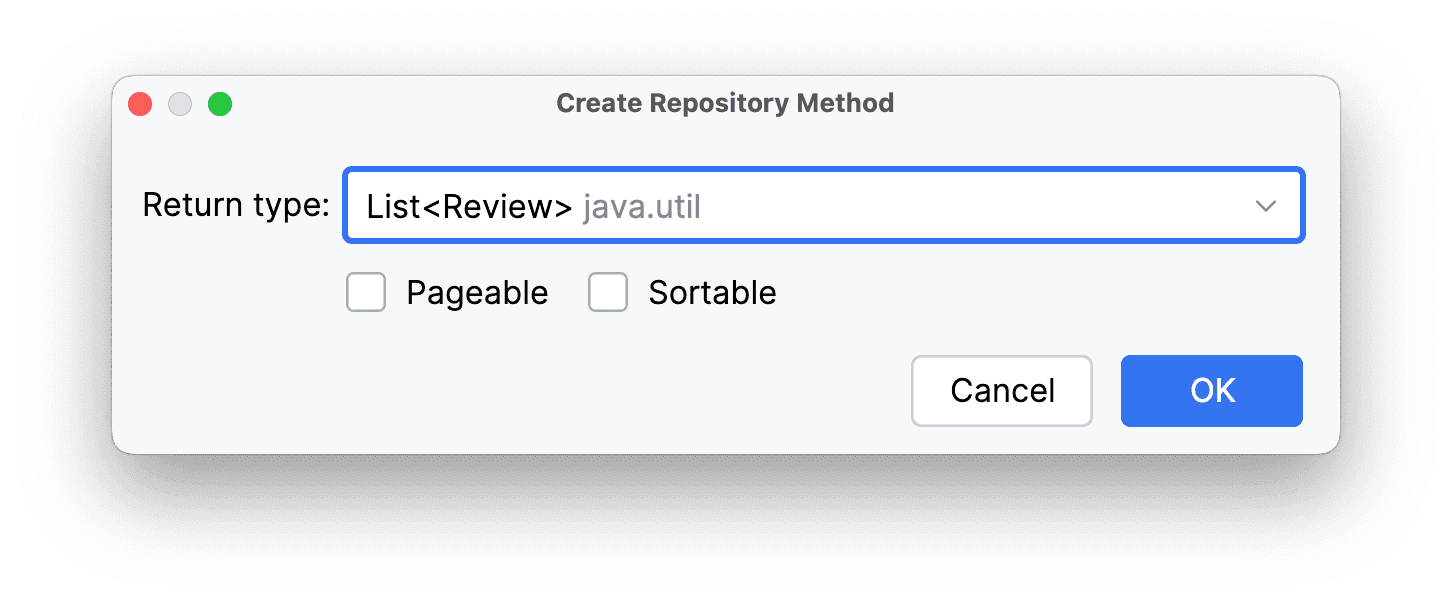
Нажимаем Ок и радуемся созданному методу:
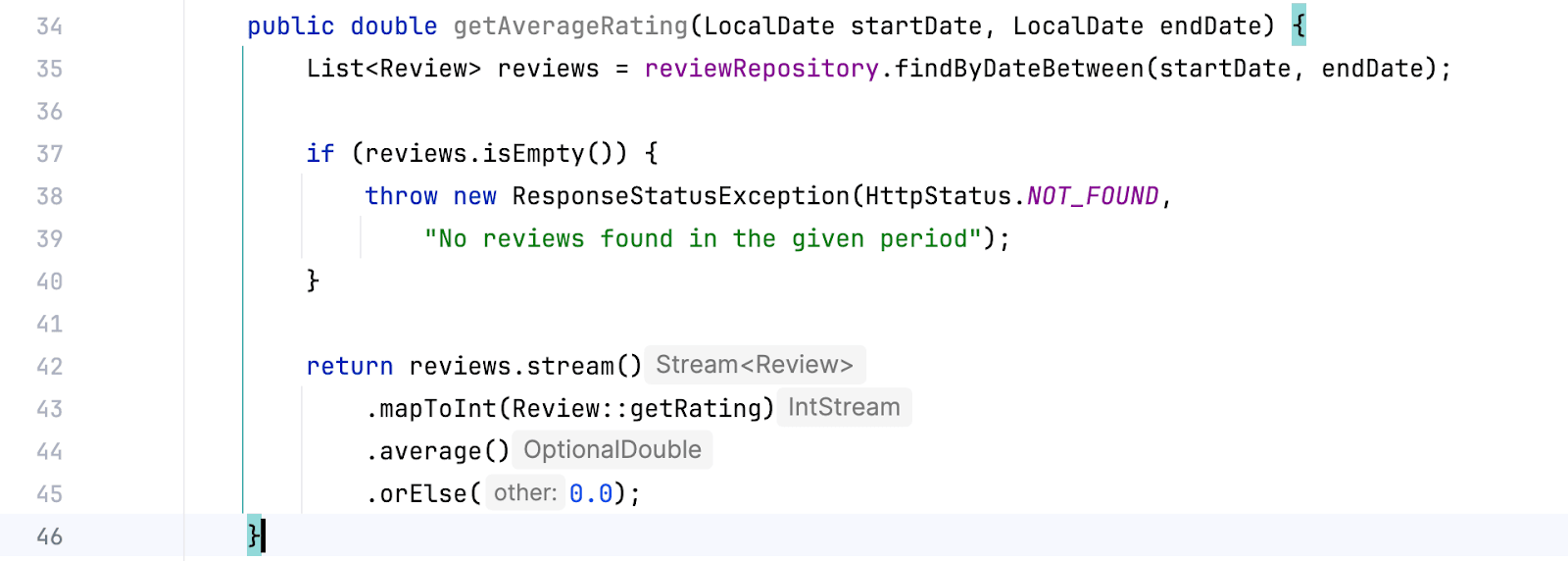
Дописываем бизнес-логику:
Остается лишь прокинуть наш метод в контроллер:
В окне делегации источник, класс назначения, метод и все остальные параметры уже определены, нам остается лишь задать Mapping path:
Нажимаем Ок и смотрим на сгенерированный Amplicode’ом код:
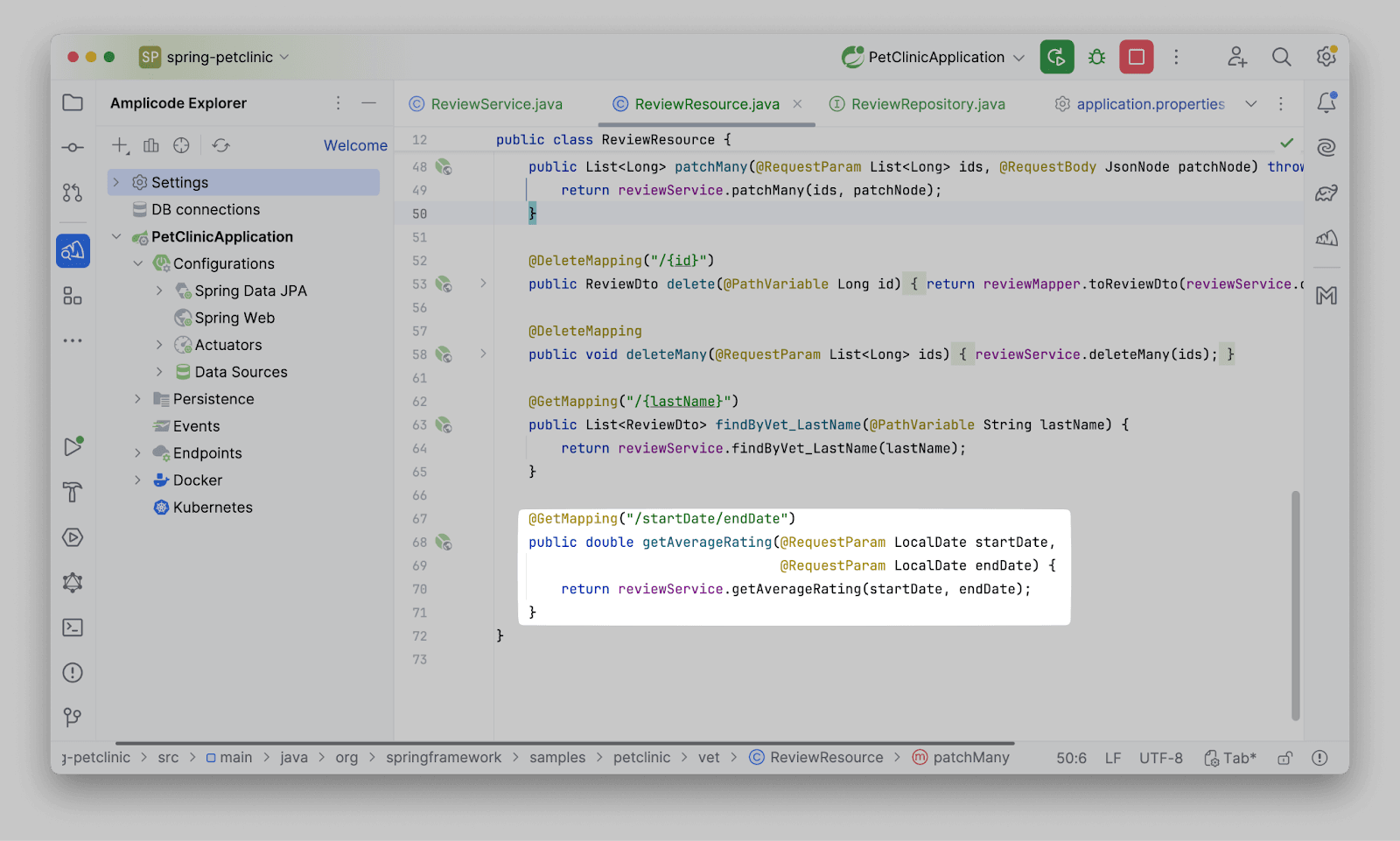
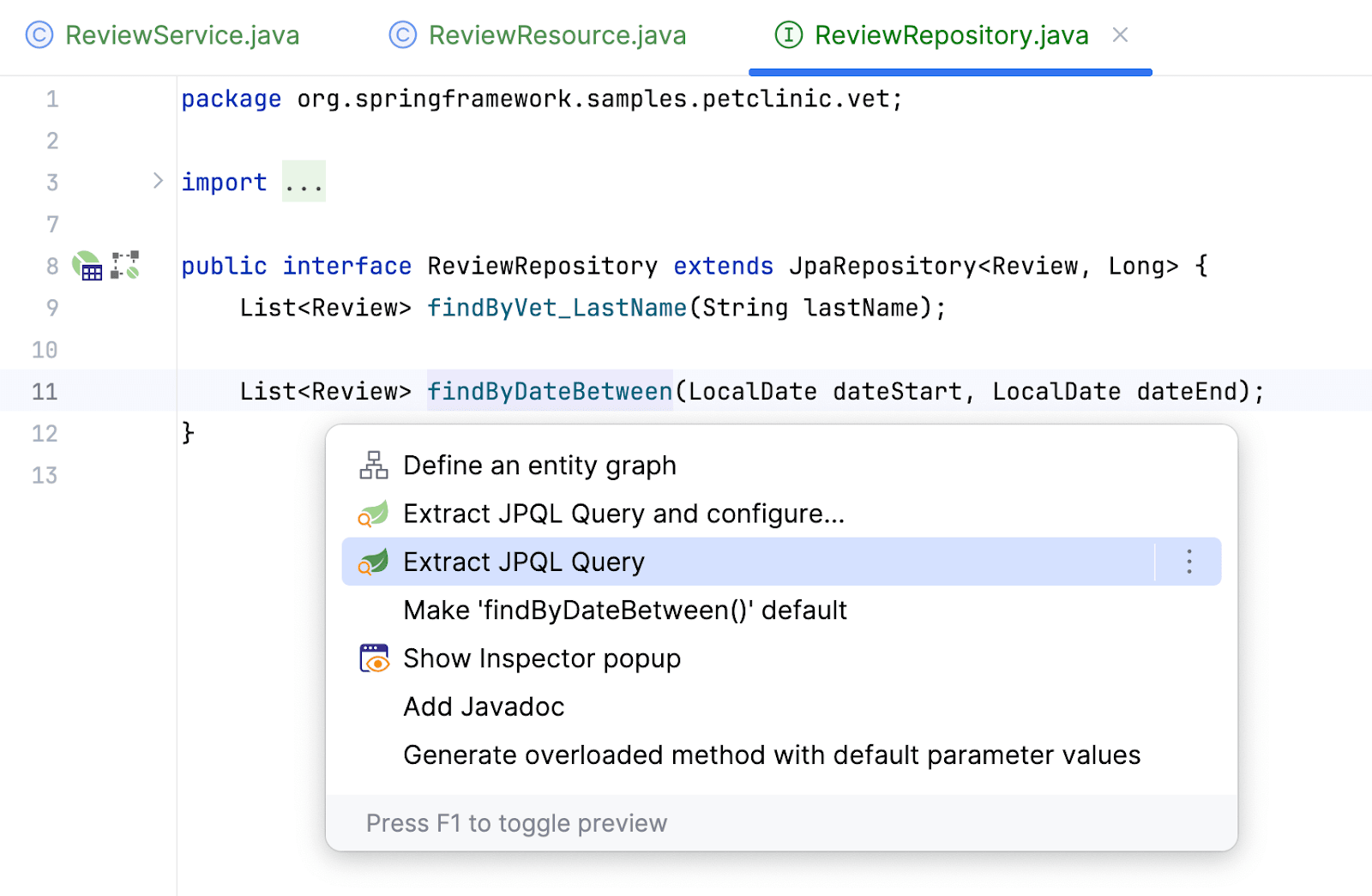
Кстати, Amplicode умеет конвертировать Derived методы в Query. В целом данную процедуру можно осуществить и вручную. Но ведь разработчикам платят не за это. Ведь так? Для этого перейдем в репозиторий и вызовем Show Action на методе:

Миграции
Ну и, конечно, пора заняться надежностью нашей системы. В современном мире без системы версионирования БД — никуда.
Процесс важный, но, скажем честно, не всегда захватывающий: создание миграционных скриптов, их рефакторинг, разбиение на отдельные changeset… Иногда это кажется рутиной.
Но Amplicode делает этот процесс чуть интереснее, добавляя визуальные компоненты для удобной работы с Liquibase и Flyway.
Вот, что мы сделаем:
- Создадим init-скрипт
- Поднимем БД в Docker (понадобится установить Docker plugin)
- Накатим изменения
- Изменим модель и посмотрим, какие средства предлагает плагин для работы с diff-скриптами
Задач немало, но с Amplicode мы справимся за считанные минуты.
Начнем с того, что добавим конфигурацию для миграции:
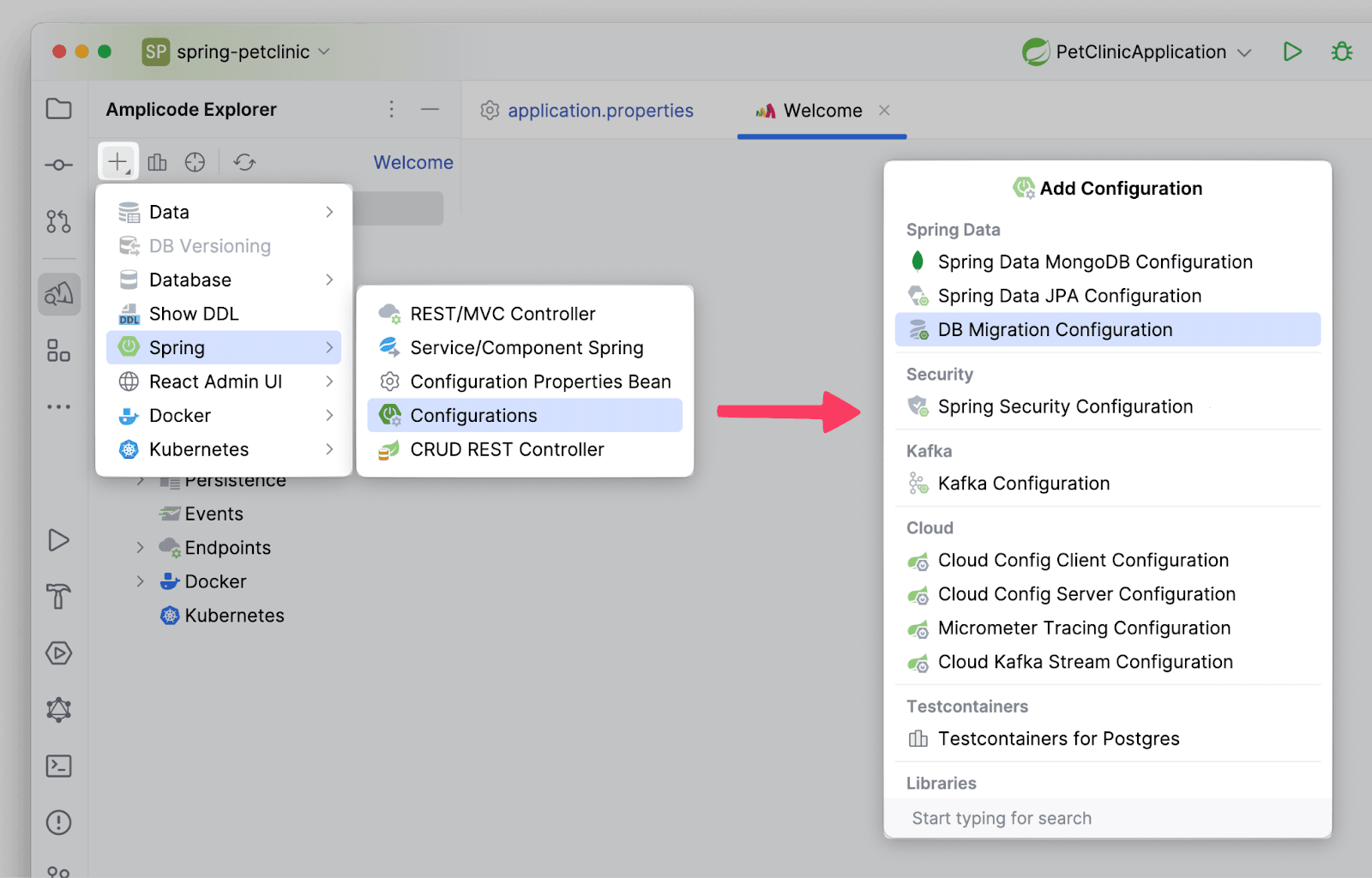
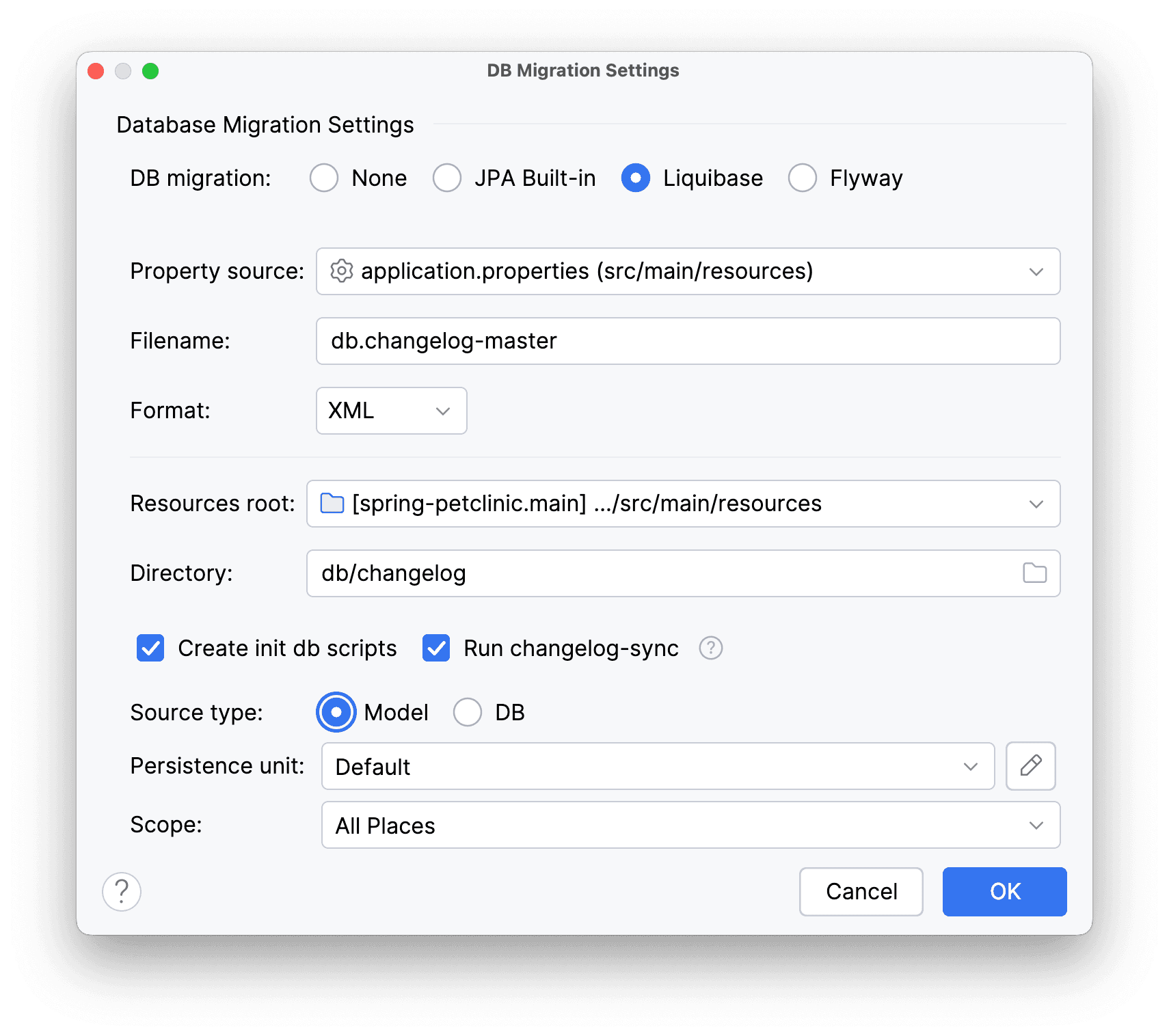
Выберем в качестве системы версионирования БД Liquibase, Source Type будет Model, так как мы придерживаемся Model-first подхода. Остальные поля заполнены по умолчанию так, как нас и устраивает.
Amplicode сгенерировал init скрипт. В данном окне можно посмотреть все скрипты, какие-то из них отменить для создания, если требуется, а также сконфигурировать их по предложенным параметрам. Нас все устраивает, поэтому нажимаем Save.
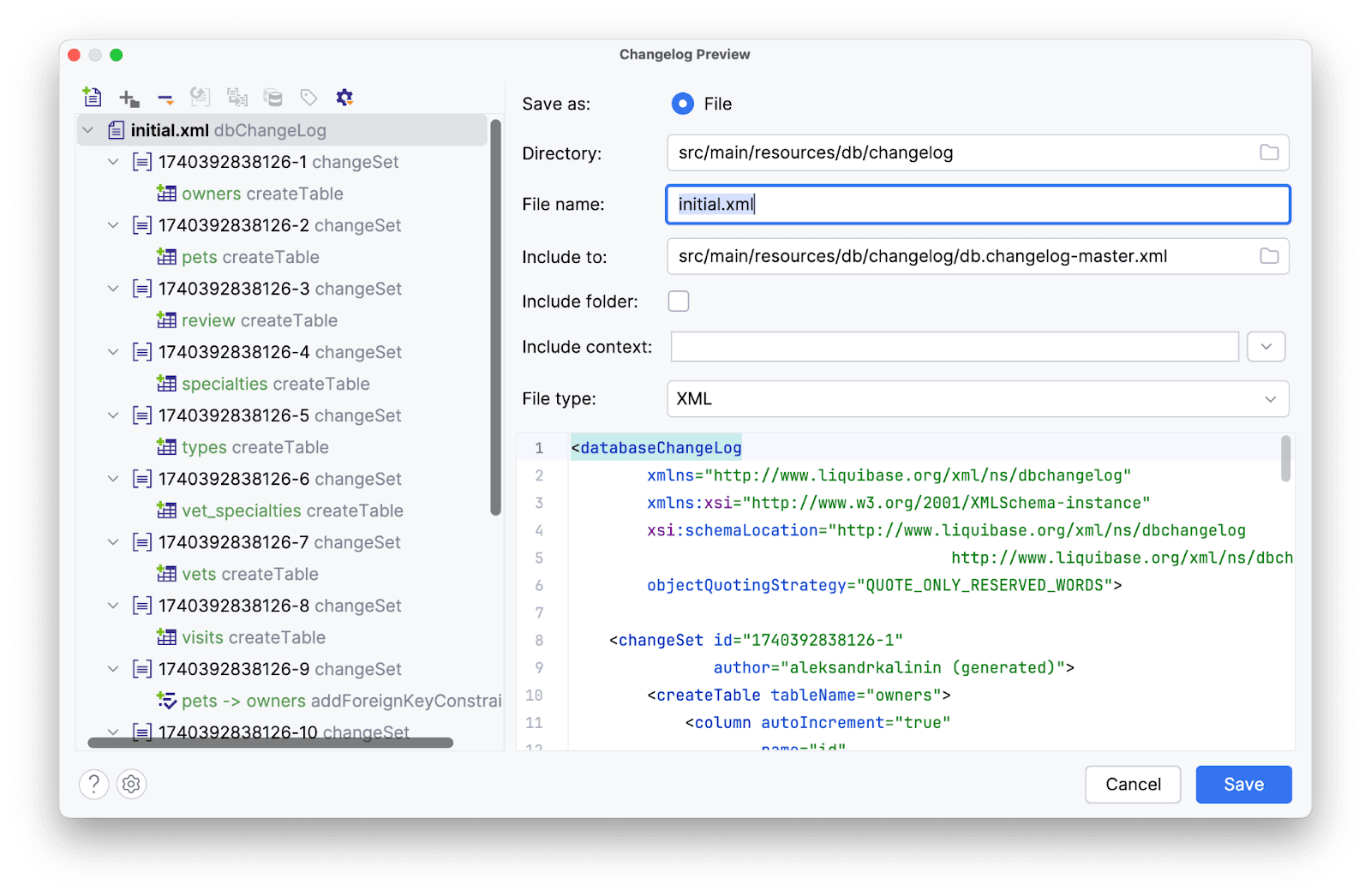
Init скрипт готов. Его наличие можно проверить в директории с ресурсами. Наконец, займемся поднятием сервиса БД через Docker. Создадим docker-compose.yaml файл:
Получаем пустой файл:
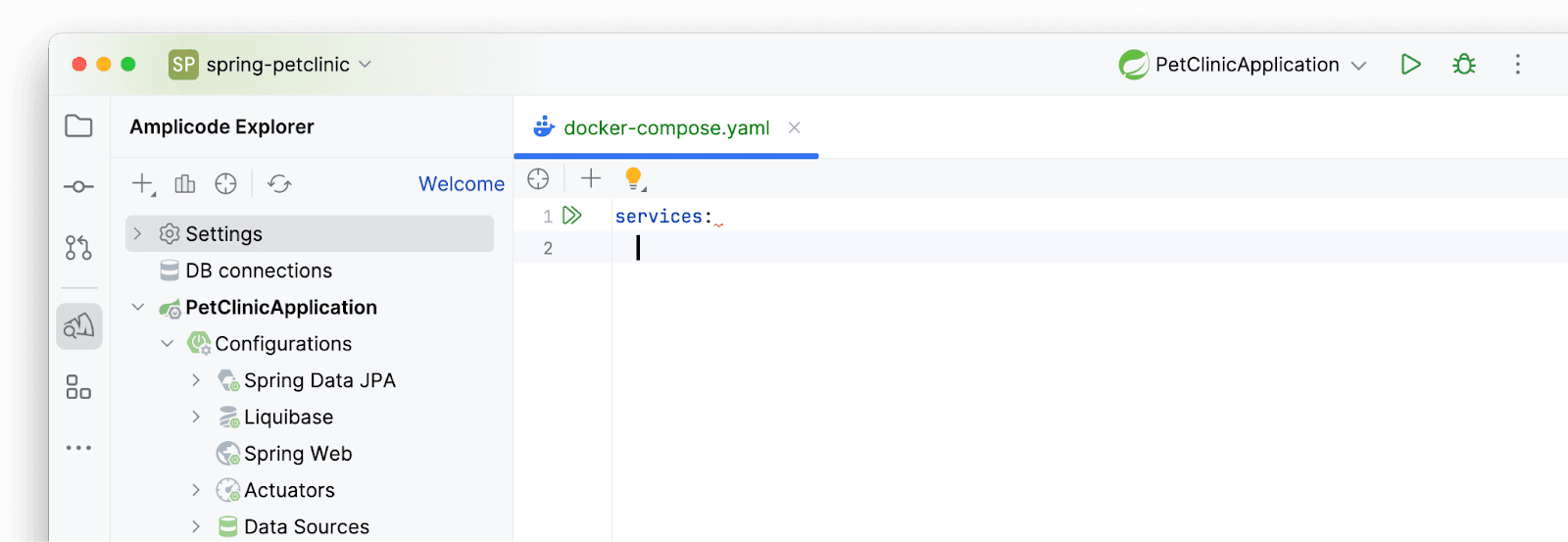
Amplicode знает, что в нашем проекте есть несколько datasource, поэтому предлагает для добавления их конфигурации. Мы будем поднимать PostgreSQL. Нажимаем на лампочку, которая покажет предложения по добавлению:
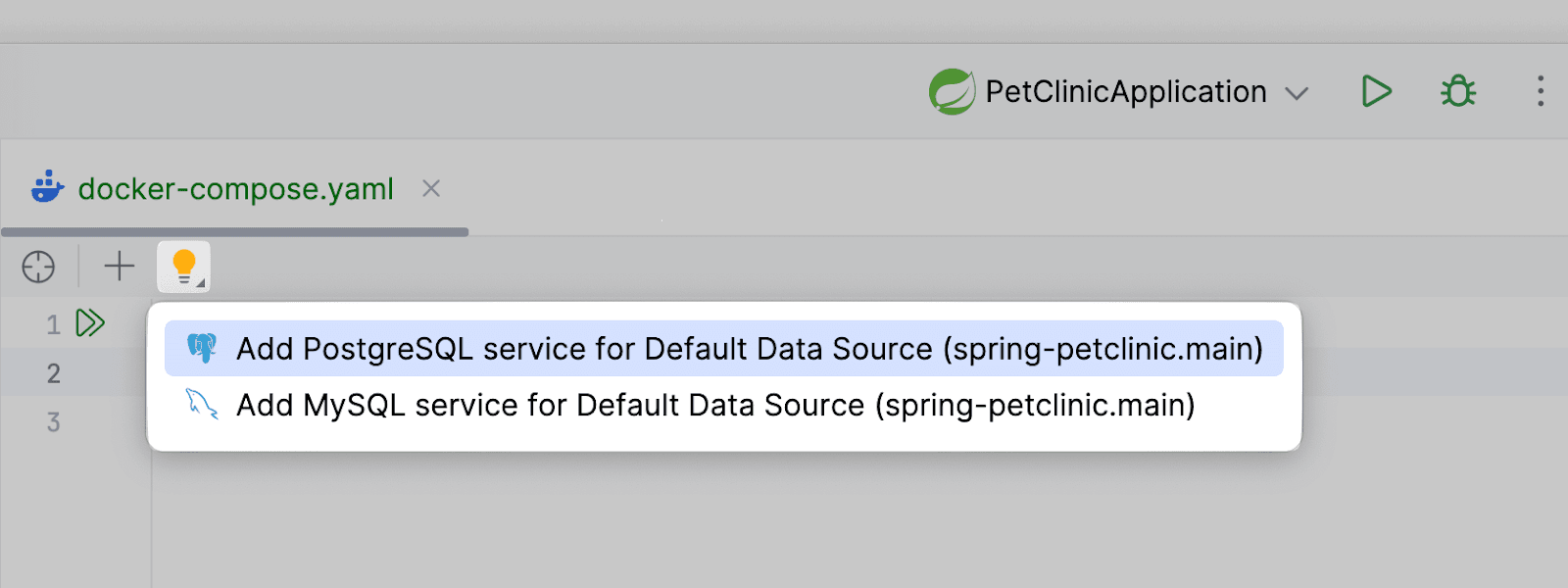
И тут настройки нас тоже вполне удовлетворяют. Amplicode подтянул их из application.properties.
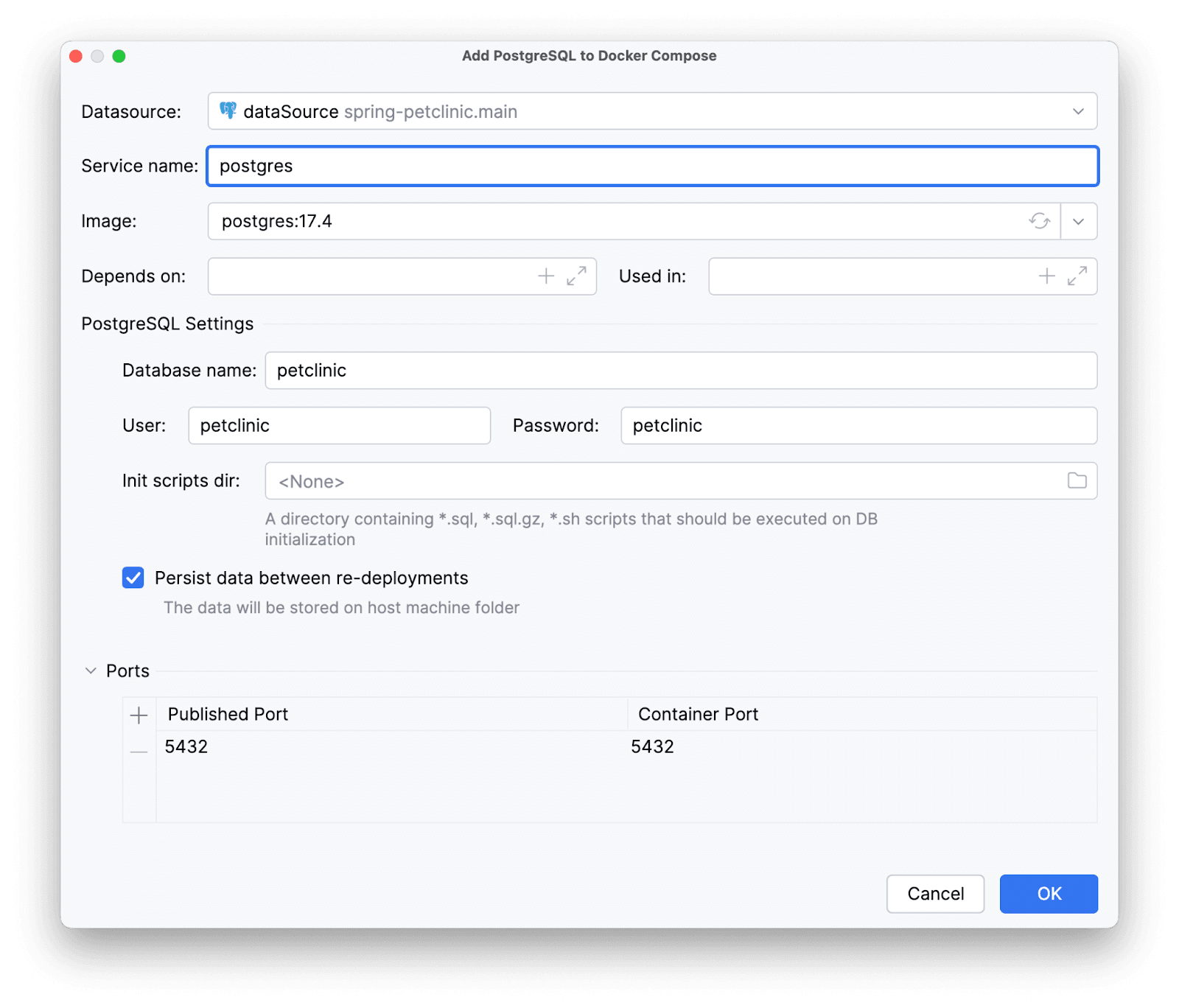
Сервис готов.
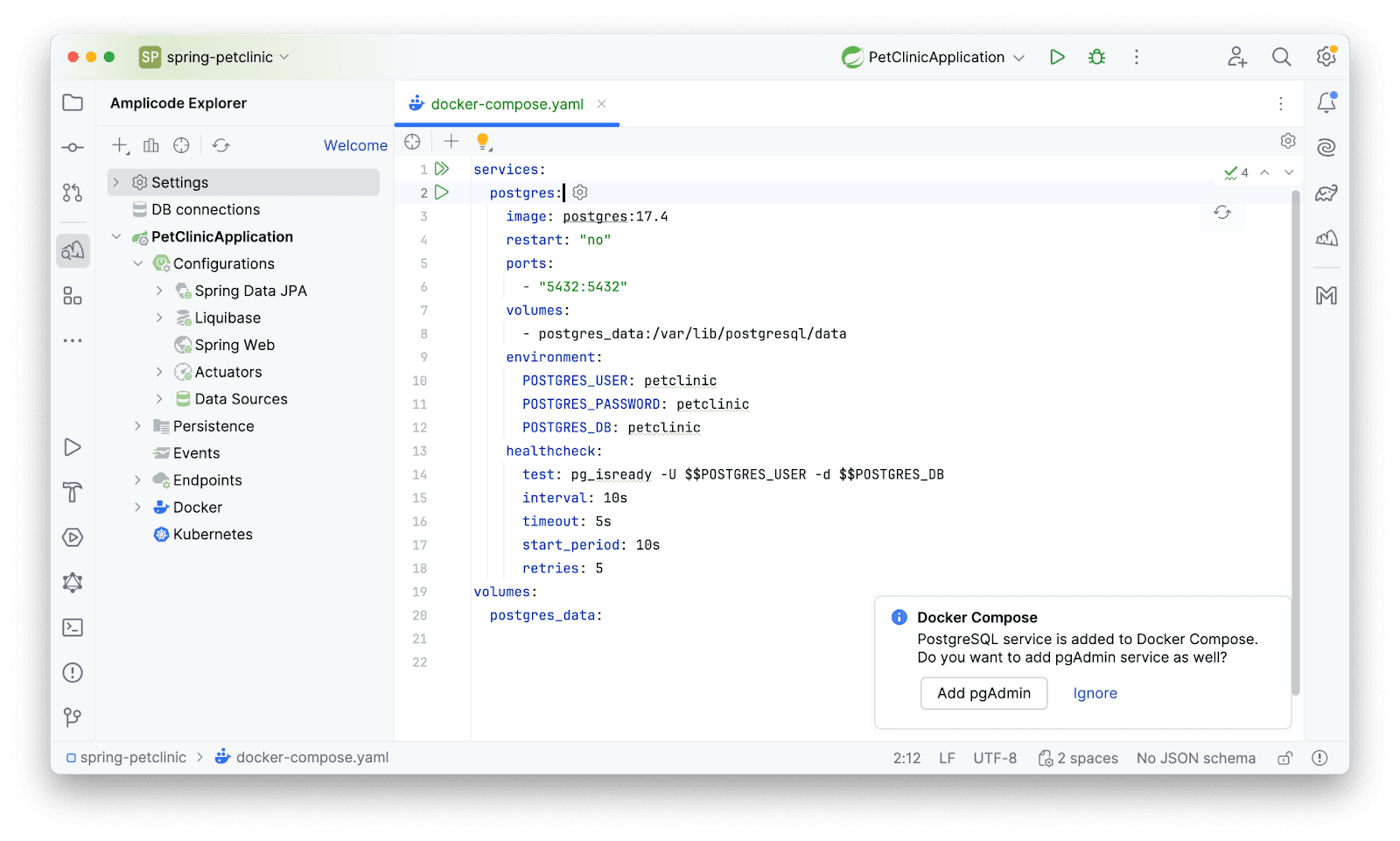
Тут же Amplicode понимает, что нам, возможно, может потребоваться pgAdmin для работы с БД. Воспользуемся его предложением и добавим сервис.
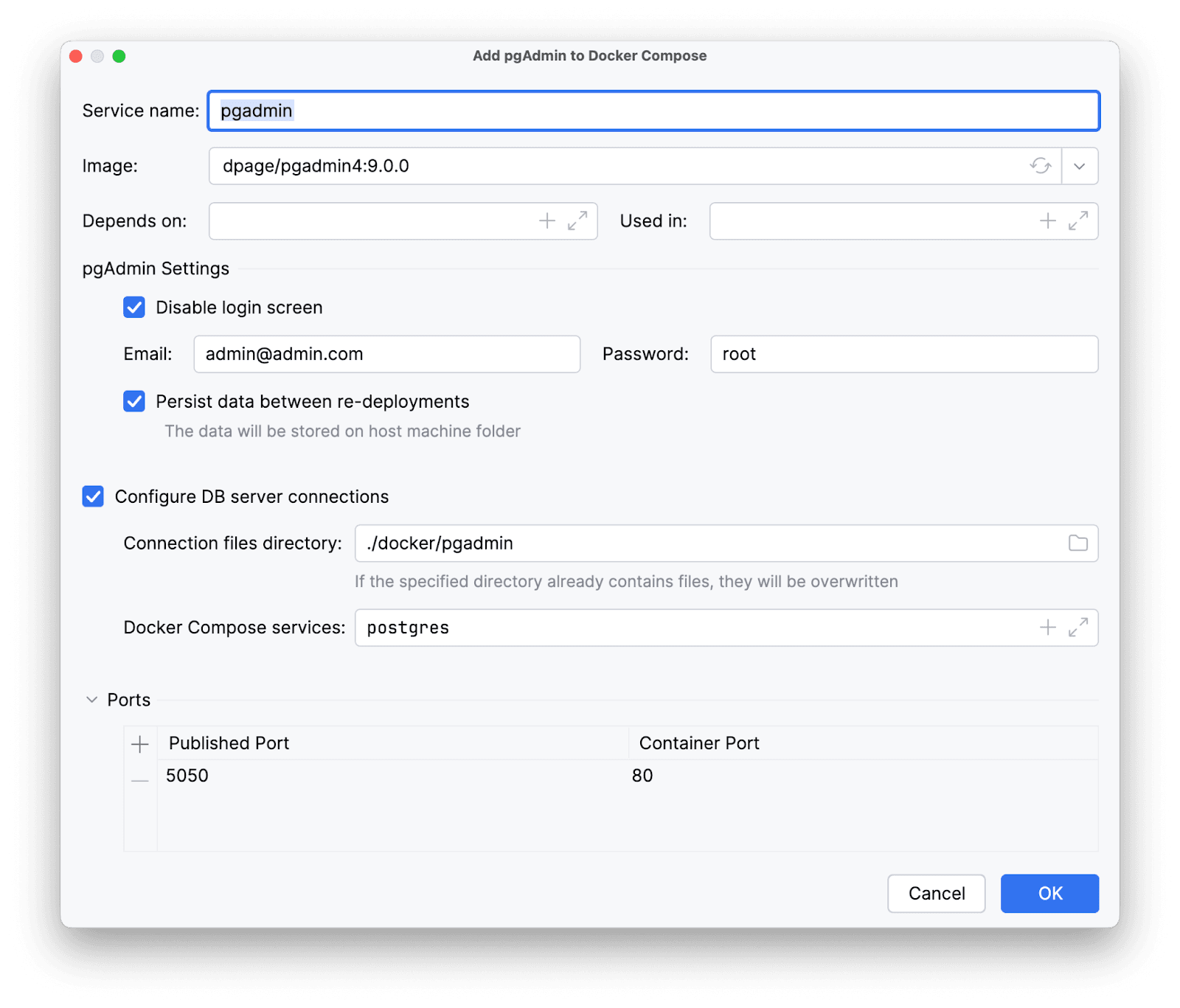
Что-ж, остается только лишь убедиться в работоспособности. Запустим сервисы с помощью соответствующих gutter-icon'ов. Для запуска всех сервисов нажмем на иконку с несколькими стрелками:
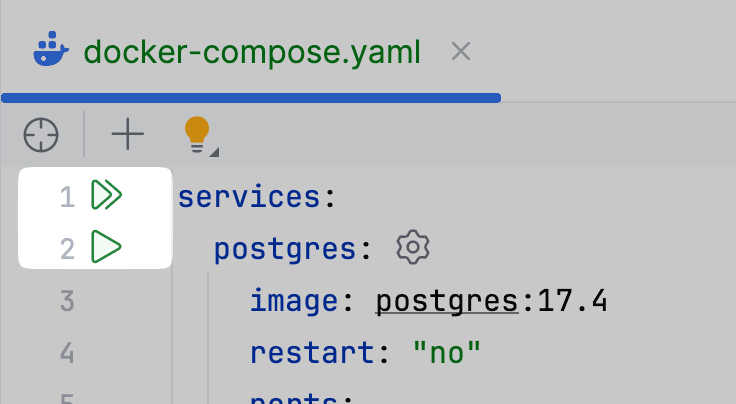
Сервисы успешно запущены:
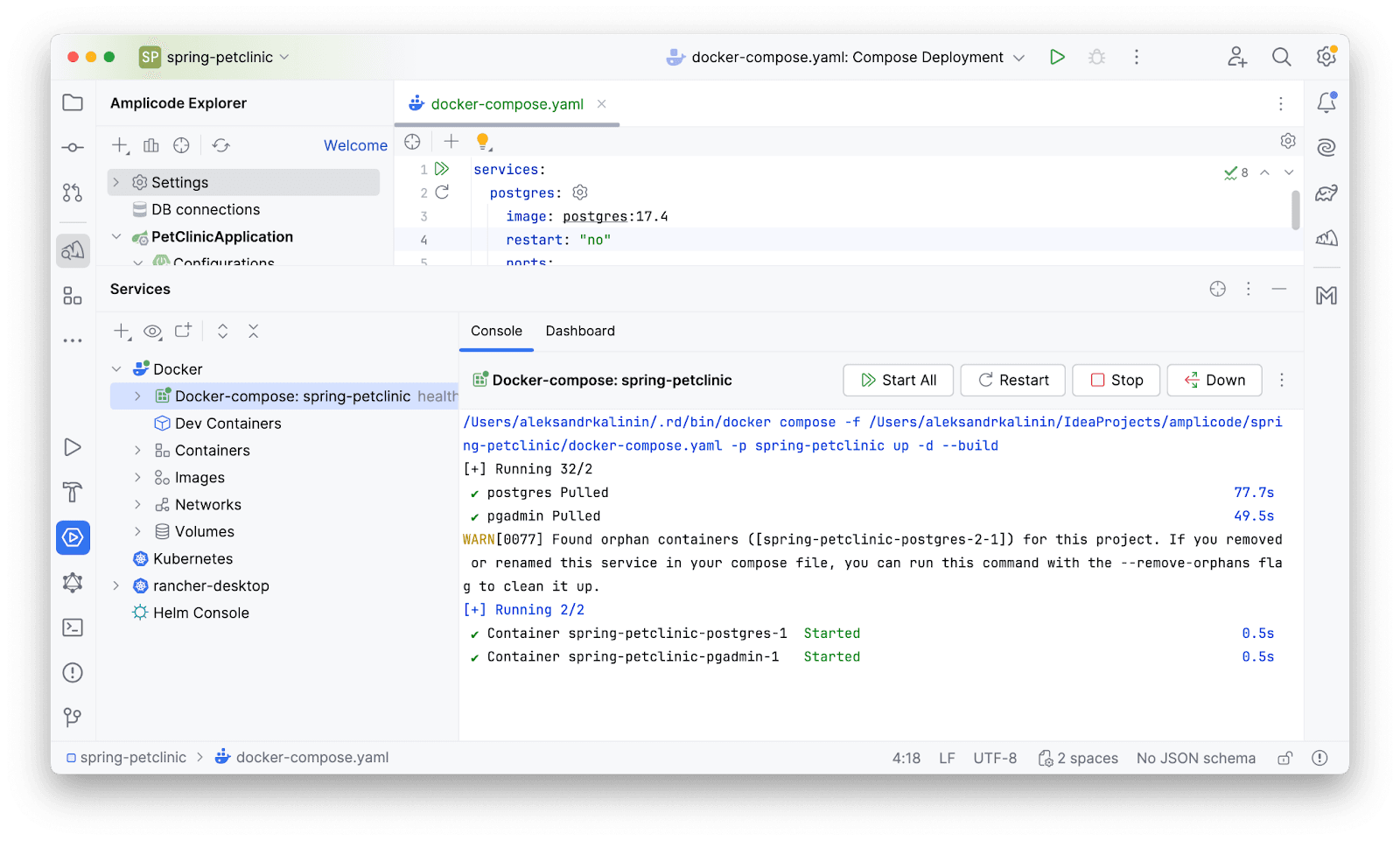
Прямо из docker-compose.yaml файла мы можем снавигироваться в браузер к url с pgAdmin:
Видим, что пока что табличек в нашей БД нет. Оно и верно, ведь мы еще не запускали наше приложение, во время чего могли бы прогнаться init-скрипты:
Запустим приложение. Нажмем ПКМ по названию проекта из панели Amplicode Explorer:
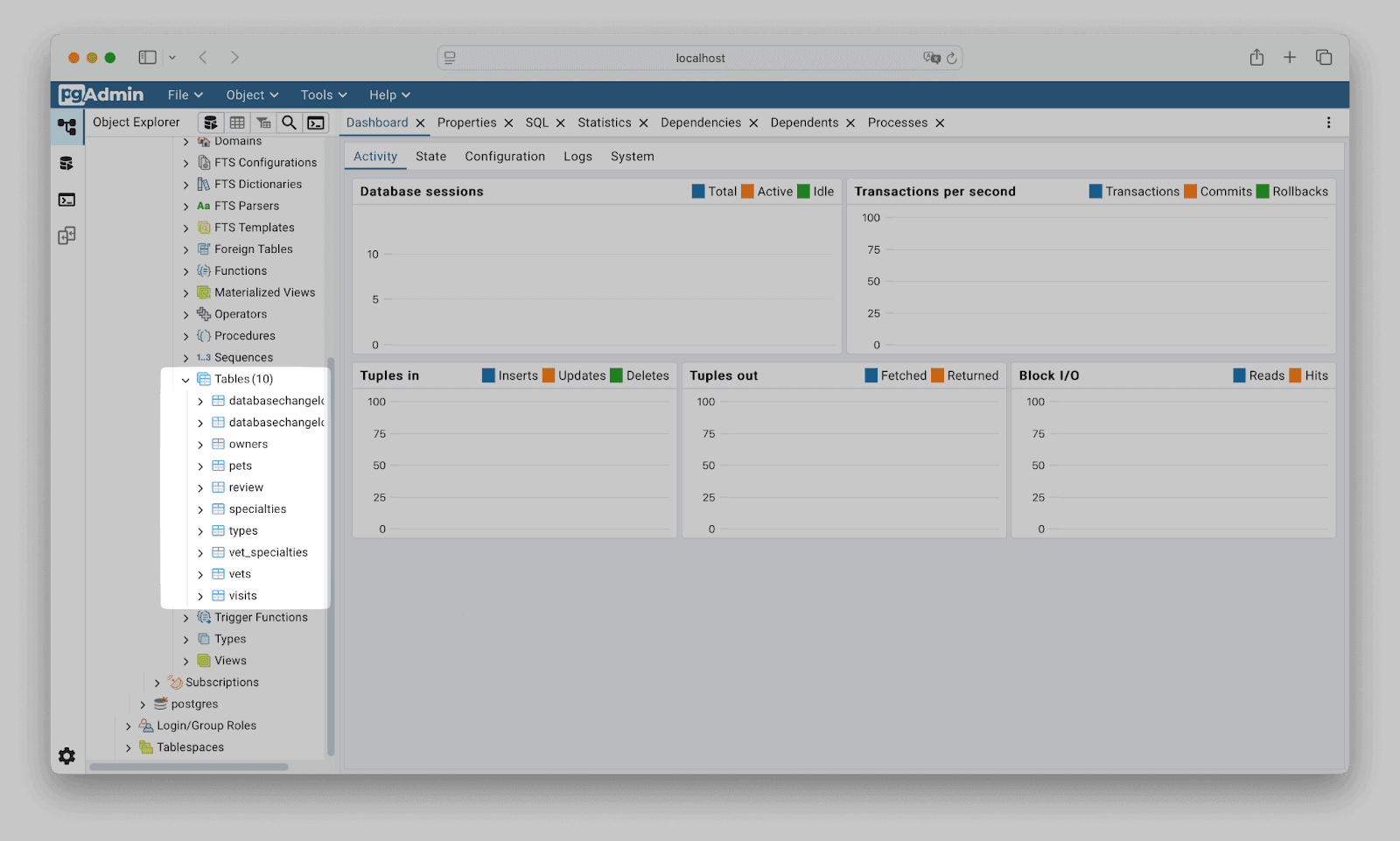
Приложение запустилось, скрипты успешно накатились. В базе видим, что таблички появились.
Но как же быть в случае, если наша модель подверглась доработке и теперь нам требуется апдейт в БД? Для этого существуют Diff-скрипты и Amplicode в них тоже умеет. Для эксперимента добавим новый обязательный базовый атрибут в сущность Review.
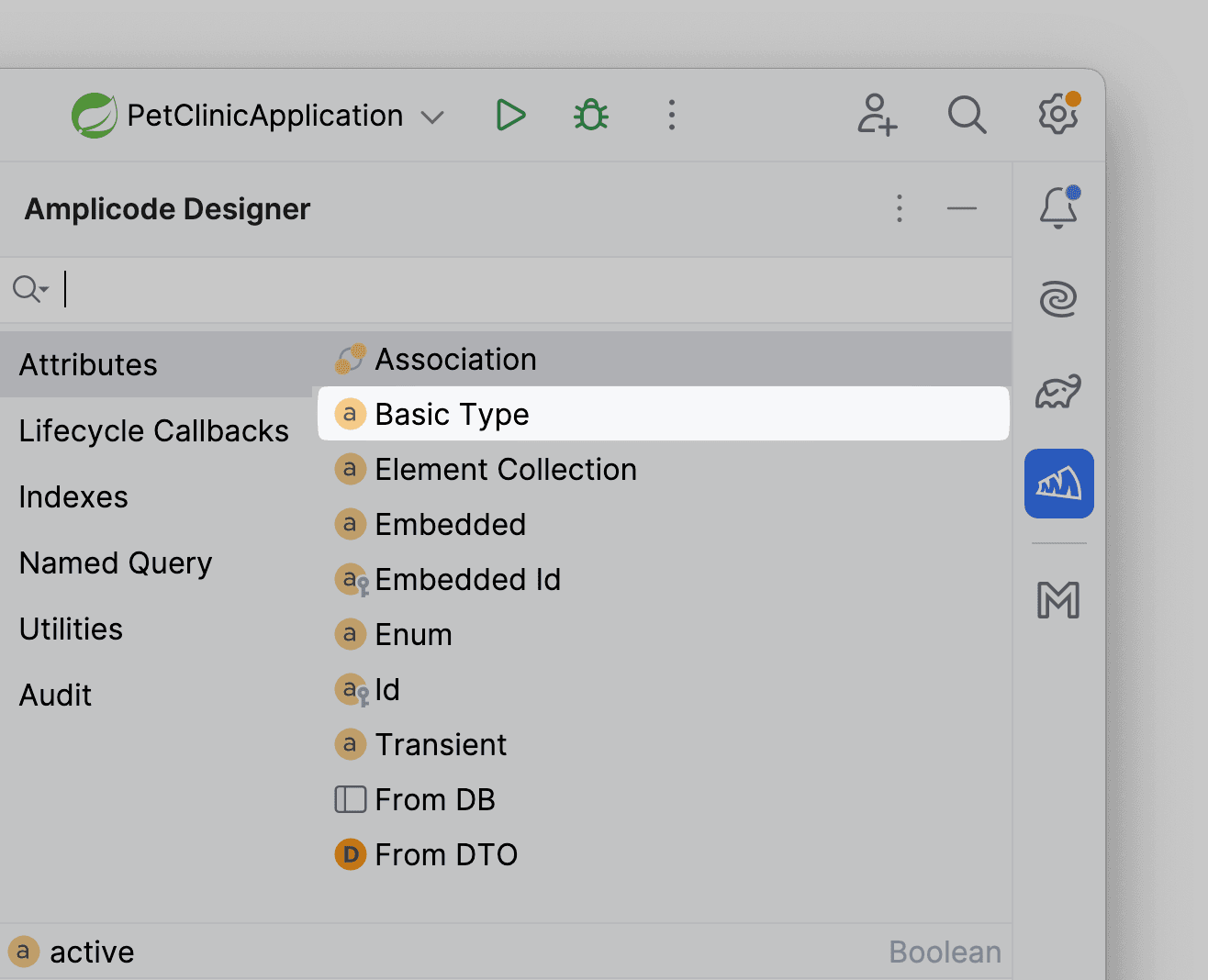
Пусть это будет некий флаг, что отзыв актуален, не удален:
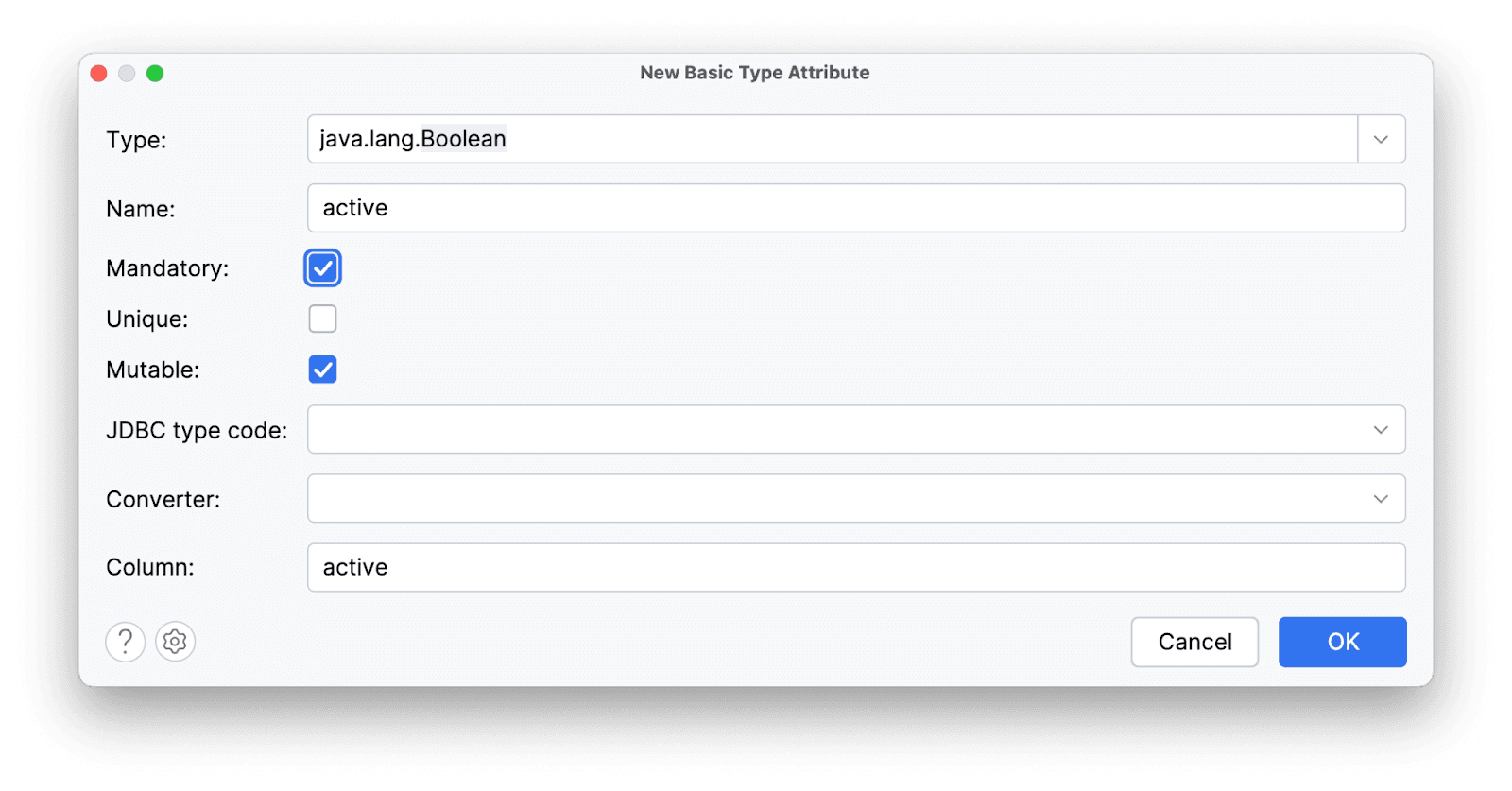
Получаем поле:
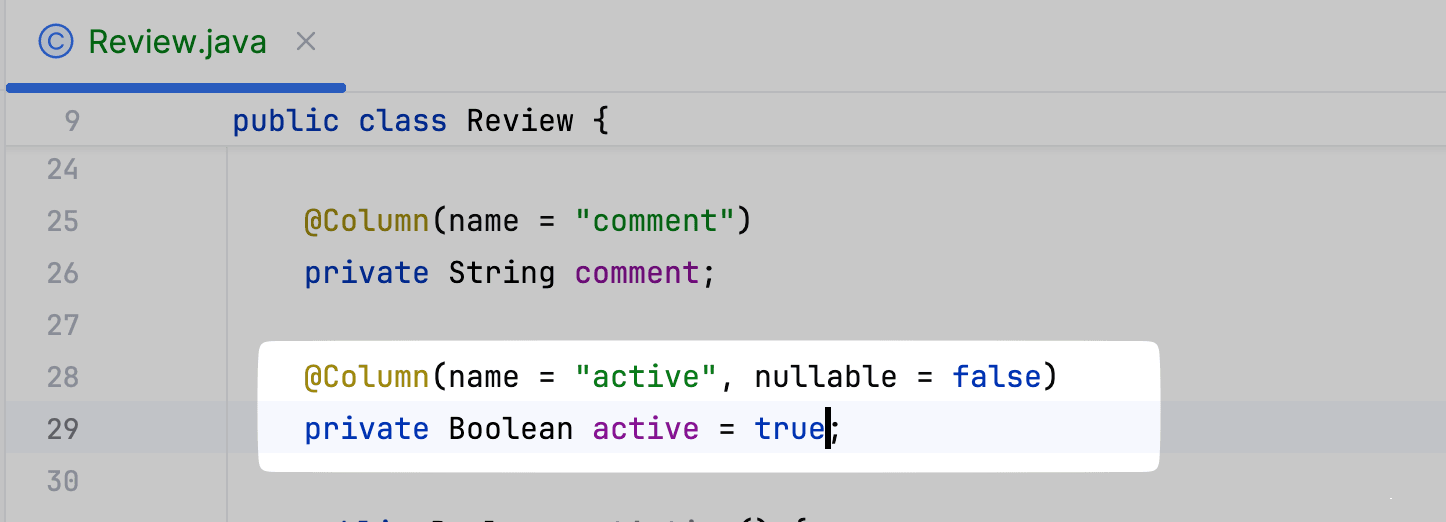
Теперь, конечно же, при запуске приложения мы получим:
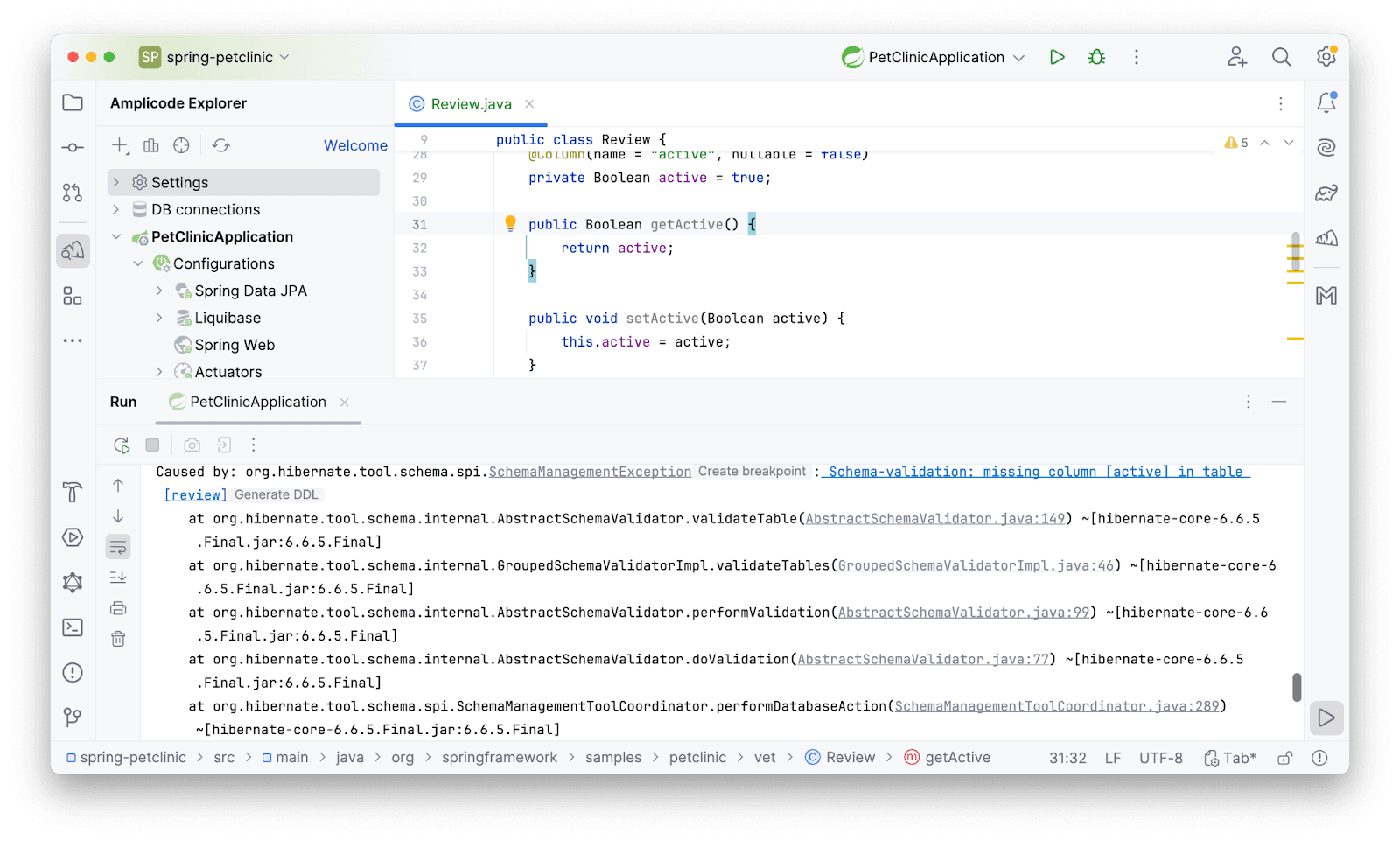
Так как параметр spring.jpa.hibernate.ddl-auto имеет значение validate:

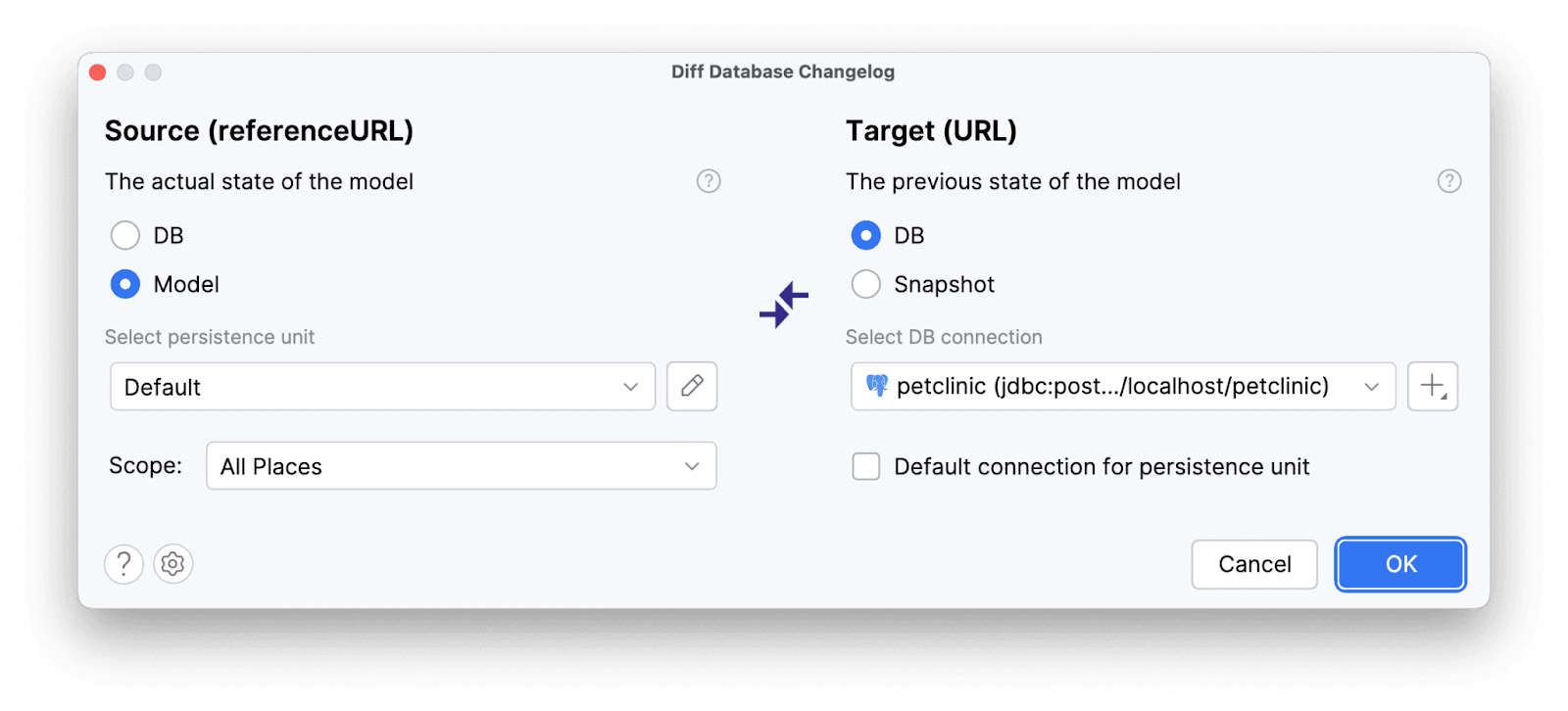
Теперь уступим дорогу Amplicode. Сгенерируем тот самый diff-скрипт:
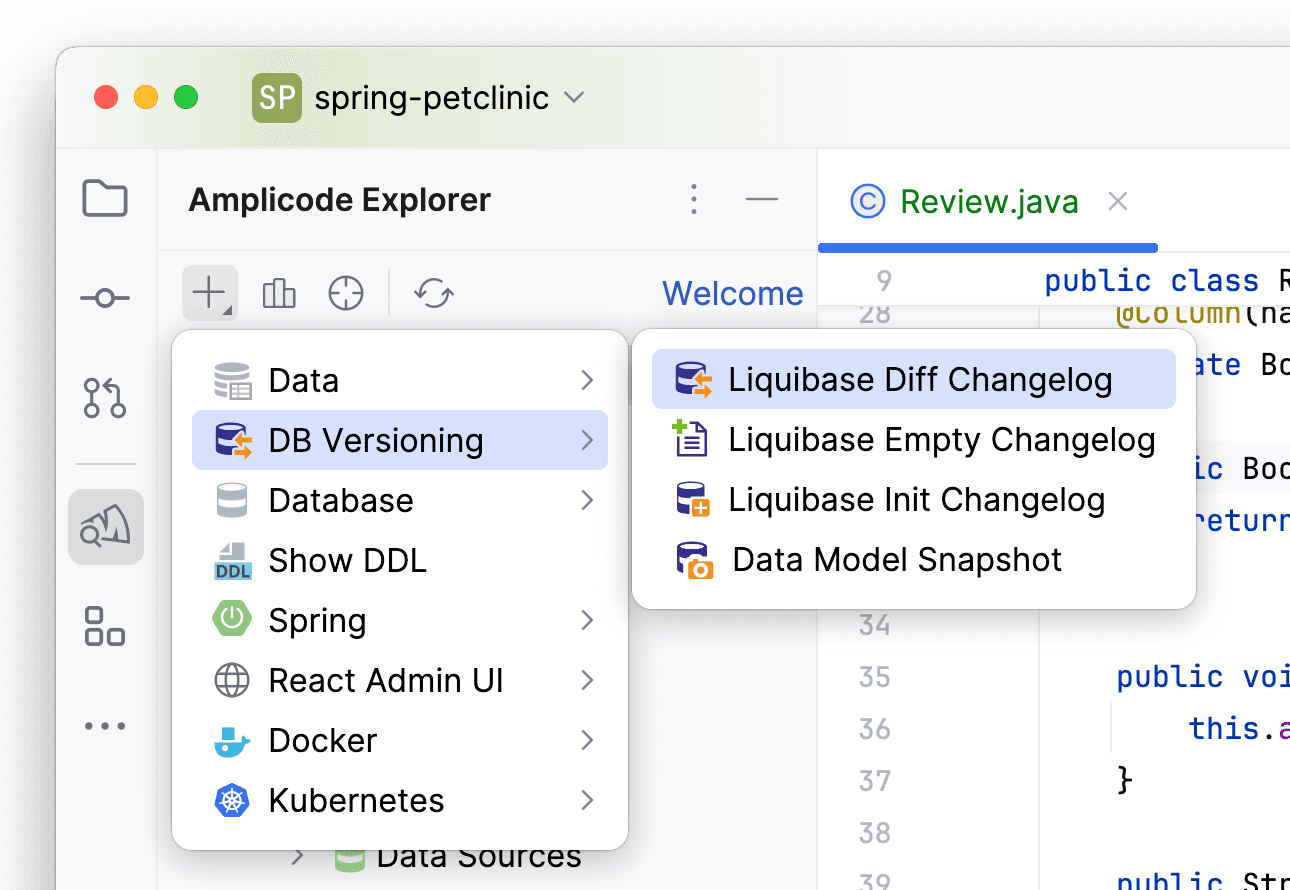
Создадим DB Connection:
В качестве Target укажем Connection к нашей БД:
В окне превью мы можем ознакомиться с нашим скриптом, в котором учтено свежедобавленное в сущность поле:
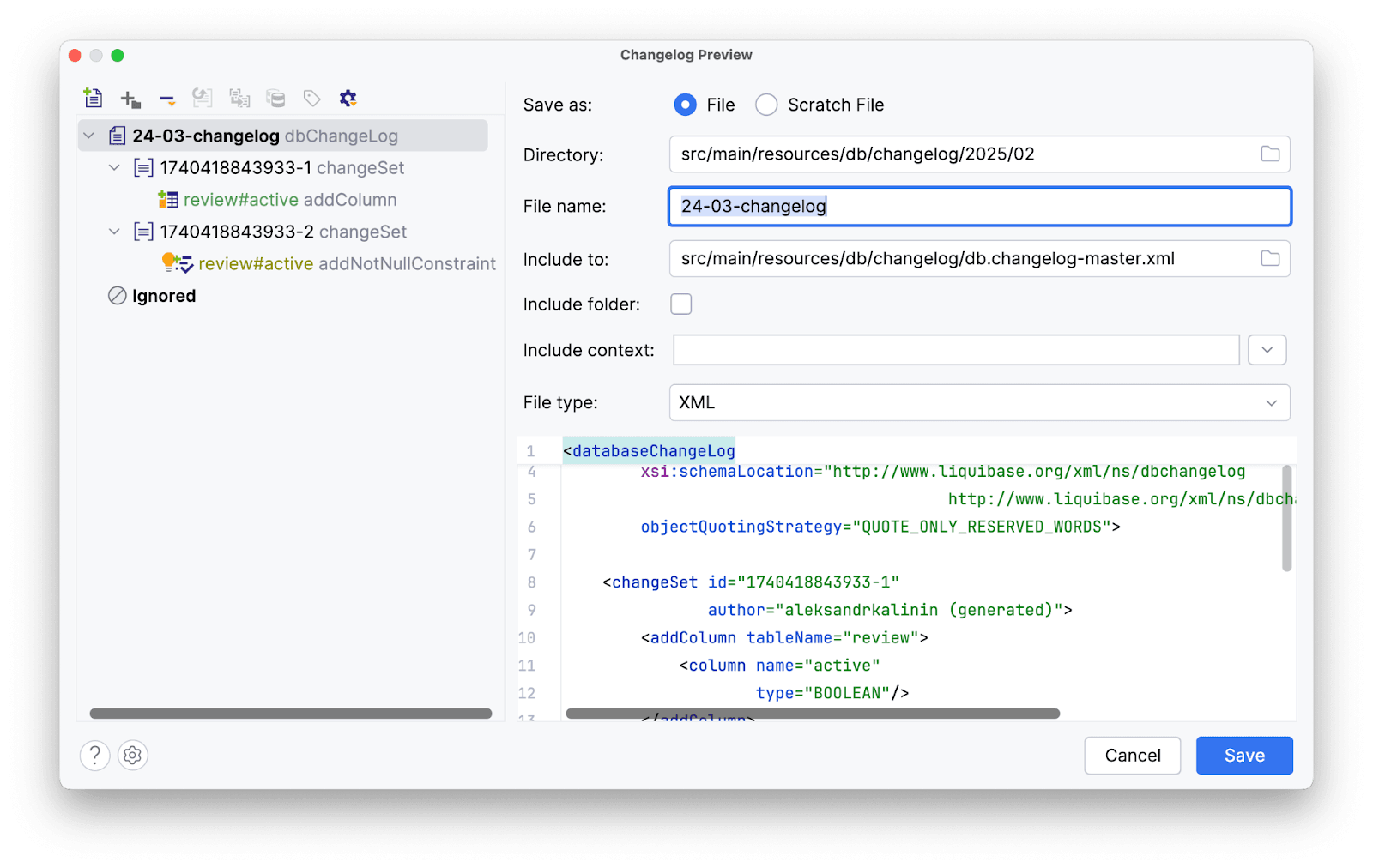
Сохраняем и получаем скрипт:
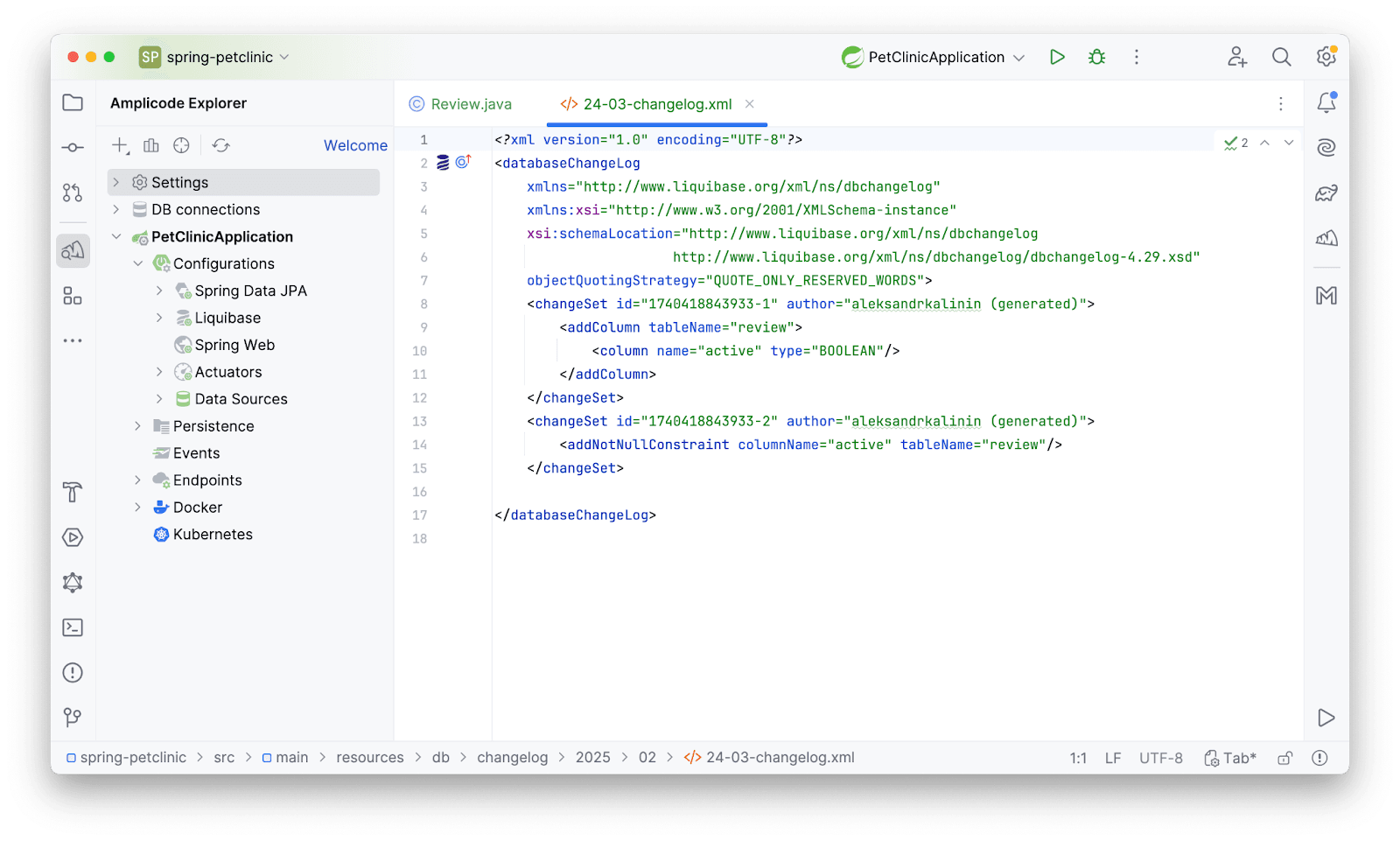
Запустим приложение и убедимся, что все работает:
Итак, всего за несколько шагов с использованием Amplicode мы смогли:
- Получить детальный обзор структуры Spring Boot проекта и настроек, не открывая ни одного файла.
- Добавить новый домен, сгенерировав все необходимые классы сущности, репозиторий, DTO и даже кастомные методы, избавившись от ручного написания boilerplate кода.
- Создать тесты для нового REST-контроллера.
- Доработать существующую бизнес-логику.
- Настроить систему версионирования базы данных
- Создать и сконфигурировать docker-compose файл для поднятия необходимых сервисов, а затем убедиться в успешном развертывании приложения.
Эти шаги демонстрируют, что Amplicode не только существенно упрощает повседневные задачи разработчика, но и расширяет возможности по автоматизации и быстрому внедрению новых функций. И это лишь малая часть того, что умеет плагин, делая разработку более продуктивной и эффективной.
Если у вас возникли сложности или хотели бы поделиться фидбеком с нами - будем рады приветствовать в нашем чате